The Lost Melody: Empirical Observations on Text-to-Video Generation From A Storytelling Perspective
2405.08720
0
0
Abstract
Text-to-video generation task has witnessed a notable progress, with the generated outcomes reflecting the text prompts with high fidelity and impressive visual qualities. However, current text-to-video generation models are invariably focused on conveying the visual elements of a single scene, and have so far been indifferent to another important potential of the medium, namely a storytelling. In this paper, we examine text-to-video generation from a storytelling perspective, which has been hardly investigated, and make empirical remarks that spotlight the limitations of current text-to-video generation scheme. We also propose an evaluation framework for storytelling aspects of videos, and discuss the potential future directions.
Create account to get full access
Overview
- This paper explores the challenges and opportunities of text-to-video generation from a storytelling perspective.
- The authors present empirical observations and insights gained from developing a text-to-video generation system.
- Key focus areas include narrative structure, visual coherence, and expressive capabilities required for compelling storytelling.
- The findings have implications for advancing the state-of-the-art in text-to-video generation and enhancing the narrative quality of generated videos.
Plain English Explanation
The paper discusses the challenges of creating videos from text, particularly when the goal is to tell an engaging story. The authors have developed a system that can generate videos based on text inputs, and they share their observations and insights from this process.
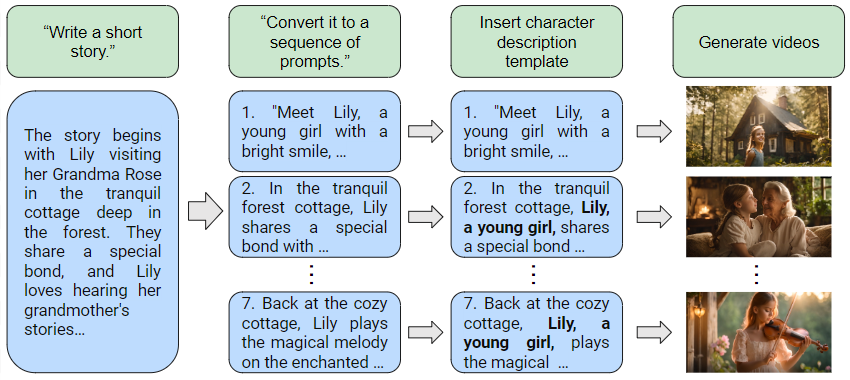
One key focus is the narrative structure of the generated videos. To create a compelling story, the system needs to understand and capture elements like plot, character development, and thematic coherence. This is a significant technical challenge compared to simpler tasks like generating videos to illustrate individual concepts or events.
The authors also emphasize the importance of visual coherence. The video frames need to flow logically and seamlessly, without jarring transitions or inconsistencies that would disrupt the viewer's experience. Achieving this level of visual fluidity requires advanced computer vision and video generation capabilities.
Another critical aspect is the system's expressive capabilities. To bring a story to life, the generated videos need to convey emotions, subtleties, and nuances that align with the narrative. This goes beyond just mechanically illustrating the text and requires a deeper understanding of human storytelling.
Overall, the findings from this research provide valuable insights for advancing text-to-video generation technology and improving the narrative quality of generated videos. By addressing the challenges identified, researchers and developers can work towards more engaging and immersive storytelling experiences powered by AI.
Technical Explanation
The paper presents empirical observations and insights gained from developing a text-to-video generation system with a focus on storytelling. The authors highlight key challenges and requirements for creating compelling narratives through generated videos.
One core challenge is capturing the narrative structure of the story, including elements like plot, character development, and thematic coherence. Generating videos that maintain a cohesive and engaging narrative arc requires more sophistication than simply illustrating individual concepts or events.
Visual coherence is another critical factor. The generated video frames need to flow logically and seamlessly, without jarring transitions or inconsistencies that would disrupt the viewer's experience. Achieving this level of visual fluidity necessitates advanced computer vision and video generation capabilities.
The authors also emphasize the importance of expressive capabilities, which go beyond simply illustrating the text. To bring a story to life, the generated videos need to convey emotions, subtleties, and nuances that align with the narrative. This requires a deeper understanding of human storytelling and the ability to imbue the generated content with these expressive qualities.
The findings from this research provide valuable insights for advancing text-to-video generation technology and improving the narrative quality of generated videos. By addressing the identified challenges, researchers and developers can work towards more engaging and immersive storytelling experiences powered by AI.
Critical Analysis
The paper presents a thoughtful exploration of the challenges and requirements for text-to-video generation from a storytelling perspective. The authors acknowledge the significant technical hurdles involved in capturing narrative structure, maintaining visual coherence, and imbuing generated videos with expressive qualities.
