Loss Symmetry and Noise Equilibrium of Stochastic Gradient Descent
2402.07193
0
0
Abstract
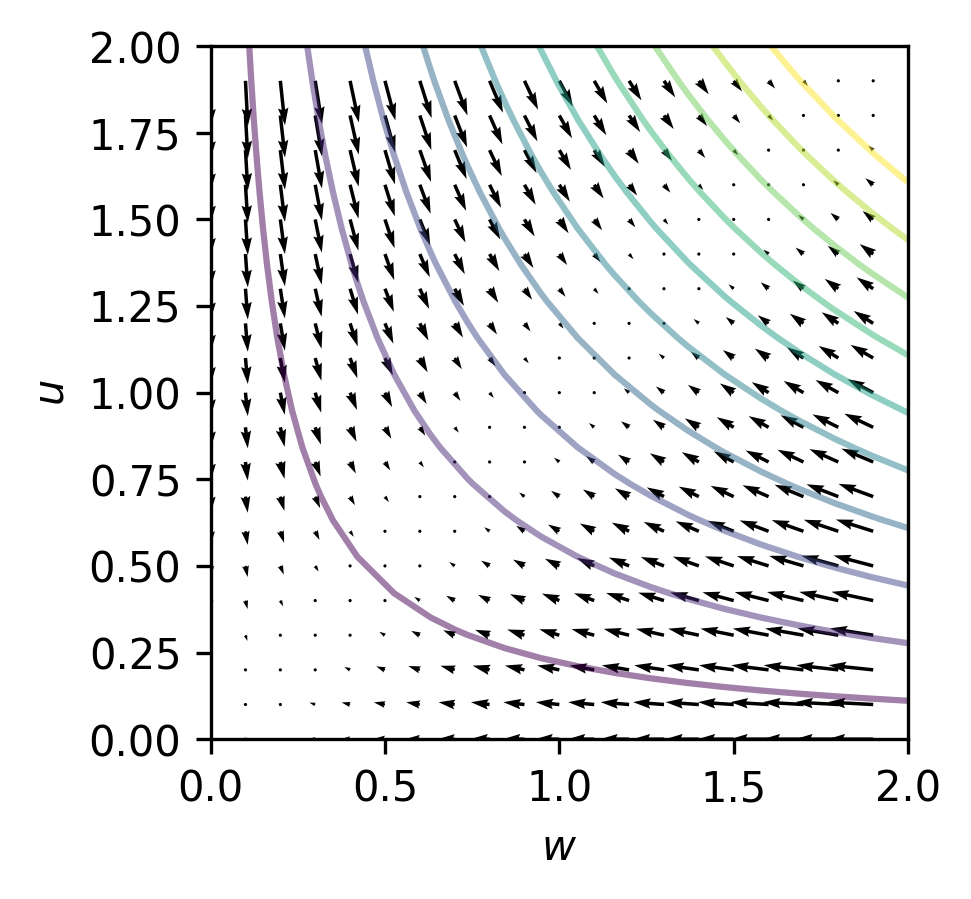
Symmetries exist abundantly in the loss function of neural networks. We characterize the learning dynamics of stochastic gradient descent (SGD) when exponential symmetries, a broad subclass of continuous symmetries, exist in the loss function. We establish that when gradient noises do not balance, SGD has the tendency to move the model parameters toward a point where noises from different directions are balanced. Here, a special type of fixed point in the constant directions of the loss function emerges as a candidate for solutions for SGD. As the main theoretical result, we prove that every parameter $theta$ connects without loss function barrier to a unique noise-balanced fixed point $theta^*$. The theory implies that the balancing of gradient noise can serve as a novel alternative mechanism for relevant phenomena such as progressive sharpening and flattening and can be applied to understand common practical problems such as representation normalization, matrix factorization, warmup, and formation of latent representations.
Create account to get full access
Overview
- The paper explores the implicit biases and symmetry properties of gradient noise in machine learning models.
- It provides a general theoretical framework to analyze the impact of gradient noise on the learning dynamics and convergence of stochastic optimization algorithms like stochastic gradient descent (SGD).
- The analysis reveals that gradient noise can induce specific structural biases in the learned solutions, such as [symmetry-induces-structure-constraint-learning], [stochastic-collapse-how-gradient-noise-attracts-sgd], and [derivatives-stochastic-gradient-descent].
- The findings have implications for understanding the behaviors of deep neural networks, particularly the [exploring-exploiting-asymmetric-valley-deep-neural-networks] and [convergence-rates-stochastic-approximation-biased-noise-unbounded] observed in practice.
Plain English Explanation
The paper looks at how the random noise that is added to the gradients (the slopes of the error function) during training of machine learning models can actually introduce hidden biases in the final learned models.
