LUNA: A Model-Based Universal Analysis Framework for Large Language Models
2310.14211
0
0
💬
Abstract
Over the past decade, Artificial Intelligence (AI) has had great success recently and is being used in a wide range of academic and industrial fields. More recently, LLMs have made rapid advancements that have propelled AI to a new level, enabling even more diverse applications and industrial domains with intelligence, particularly in areas like software engineering and natural language processing. Nevertheless, a number of emerging trustworthiness concerns and issues exhibited in LLMs have already recently received much attention, without properly solving which the widespread adoption of LLMs could be greatly hindered in practice. The distinctive characteristics of LLMs, such as the self-attention mechanism, extremely large model scale, and autoregressive generation schema, differ from classic AI software based on CNNs and RNNs and present new challenges for quality analysis. Up to the present, it still lacks universal and systematic analysis techniques for LLMs despite the urgent industrial demand. Towards bridging this gap, we initiate an early exploratory study and propose a universal analysis framework for LLMs, LUNA, designed to be general and extensible, to enable versatile analysis of LLMs from multiple quality perspectives in a human-interpretable manner. In particular, we first leverage the data from desired trustworthiness perspectives to construct an abstract model as an auxiliary analysis asset, which is empowered by various abstract model construction methods. To assess the quality of the abstract model, we collect and define a number of evaluation metrics, aiming at both abstract model level and the semantics level. Then, the semantics, which is the degree of satisfaction of the LLM w.r.t. the trustworthiness perspective, is bound to and enriches the abstract model with semantics, which enables more detailed analysis applications for diverse purposes.
Create account to get full access
Overview
- Artificial Intelligence (AI) has seen great success in recent years, with large language models (LLMs) driving rapid advancements and enabling new applications in diverse domains.
- However, concerns have emerged around the trustworthiness of LLMs, which exhibit distinctive characteristics like the self-attention mechanism, large model scale, and autoregressive generation schema that differ from classic AI approaches.
- The paper proposes a universal analysis framework called LUNA to assess the quality and trustworthiness of LLMs from multiple perspectives in a human-interpretable manner.
Plain English Explanation
In recent years, Artificial Intelligence (AI) has made tremendous progress, with a particular focus on large language models (LLMs). These advanced AI systems have enabled new and diverse applications across various industries, from software engineering to natural language processing.
However, as LLMs have become more powerful, concerns have emerged about their trustworthiness. These models have unique characteristics, such as the way they process information (self-attention mechanism) and the way they generate new content (autoregressive generation schema), which differ from traditional AI approaches based on convolutional and recurrent neural networks.
To address these concerns, the researchers have developed a new framework called LUNA. LUNA is designed to analyze LLMs from multiple perspectives, evaluating their quality and trustworthiness in a way that is easy for humans to understand. The framework starts by creating an abstract model that represents the desired trustworthiness properties of the LLM. It then uses a variety of metrics to assess how well the LLM aligns with this abstract model, both at the model level and at the level of the generated content's meaning (semantics).
By providing a systematic and comprehensive way to evaluate LLMs, the researchers hope to help address the emerging trustworthiness issues and enable the widespread adoption of these powerful AI systems.
Technical Explanation
The paper proposes a universal analysis framework called LUNA to enable versatile analysis of large language models (LLMs) from multiple quality perspectives in a human-interpretable manner. The framework first leverages data from desired trustworthiness perspectives to construct an abstract model as an auxiliary analysis asset, empowered by various abstract model construction methods.
To assess the quality of the abstract model, the researchers collect and define a number of evaluation metrics, targeting both the abstract model level and the semantics level. The semantics, which represent the degree of satisfaction of the LLM with respect to the trustworthiness perspective, are then bound to and enrich the abstract model, enabling more detailed analysis applications for diverse purposes.
The proposed LUNA framework is designed to be general and extensible, addressing the lack of universal and systematic analysis techniques for LLMs despite the urgent industrial demand. By combining abstract model construction, semantics-enriched analysis, and versatile evaluation metrics, LUNA aims to provide a comprehensive solution for assessing the quality and trustworthiness of LLMs.
Critical Analysis
The paper presents a promising framework for evaluating the trustworthiness of large language models (LLMs), which is a crucial concern as these models become more prevalent. The researchers' approach of using an abstract model as an auxiliary analysis asset and then enriching it with semantics-level information is an interesting and potentially valuable strategy.
However, the paper does not provide a detailed discussion of the specific abstract model construction methods or the semantics-level evaluation metrics used. While the framework is described as general and extensible, more information on its implementation and validation would be helpful to assess its practical applicability and effectiveness.
