Low-Rank Approximation, Adaptation, and Other Tales

0
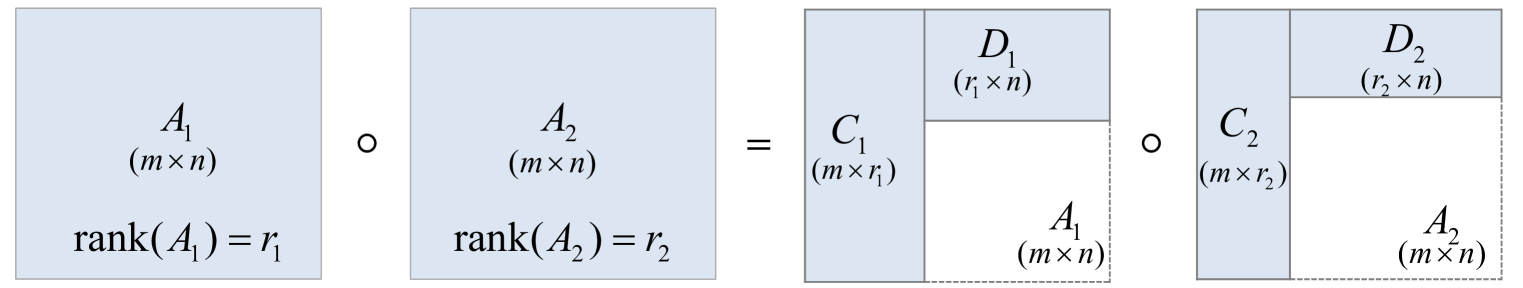
Sign in to get full access
Overview
- The paper discusses low-rank approximation and adaptation techniques, which are important for efficient machine learning and data processing.
- Key topics include low-rank decomposition via alternating least squares, low-rank adaptation, and the computational limits of low-rank adaptation.
- The paper provides technical explanations and insights, as well as a critical analysis of the research.
Plain English Explanation
Low-Rank Approximation is a technique used to simplify and compress complex data, making it easier to work with. Imagine you have a large spreadsheet with lots of numbers - low-rank approximation can find the key patterns and represent the data using fewer, simpler numbers.
This is useful for machine learning and data processing, as it allows complex models to be adapted more efficiently. Instead of updating every parameter in a large model, low-rank adaptation only updates a small subset, saving time and computing power.
However, there are limits to how much low-rank adaptation can be done before the performance starts to degrade. The paper explores these tradeoffs and provides insights into when big data can actually be represented in low-rank form.
Technical Explanation
The paper starts by describing low-rank decomposition via alternating least squares, a method for finding a low-rank approximation of a given matrix or tensor. This involves iteratively updating the low-rank factors to minimize the reconstruction error.
It then discusses low-rank adaptation, which applies this idea to quickly fine-tune large models like language models or recommender systems. By only updating a low-rank subspace of the model parameters, the adaptation can be performed much more efficiently.
The paper also examines the [object Object]. It shows that there is a limit to how much low-rank adaptation can be done before the model performance starts to degrade. This provides important guidance on when and how to apply these techniques.
Critical Analysis
The paper provides a thorough technical treatment of low-rank approximation and adaptation, with clear explanations and insightful analysis. However, it does not fully address some potential limitations:
- The paper focuses on matrix and tensor data, but many real-world datasets have more complex, hierarchical structures that may not be well-captured by low-rank representations.
- The analysis of computational limits is based on theoretical analysis, and may not fully reflect the practical challenges of deploying these techniques in real-world systems.
- The paper does not explore how the choice of low-rank approximation method might impact the performance and robustness of downstream applications.
Further research could investigate these areas and provide a more holistic understanding of the strengths, weaknesses, and appropriate use cases for low-rank approximation and adaptation techniques.