One potential limitation, as mentioned in the paper, is the reliance on human-authored text as the input for the system. While this allows for the exploration of storytelling-focused generation, it also means the system's capabilities are inherently constrained by the quality and expressiveness of the provided text. Exploring methods for generating text and video in a more integrated, co-creative manner could be an area for further research.
Additionally, the paper does not delve deeply into the specific architectural choices, training approaches, or evaluation metrics used in the authors' text-to-video generation system. A more detailed technical discussion of these aspects could provide valuable insights for other researchers working in this domain.
Despite these potential limitations, the paper's focus on the narrative and expressive aspects of text-to-video generation is a valuable contribution to the field. By highlighting the unique challenges and requirements for storytelling-focused video generation, the authors have laid the groundwork for future advancements in this area.
Conclusion
This paper offers a thoughtful examination of the challenges and opportunities in text-to-video generation from a storytelling perspective. The authors present empirical observations and insights gained from developing a system that can generate videos based on textual inputs.
The key challenges identified include capturing narrative structure, maintaining visual coherence, and imbuing the generated videos with expressive qualities that align with the story. Addressing these challenges is crucial for advancing the state-of-the-art in text-to-video generation and creating more engaging and immersive storytelling experiences powered by AI.
The findings from this research have implications for a wide range of applications, from interactive entertainment to educational content creation. By continuing to explore the narrative and expressive dimensions of text-to-video generation, researchers and developers can work towards more compelling and impactful AI-generated multimedia experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Synchronized Video Storytelling: Generating Video Narrations with Structured Storyline
Dingyi Yang, Chunru Zhan, Ziheng Wang, Biao Wang, Tiezheng Ge, Bo Zheng, Qin Jin
0
0
Video storytelling is engaging multimedia content that utilizes video and its accompanying narration to attract the audience, where a key challenge is creating narrations for recorded visual scenes. Previous studies on dense video captioning and video story generation have made some progress. However, in practical applications, we typically require synchronized narrations for ongoing visual scenes. In this work, we introduce a new task of Synchronized Video Storytelling, which aims to generate synchronous and informative narrations for videos. These narrations, associated with each video clip, should relate to the visual content, integrate relevant knowledge, and have an appropriate word count corresponding to the clip's duration. Specifically, a structured storyline is beneficial to guide the generation process, ensuring coherence and integrity. To support the exploration of this task, we introduce a new benchmark dataset E-SyncVidStory with rich annotations. Since existing Multimodal LLMs are not effective in addressing this task in one-shot or few-shot settings, we propose a framework named VideoNarrator that can generate a storyline for input videos and simultaneously generate narrations with the guidance of the generated or predefined storyline. We further introduce a set of evaluation metrics to thoroughly assess the generation. Both automatic and human evaluations validate the effectiveness of our approach. Our dataset, codes, and evaluations will be released.
5/24/2024

TC-Bench: Benchmarking Temporal Compositionality in Text-to-Video and Image-to-Video Generation
Weixi Feng, Jiachen Li, Michael Saxon, Tsu-jui Fu, Wenhu Chen, William Yang Wang
0
0
Video generation has many unique challenges beyond those of image generation. The temporal dimension introduces extensive possible variations across frames, over which consistency and continuity may be violated. In this study, we move beyond evaluating simple actions and argue that generated videos should incorporate the emergence of new concepts and their relation transitions like in real-world videos as time progresses. To assess the Temporal Compositionality of video generation models, we propose TC-Bench, a benchmark of meticulously crafted text prompts, corresponding ground truth videos, and robust evaluation metrics. The prompts articulate the initial and final states of scenes, effectively reducing ambiguities for frame development and simplifying the assessment of transition completion. In addition, by collecting aligned real-world videos corresponding to the prompts, we expand TC-Bench's applicability from text-conditional models to image-conditional ones that can perform generative frame interpolation. We also develop new metrics to measure the completeness of component transitions in generated videos, which demonstrate significantly higher correlations with human judgments than existing metrics. Our comprehensive experimental results reveal that most video generators achieve less than 20% of the compositional changes, highlighting enormous space for future improvement. Our analysis indicates that current video generation models struggle to interpret descriptions of compositional changes and synthesize various components across different time steps.
6/14/2024

Movie101v2: Improved Movie Narration Benchmark
Zihao Yue, Yepeng Zhang, Ziheng Wang, Qin Jin
0
0
Automatic movie narration targets at creating video-aligned plot descriptions to assist visually impaired audiences. It differs from standard video captioning in that it requires not only describing key visual details but also inferring the plots developed across multiple movie shots, thus posing unique and ongoing challenges. To advance the development of automatic movie narrating systems, we first revisit the limitations of existing datasets and develop a large-scale, bilingual movie narration dataset, Movie101v2. Second, taking into account the essential difficulties in achieving applicable movie narration, we break the long-term goal into three progressive stages and tentatively focus on the initial stages featuring understanding within individual clips. We also introduce a new narration assessment to align with our staged task goals. Third, using our new dataset, we baseline several leading large vision-language models, including GPT-4V, and conduct in-depth investigations into the challenges current models face for movie narration generation. Our findings reveal that achieving applicable movie narration generation is a fascinating goal that requires thorough research.