Additionally, the paper does not address the potential challenges in obtaining the necessary data to construct the abstract models, particularly in domains where trustworthiness concerns may be more complex or subjective. Further research may be needed to explore how the LUNA framework can be adapted to handle different types of trustworthiness perspectives and data availability constraints.
Overall, the proposed LUNA framework represents an important step towards a more systematic and comprehensive approach to evaluating the trustworthiness of LLMs. As these models continue to advance and be adopted in various applications, including student essay writing, the need for such analysis tools will only become more pressing. Further development and validation of the LUNA framework could make significant contributions to ensuring the responsible and trustworthy use of LLMs in the future.
Conclusion
The paper introduces a novel framework called LUNA that aims to address the emerging trustworthiness concerns surrounding large language models (LLMs) by providing a comprehensive and human-interpretable approach to evaluating their quality. The framework's key features include the construction of abstract models based on desired trustworthiness perspectives, the enrichment of these models with semantics-level information, and the use of versatile evaluation metrics.
As LLMs continue to advance and be applied in an increasingly wide range of domains, the need for systematic and effective analysis tools like LUNA will only grow. By bridging the gap between the distinctive characteristics of LLMs and the urgent industrial demand for trustworthiness assessment, the LUNA framework could play a crucial role in enabling the responsible and widespread adoption of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Leveraging Large Language Models for NLG Evaluation: Advances and Challenges
Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, Shuai Ma
0
0
In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This paper aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this paper seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
6/13/2024
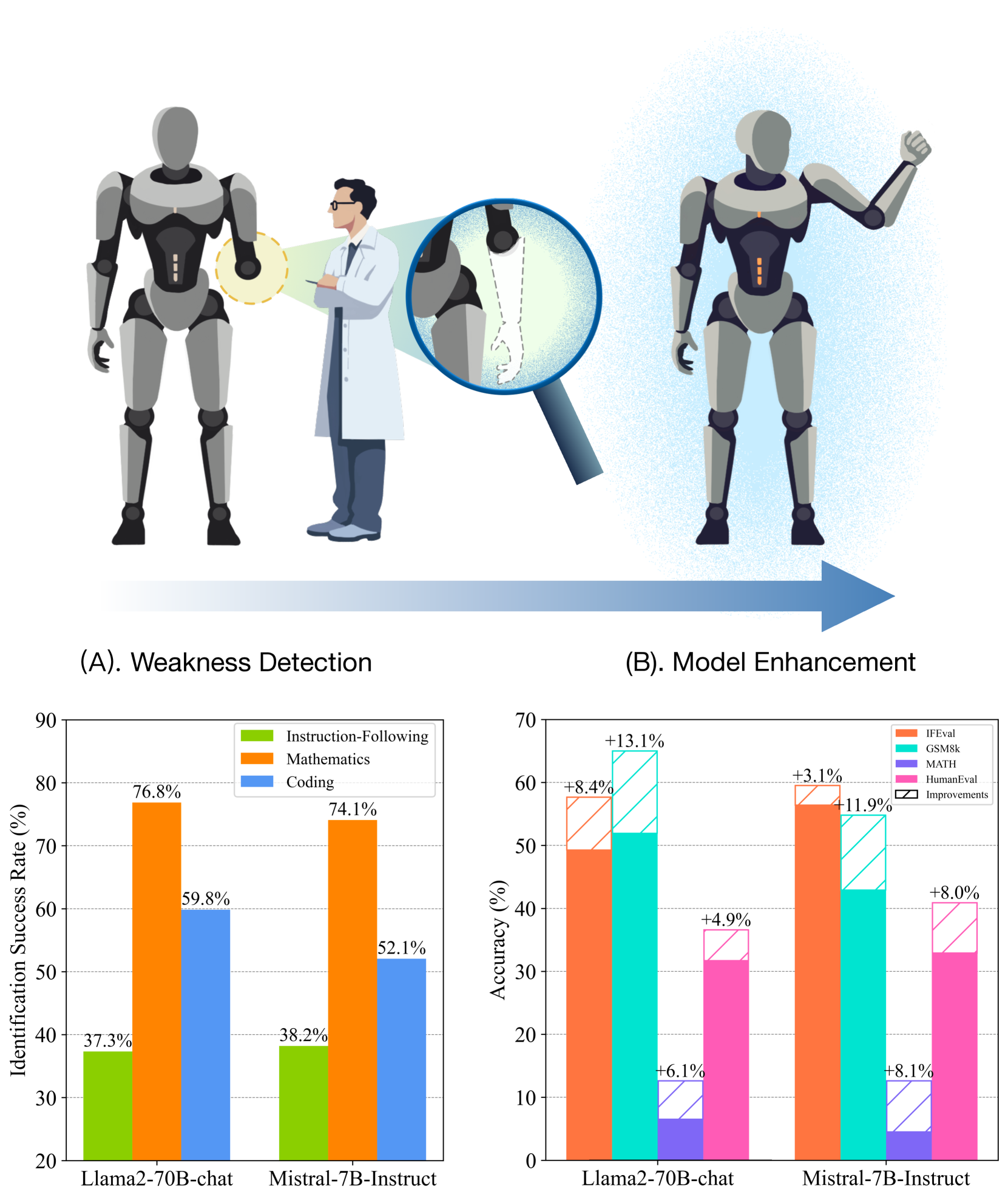
AutoDetect: Towards a Unified Framework for Automated Weakness Detection in Large Language Models
Jiale Cheng, Yida Lu, Xiaotao Gu, Pei Ke, Xiao Liu, Yuxiao Dong, Hongning Wang, Jie Tang, Minlie Huang
0
0
Although Large Language Models (LLMs) are becoming increasingly powerful, they still exhibit significant but subtle weaknesses, such as mistakes in instruction-following or coding tasks. As these unexpected errors could lead to severe consequences in practical deployments, it is crucial to investigate the limitations within LLMs systematically. Traditional benchmarking approaches cannot thoroughly pinpoint specific model deficiencies, while manual inspections are costly and not scalable. In this paper, we introduce a unified