Low-resourced Languages and Online Knowledge Repositories: A Need-Finding Study

0

Sign in to get full access
Overview
- Examines the challenges and needs of using online knowledge repositories for low-resourced languages
- Focuses on indigenous knowledge and the factors that impact accessibility and usability
- Employs a need-finding study approach to understand user experiences and requirements
Plain English Explanation
This research paper explores the challenges faced by people who speak low-resourced languages when trying to access and use online knowledge repositories. Low-resourced languages are those that have relatively few digital resources, such as translation tools, digital content, and language models.
The researchers were particularly interested in understanding the experiences and needs of people who want to access indigenous knowledge - the traditional knowledge and practices of indigenous communities. These knowledge repositories are often hard to find or use online, even for members of the communities themselves.
To better understand this problem, the researchers conducted a "need-finding study." This involved talking to people from low-resourced language communities and getting their feedback on the barriers they face and the features they would find most helpful in online knowledge repositories.
The goal was to identify key needs and requirements that could inform the design of more accessible and usable platforms for sharing and accessing indigenous and other low-resourced language knowledge online.
Technical Explanation
The paper presents a need-finding study that explores the challenges and requirements around using online knowledge repositories for low-resourced languages, with a focus on indigenous knowledge.
The researchers employed a qualitative research approach, conducting semi-structured interviews with 30 participants from various low-resourced language communities. The participants came from diverse backgrounds, including students, researchers, and community members.
During the interviews, the researchers investigated factors that impact the accessibility and usability of online knowledge repositories for low-resourced language users. They asked about participants' experiences searching for and accessing information, as well as their suggestions for improving the design and functionality of such platforms.
The findings revealed several key themes, including:
- [Challenges in discovering and accessing relevant content in low-resourced languages
- Concerns about the representation and preservation of indigenous knowledge online
- The need for more inclusive and user-friendly platform designs
The researchers used these insights to identify key design requirements and priorities for improving the accessibility and usability of online knowledge repositories for low-resourced language communities.
Critical Analysis
The paper provides valuable insights into the challenges and needs of low-resourced language communities when accessing online knowledge repositories. By conducting a detailed need-finding study, the researchers were able to identify specific barriers and design requirements that could inform the development of more inclusive and accessible platforms.
One potential limitation of the study is the relatively small sample size of 30 participants. While the qualitative approach allowed for in-depth exploration of user experiences, a larger and more diverse sample could have provided further insights and increased the generalizability of the findings.
Additionally, the paper does not delve into the technological feasibility or potential implementation challenges of the identified design requirements. Addressing these practical considerations could strengthen the overall research and provide a more comprehensive understanding of the problem.
Further research could also explore the specific needs and experiences of different sub-groups within low-resourced language communities, such as elders, youth, or marginalized populations. This could help ensure that the design of online knowledge repositories truly meets the diverse needs of these communities.
Conclusion
This need-finding study highlights the significant barriers and challenges faced by people who speak low-resourced languages when trying to access and utilize online knowledge repositories, particularly in the context of indigenous knowledge. The insights gained from this research can inform the development of more inclusive and user-friendly platforms that better serve the needs of these communities.
By addressing the factors that impact the accessibility and usability of online knowledge repositories, the research has the potential to contribute to the preservation and dissemination of valuable indigenous and low-resourced language knowledge. This, in turn, could lead to greater inclusion, empowerment, and self-determination for marginalized communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Low-resourced Languages and Online Knowledge Repositories: A Need-Finding Study
Hellina Hailu Nigatu, John Canny, Sarah E. Chasins
Online Knowledge Repositories (OKRs) like Wikipedia offer communities a way to share and preserve information about themselves and their ways of living. However, for communities with low-resourced languages -- including most African communities -- the quality and volume of content available are often inadequate. One reason for this lack of adequate content could be that many OKRs embody Western ways of knowledge preservation and sharing, requiring many low-resourced language communities to adapt to new interactions. To understand the challenges faced by low-resourced language contributors on the popular OKR Wikipedia, we conducted (1) a thematic analysis of Wikipedia forum discussions and (2) a contextual inquiry study with 14 novice contributors. We focused on three Ethiopian languages: Afan Oromo, Amharic, and Tigrinya. Our analysis revealed several recurring themes; for example, contributors struggle to find resources to corroborate their articles in low-resourced languages, and language technology support, like translation systems and spellcheck, result in several errors that waste contributors' time. We hope our study will support designers in making online knowledge repositories accessible to low-resourced language speakers.
Read more5/28/2024
📊
0
Socially Responsible Data for Large Multilingual Language Models
Andrew Smart, Ben Hutchinson, Lameck Mbangula Amugongo, Suzanne Dikker, Alex Zito, Amber Ebinama, Zara Wudiri, Ding Wang, Erin van Liemt, Jo~ao Sedoc, Seyi Olojo, Stanley Uwakwe, Edem Wornyo, Sonja Schmer-Galunder, Jamila Smith-Loud
Large Language Models (LLMs) have rapidly increased in size and apparent capabilities in the last three years, but their training data is largely English text. There is growing interest in multilingual LLMs, and various efforts are striving for models to accommodate languages of communities outside of the Global North, which include many languages that have been historically underrepresented in digital realms. These languages have been coined as low resource languages or long-tail languages, and LLMs performance on these languages is generally poor. While expanding the use of LLMs to more languages may bring many potential benefits, such as assisting cross-community communication and language preservation, great care must be taken to ensure that data collection on these languages is not extractive and that it does not reproduce exploitative practices of the past. Collecting data from languages spoken by previously colonized people, indigenous people, and non-Western languages raises many complex sociopolitical and ethical questions, e.g., around consent, cultural safety, and data sovereignty. Furthermore, linguistic complexity and cultural nuances are often lost in LLMs. This position paper builds on recent scholarship, and our own work, and outlines several relevant social, cultural, and ethical considerations and potential ways to mitigate them through qualitative research, community partnerships, and participatory design approaches. We provide twelve recommendations for consideration when collecting language data on underrepresented language communities outside of the Global North.