Conclusion
This paper makes valuable contributions to the understanding of low-rank approximation and adaptation, highlighting their importance for efficient machine learning and data processing. The technical explanations and critical analysis provide a solid foundation for researchers and practitioners working in this area. While the paper identifies some key limitations, it also points the way toward further advancements that could expand the applicability and robustness of these powerful techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Low-Rank Approximation, Adaptation, and Other Tales
Jun Lu
Low-rank approximation is a fundamental technique in modern data analysis, widely utilized across various fields such as signal processing, machine learning, and natural language processing. Despite its ubiquity, the mechanics of low-rank approximation and its application in adaptation can sometimes be obscure, leaving practitioners and researchers with questions about its true capabilities and limitations. This paper seeks to clarify low-rank approximation and adaptation by offering a comprehensive guide that reveals their inner workings and explains their utility in a clear and accessible way. Our focus here is to develop a solid intuition for how low-rank approximation and adaptation operate, and why they are so effective. We begin with basic concepts and gradually build up to the mathematical underpinnings, ensuring that readers of all backgrounds can gain a deeper understanding of low-rank approximation and adaptation. We strive to strike a balance between informal explanations and rigorous mathematics, ensuring that both newcomers and experienced experts can benefit from this survey. Additionally, we introduce new low-rank decomposition and adaptation algorithms that have not yet been explored in the field, hoping that future researchers will investigate their potential applicability.
Read more8/13/2024
0
Low-rank finetuning for LLMs: A fairness perspective
Saswat Das, Marco Romanelli, Cuong Tran, Zarreen Reza, Bhavya Kailkhura, Ferdinando Fioretto
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
Read more5/30/2024

0
Low-rank Adaptation for Spatio-Temporal Forecasting
Weilin Ruan, Wei Chen, Xilin Dang, Jianxiang Zhou, Weichuang Li, Xu Liu, Yuxuan Liang
Spatio-temporal forecasting is crucial in real-world dynamic systems, predicting future changes using historical data from diverse locations. Existing methods often prioritize the development of intricate neural networks to capture the complex dependencies of the data, yet their accuracy fails to show sustained improvement. Besides, these methods also overlook node heterogeneity, hindering customized prediction modules from handling diverse regional nodes effectively. In this paper, our goal is not to propose a new model but to present a novel low-rank adaptation framework as an off-the-shelf plugin for existing spatial-temporal prediction models, termed ST-LoRA, which alleviates the aforementioned problems through node-level adjustments. Specifically, we first tailor a node adaptive low-rank layer comprising multiple trainable low-rank matrices. Additionally, we devise a multi-layer residual fusion stacking module, injecting the low-rank adapters into predictor modules of various models. Across six real-world traffic datasets and six different types of spatio-temporal prediction models, our approach minimally increases the parameters and training time of the original models by less than 4%, still achieving consistent and sustained performance enhancement.
Read more4/12/2024
⚙️
0
Computational Limits of Low-Rank Adaptation (LoRA) for Transformer-Based Models
Jerry Yao-Chieh Hu, Maojiang Su, En-Jui Kuo, Zhao Song, Han Liu
We study the computational limits of Low-Rank Adaptation (LoRA) update for finetuning transformer-based models using fine-grained complexity theory. Our key observation is that the existence of low-rank decompositions within the gradient computation of LoRA adaptation leads to possible algorithmic speedup. This allows us to (i) identify a phase transition behavior and (ii) prove the existence of nearly linear algorithms by controlling the LoRA update computation term by term, assuming the Strong Exponential Time Hypothesis (SETH). For the former, we identify a sharp transition in the efficiency of all possible rank-$r$ LoRA update algorithms for transformers, based on specific norms resulting from the multiplications of the input sequence $mathbf{X}$, pretrained weights $mathbf{W^star}$, and adapter matrices $alpha mathbf{B} mathbf{A} / r$. Specifically, we derive a shared upper bound threshold for such norms and show that efficient (sub-quadratic) approximation algorithms of LoRA exist only below this threshold. For the latter, we prove the existence of nearly linear approximation algorithms for LoRA adaptation by utilizing the hierarchical low-rank structures of LoRA gradients and approximating the gradients with a series of chained low-rank approximations. To showcase our theory, we consider two practical scenarios: partial (e.g., only $mathbf{W}_V$ and $mathbf{W}_Q$) and full adaptations (e.g., $mathbf{W}_Q$, $mathbf{W}_V$, and $mathbf{W}_K$) of weights in attention heads.
Read more6/6/2024