Imagine you're trying to find the lowest point in a hilly landscape by taking small steps in the downhill direction. If you add a little random noise to the direction of each step, it can actually push you towards certain types of valleys in the landscape, rather than just the lowest point.
Similarly, the random noise added to the gradients during training of neural networks can make the model converge to solutions with specific structural properties, like having certain symmetries. This means the final model may have unexpected biases built into it, just from the random noise in the training process.
The paper develops a general mathematical framework to understand and predict these kinds of implicit biases introduced by gradient noise. This can help us design better training procedures to counteract these biases and learn more unbiased models.
Technical Explanation
The paper provides a [general-theory] to analyze the impact of gradient noise on the learning dynamics and convergence of stochastic optimization algorithms like [derivatives-stochastic-gradient-descent].
The key insight is that gradient noise can induce specific structural biases in the learned solutions, such as:
-
[symmetry-induces-structure-constraint-learning]: Gradient noise can make the model converge to solutions with certain symmetries, even when the original optimization problem does not have those symmetries.
-
[stochastic-collapse-how-gradient-noise-attracts-sgd]: Gradient noise can cause the model to collapse onto a low-dimensional subspace, leading to solutions with reduced expressivity.
-
[exploring-exploiting-asymmetric-valley-deep-neural-networks]: Gradient noise can make the model get trapped in asymmetric valleys of the optimization landscape, leading to suboptimal solutions.
The paper develops a theoretical framework to characterize these phenomena, providing insights into the [convergence-rates-stochastic-approximation-biased-noise-unbounded] of stochastic optimization under gradient noise.
Critical Analysis
The paper provides a rigorous theoretical analysis of the implicit biases introduced by gradient noise, which is an important and often overlooked aspect of stochastic optimization in machine learning.
However, the analysis is primarily focused on linear models and quadratic objectives, and the authors acknowledge that extending the results to more complex nonlinear models and objective functions remains a challenge.
Additionally, the paper does not address the potential interactions between gradient noise and other optimization techniques, such as adaptive learning rates or momentum. These factors could further influence the structural biases in the learned models.
It would be valuable for future research to explore the implications of these findings for the training and interpretation of deep neural networks, which often exhibit complex optimization landscapes and utilize various techniques beyond basic SGD.
Conclusion
This paper offers a novel symmetry-based perspective on the implicit biases introduced by gradient noise in stochastic optimization. The theoretical framework provides important insights into how random noise in the gradients can lead to specific structural properties in the learned models, such as symmetries, low-dimensional subspaces, and asymmetric valleys.
These findings have significant implications for understanding the behaviors of deep neural networks and developing more robust and unbiased learning algorithms. By accounting for the symmetry-inducing effects of gradient noise, researchers and practitioners can design better training procedures to mitigate these implicit biases and learn more reliable and interpretable models.
Overall, this work represents an important step towards a deeper understanding of the fundamental mechanisms underlying stochastic optimization in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Symmetry Induces Structure and Constraint of Learning
Liu Ziyin
0
0
Due to common architecture designs, symmetries exist extensively in contemporary neural networks. In this work, we unveil the importance of the loss function symmetries in affecting, if not deciding, the learning behavior of machine learning models. We prove that every mirror-reflection symmetry, with reflection surface $O$, in the loss function leads to the emergence of a constraint on the model parameters $theta$: $O^Ttheta =0$. This constrained solution becomes satisfied when either the weight decay or gradient noise is large. Common instances of mirror symmetries in deep learning include rescaling, rotation, and permutation symmetry. As direct corollaries, we show that rescaling symmetry leads to sparsity, rotation symmetry leads to low rankness, and permutation symmetry leads to homogeneous ensembling. Then, we show that the theoretical framework can explain intriguing phenomena, such as the loss of plasticity and various collapse phenomena in neural networks, and suggest how symmetries can be used to design an elegant algorithm to enforce hard constraints in a differentiable way.
6/4/2024
🔗
Stochastic Collapse: How Gradient Noise Attracts SGD Dynamics Towards Simpler Subnetworks
Feng Chen, Daniel Kunin, Atsushi Yamamura, Surya Ganguli
0
0
In this work, we reveal a strong implicit bias of stochastic gradient descent (SGD) that drives overly expressive networks to much simpler subnetworks, thereby dramatically reducing the number of independent parameters, and improving generalization. To reveal this bias, we identify invariant sets, or subsets of parameter space that remain unmodified by SGD. We focus on two classes of invariant sets that correspond to simpler (sparse or low-rank) subnetworks and commonly appear in modern architectures. Our analysis uncovers that SGD exhibits a property of stochastic attractivity towards these simpler invariant sets. We establish a sufficient condition for stochastic attractivity based on a competition between the loss landscape's curvature around the invariant set and the noise introduced by stochastic gradients. Remarkably, we find that an increased level of noise strengthens attractivity, leading to the emergence of attractive invariant sets associated with saddle-points or local maxima of the train loss. We observe empirically the existence of attractive invariant sets in trained deep neural networks, implying that SGD dynamics often collapses to simple subnetworks with either vanishing or redundant neurons. We further demonstrate how this simplifying process of stochastic collapse benefits generalization in a linear teacher-student framework. Finally, through this analysis, we mechanistically explain why early training with large learning rates for extended periods benefits subsequent generalization.