Read more9/10/2024
0
I Searched for a Religious Song in Amharic and Got Sexual Content Instead: Investigating Online Harm in Low-Resourced Languages on YouTube
Hellina Hailu Nigatu, Inioluwa Deborah Raji
Online social media platforms such as YouTube have a wide, global reach. However, little is known about the experience of low-resourced language speakers on such platforms; especially in how they experience and navigate harmful content. To better understand this, we (1) conducted semi-structured interviews (n=15) and (2) analyzed search results (n=9313), recommendations (n=3336), channels (n=120) and comments (n=406) of policy-violating sexual content on YouTube focusing on the Amharic language. Our findings reveal that -- although Amharic-speaking YouTube users find the platform crucial for several aspects of their lives -- participants reported unplanned exposure to policy-violating sexual content when searching for benign, popular queries. Furthermore, malicious content creators seem to exploit under-performing language technologies and content moderation to further target vulnerable groups of speakers, including migrant domestic workers, diaspora, and local Ethiopians. Overall, our study sheds light on how failures in low-resourced language technology may lead to exposure to harmful content and suggests implications for stakeholders in minimizing harm. Content Warning: This paper includes discussions of NSFW topics and harmful content (hate, abuse, sexual harassment, self-harm, misinformation). The authors do not support the creation or distribution of harmful content.
Read more5/28/2024
0
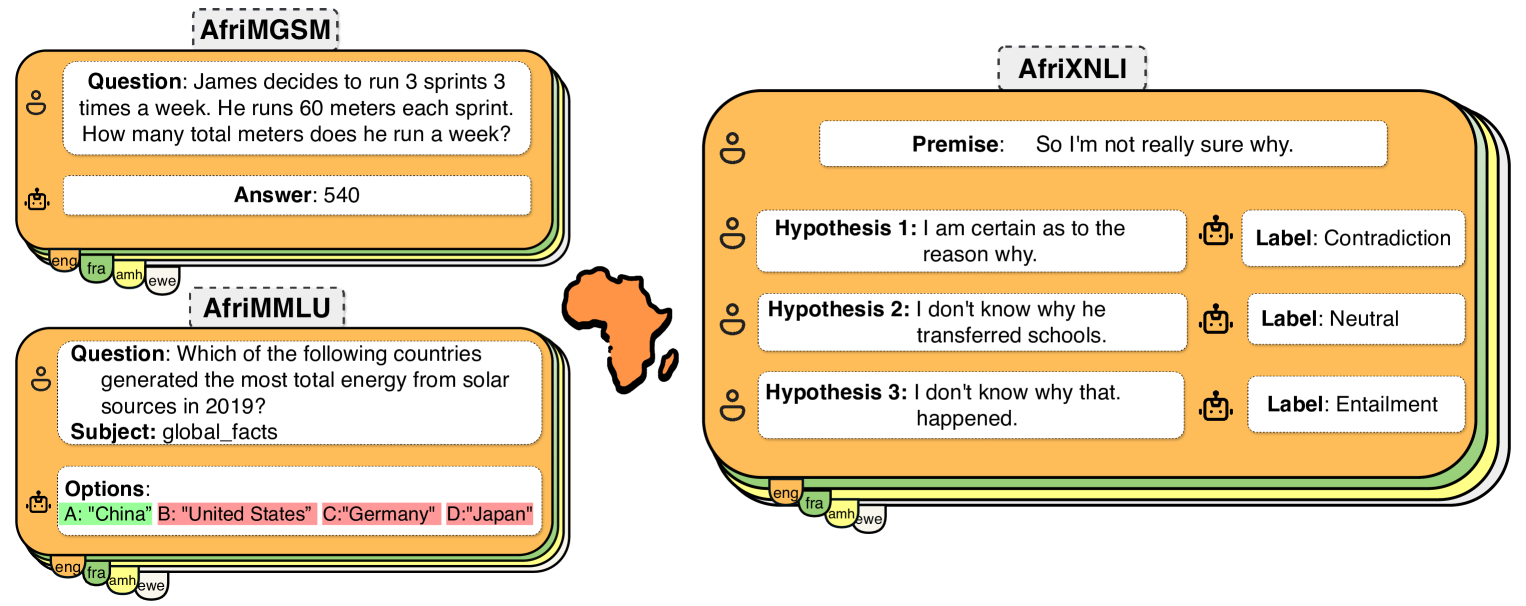
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
David Ifeoluwa Adelani, Jessica Ojo, Israel Abebe Azime, Jian Yun Zhuang, Jesujoba O. Alabi, Xuanli He, Millicent Ochieng, Sara Hooker, Andiswa Bukula, En-Shiun Annie Lee, Chiamaka Chukwuneke, Happy Buzaaba, Blessing Sibanda, Godson Kalipe, Jonathan Mukiibi, Salomon Kabongo, Foutse Yuehgoh, Mmasibidi Setaka, Lolwethu Ndolela, Nkiruka Odu, Rooweither Mabuya, Shamsuddeen Hassan Muhammad, Salomey Osei, Sokhar Samb, Tadesse Kebede Guge, Pontus Stenetorp
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
Read more6/6/2024