framework, AutoDetect, to automatically expose weaknesses in LLMs across various tasks. Inspired by the educational assessment process that measures students' learning outcomes, AutoDetect consists of three LLM-powered agents: Examiner, Questioner, and Assessor. The collaboration among these three agents is designed to realize comprehensive and in-depth weakness identification. Our framework demonstrates significant success in uncovering flaws, with an identification success rate exceeding 30% in prominent models such as ChatGPT and Claude. More importantly, these identified weaknesses can guide specific model improvements, proving more effective than untargeted data augmentation methods like Self-Instruct. Our approach has led to substantial enhancements in popular LLMs, including the Llama series and Mistral-7b, boosting their performance by over 10% across several benchmarks. Code and data are publicly available at https://github.com/thu-coai/AutoDetect.
6/26/2024
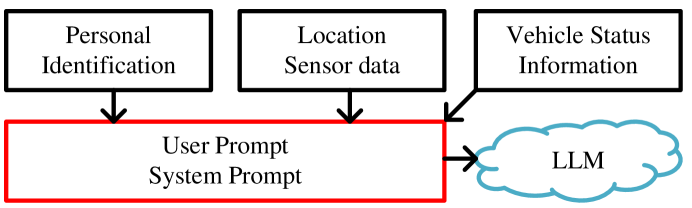
A Superalignment Framework in Autonomous Driving with Large Language Models
Xiangrui Kong, Thomas Braunl, Marco Fahmi, Yue Wang
0
0
Over the last year, significant advancements have been made in the realms of large language models (LLMs) and multi-modal large language models (MLLMs), particularly in their application to autonomous driving. These models have showcased remarkable abilities in processing and interacting with complex information. In autonomous driving, LLMs and MLLMs are extensively used, requiring access to sensitive vehicle data such as precise locations, images, and road conditions. These data are transmitted to an LLM-based inference cloud for advanced analysis. However, concerns arise regarding data security, as the protection against data and privacy breaches primarily depends on the LLM's inherent security measures, without additional scrutiny or evaluation of the LLM's inference outputs. Despite its importance, the security aspect of LLMs in autonomous driving remains underexplored. Addressing this gap, our research introduces a novel security framework for autonomous vehicles, utilizing a multi-agent LLM approach. This framework is designed to safeguard sensitive information associated with autonomous vehicles from potential leaks, while also ensuring that LLM outputs adhere to driving regulations and align with human values. It includes mechanisms to filter out irrelevant queries and verify the safety and reliability of LLM outputs. Utilizing this framework, we evaluated the security, privacy, and cost aspects of eleven large language model-driven autonomous driving cues. Additionally, we performed QA tests on these driving prompts, which successfully demonstrated the framework's efficacy.
6/11/2024
💬
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen
0
0
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at https://github.com/Paitesanshi/LLM-Agent-Survey.
4/5/2024