5/30/2024
🤿
Exploring and Exploiting the Asymmetric Valley of Deep Neural Networks
Xin-Chun Li, Jin-Lin Tang, Bo Zhang, Lan Li, De-Chuan Zhan
0
0
Exploring the loss landscape offers insights into the inherent principles of deep neural networks (DNNs). Recent work suggests an additional asymmetry of the valley beyond the flat and sharp ones, yet without thoroughly examining its causes or implications. Our study methodically explores the factors affecting the symmetry of DNN valleys, encompassing (1) the dataset, network architecture, initialization, and hyperparameters that influence the convergence point; and (2) the magnitude and direction of the noise for 1D visualization. Our major observation shows that the {it degree of sign consistency} between the noise and the convergence point is a critical indicator of valley symmetry. Theoretical insights from the aspects of ReLU activation and softmax function could explain the interesting phenomenon. Our discovery propels novel understanding and applications in the scenario of Model Fusion: (1) the efficacy of interpolating separate models significantly correlates with their sign consistency ratio, and (2) imposing sign alignment during federated learning emerges as an innovative approach for model parameter alignment.
7/2/2024
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
0
0
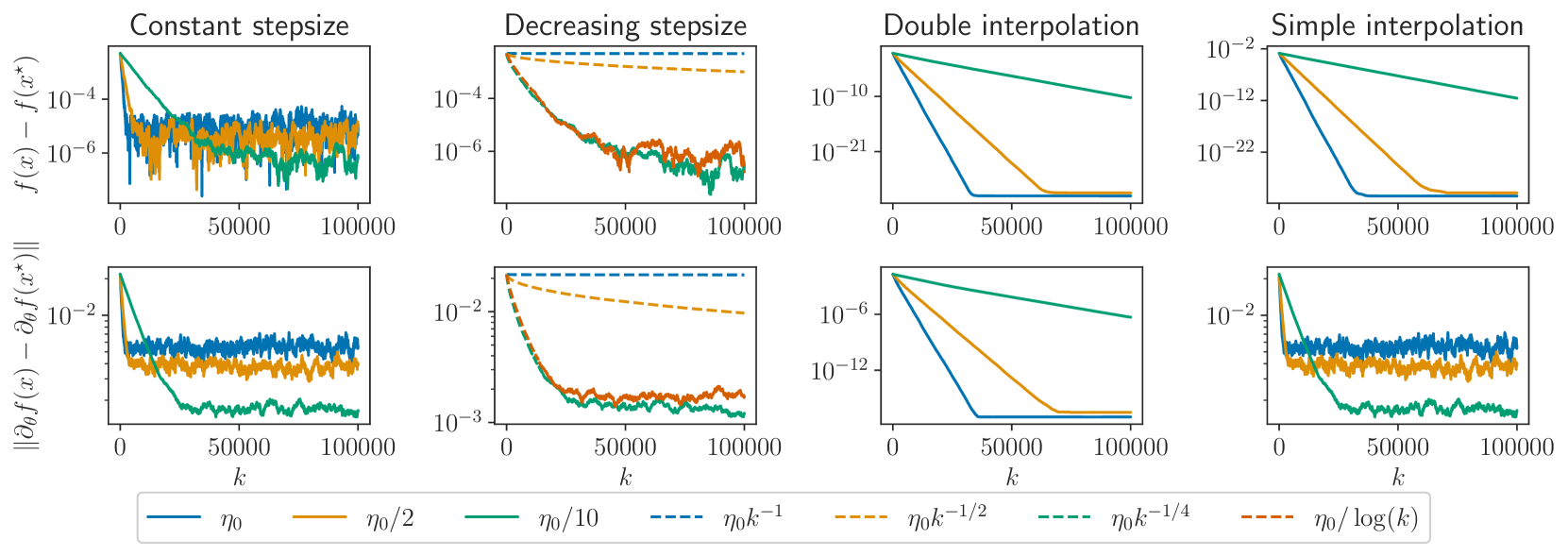
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
5/28/2024