LSTM Recurrent Neural Networks for Cybersecurity Named Entity Recognition

0
🧠
Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
New!LSTM Recurrent Neural Networks for Cybersecurity Named Entity Recognition
Houssem Gasmi (DISP), Jannik Laval (DISP), Abdelaziz Bouras (DISP)
The automated and timely conversion of cybersecurity information from unstructured online sources, such as blogs and articles to more formal representations has become a necessity for many applications in the domain nowadays. Named Entity Recognition (NER) is one of the early phases towards this goal. It involves the detection of the relevant domain entities, such as product, version, attack name, etc. in technical documents. Although generally considered a simple task in the information extraction field, it is quite challenging in some domains like cybersecurity because of the complex structure of its entities. The state of the art methods require time-consuming and labor intensive feature engineering that describes the properties of the entities, their context, domain knowledge, and linguistic characteristics. The model demonstrated in this paper is domain independent and does not rely on any features specific to the entities in the cybersecurity domain, hence does not require expert knowledge to perform feature engineering. The method used relies on a type of recurrent neural networks called Long Short-Term Memory (LSTM) and the Conditional Random Fields (CRFs) method. The results we obtained showed that this method outperforms the state of the art methods given an annotated corpus of a decent size.
Read more9/18/2024

0
AttackER: Towards Enhancing Cyber-Attack Attribution with a Named Entity Recognition Dataset
Pritam Deka, Sampath Rajapaksha, Ruby Rani, Amirah Almutairi, Erisa Karafili
Cyber-attack attribution is an important process that allows experts to put in place attacker-oriented countermeasures and legal actions. The analysts mainly perform attribution manually, given the complex nature of this task. AI and, more specifically, Natural Language Processing (NLP) techniques can be leveraged to support cybersecurity analysts during the attribution process. However powerful these techniques are, they need to deal with the lack of datasets in the attack attribution domain. In this work, we will fill this gap and will provide, to the best of our knowledge, the first dataset on cyber-attack attribution. We designed our dataset with the primary goal of extracting attack attribution information from cybersecurity texts, utilizing named entity recognition (NER) methodologies from the field of NLP. Unlike other cybersecurity NER datasets, ours offers a rich set of annotations with contextual details, including some that span phrases and sentences. We conducted extensive experiments and applied NLP techniques to demonstrate the dataset's effectiveness for attack attribution. These experiments highlight the potential of Large Language Models (LLMs) capabilities to improve the NER tasks in cybersecurity datasets for cyber-attack attribution.
Read more8/12/2024
0
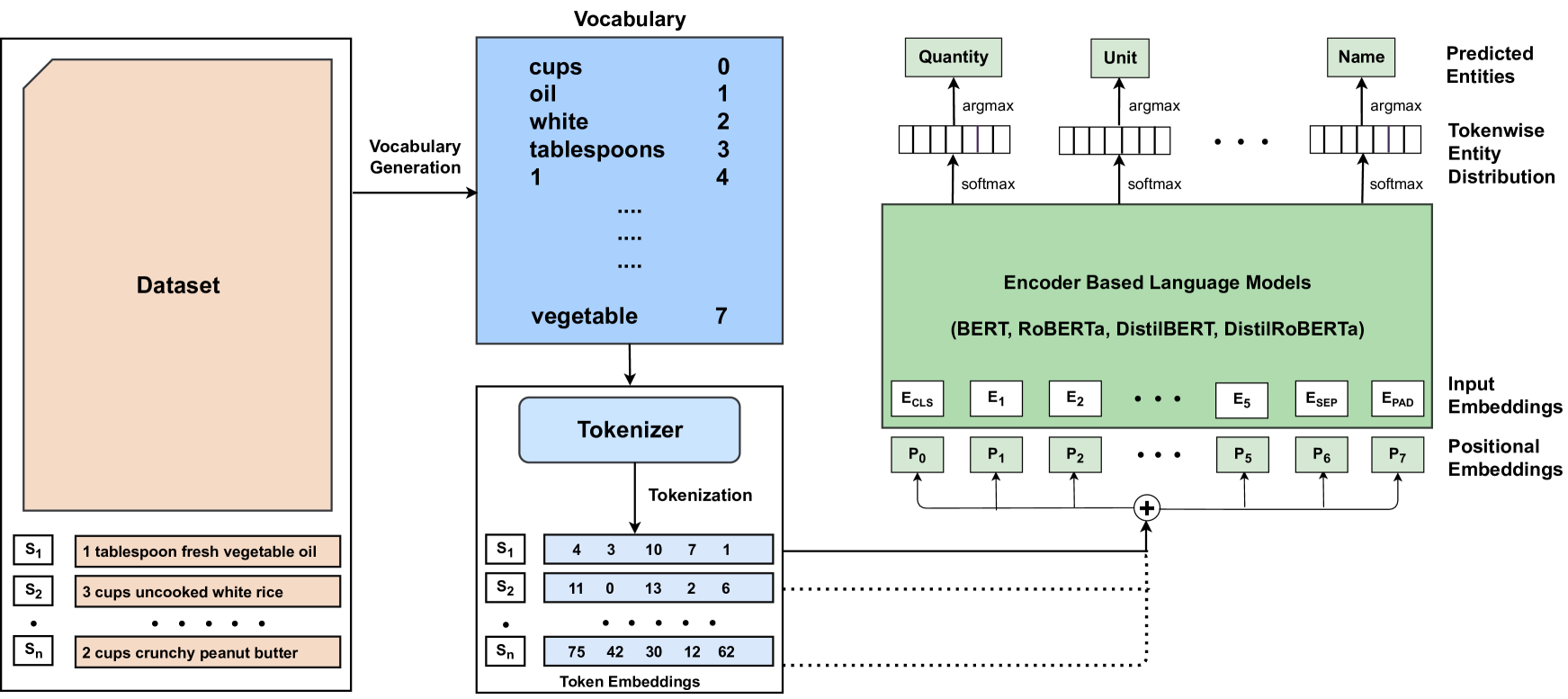
Deep Learning Based Named Entity Recognition Models for Recipes
Mansi Goel, Ayush Agarwal, Shubham Agrawal, Janak Kapuriya, Akhil Vamshi Konam, Rishabh Gupta, Shrey Rastogi, Niharika, Ganesh Bagler
Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.
Read more6/7/2024

0
llmNER: (Zero|Few)-Shot Named Entity Recognition, Exploiting the Power of Large Language Models
Fabi'an Villena, Luis Miranda, Claudio Aracena
Large language models (LLMs) allow us to generate high-quality human-like text. One interesting task in natural language processing (NLP) is named entity recognition (NER), which seeks to detect mentions of relevant information in documents. This paper presents llmNER, a Python library for implementing zero-shot and few-shot NER with LLMs; by providing an easy-to-use interface, llmNER can compose prompts, query the model, and parse the completion returned by the LLM. Also, the library enables the user to perform prompt engineering efficiently by providing a simple interface to test multiple variables. We validated our software on two NER tasks to show the library's flexibility. llmNER aims to push the boundaries of in-context learning research by removing the barrier of the prompting and parsing steps.
Read more6/10/2024