4/23/2024
New!Evaluation of Text-to-Video Generation Models: A Dynamics Perspective
Mingxiang Liao, Hannan Lu, Xinyu Zhang, Fang Wan, Tianyu Wang, Yuzhong Zhao, Wangmeng Zuo, Qixiang Ye, Jingdong Wang
0
0
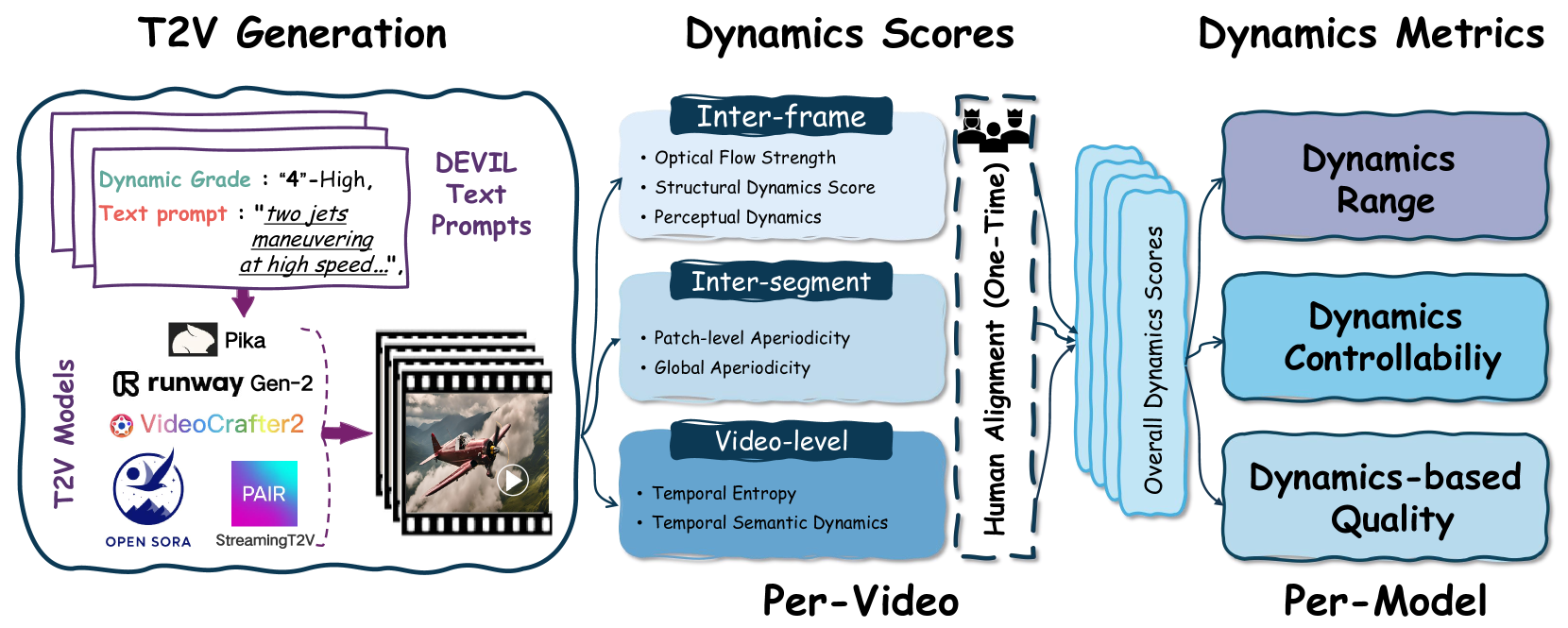
Comprehensive and constructive evaluation protocols play an important role in the development of sophisticated text-to-video (T2V) generation models. Existing evaluation protocols primarily focus on temporal consistency and content continuity, yet largely ignore the dynamics of video content. Dynamics are an essential dimension for measuring the visual vividness and the honesty of video content to text prompts. In this study, we propose an effective evaluation protocol, termed DEVIL, which centers on the dynamics dimension to evaluate T2V models. For this purpose, we establish a new benchmark comprising text prompts that fully reflect multiple dynamics grades, and define a set of dynamics scores corresponding to various temporal granularities to comprehensively evaluate the dynamics of each generated video. Based on the new benchmark and the dynamics scores, we assess T2V models with the design of three metrics: dynamics range, dynamics controllability, and dynamics-based quality. Experiments show that DEVIL achieves a Pearson correlation exceeding 90% with human ratings, demonstrating its potential to advance T2V generation models. Code is available at https://github.com/MingXiangL/DEVIL.
7/2/2024