LVLM-Intrepret: An Interpretability Tool for Large Vision-Language Models
2404.03118
0
0

Abstract
In the rapidly evolving landscape of artificial intelligence, multi-modal large language models are emerging as a significant area of interest. These models, which combine various forms of data input, are becoming increasingly popular. However, understanding their internal mechanisms remains a complex task. Numerous advancements have been made in the field of explainability tools and mechanisms, yet there is still much to explore. In this work, we present a novel interactive application aimed towards understanding the internal mechanisms of large vision-language models. Our interface is designed to enhance the interpretability of the image patches, which are instrumental in generating an answer, and assess the efficacy of the language model in grounding its output in the image. With our application, a user can systematically investigate the model and uncover system limitations, paving the way for enhancements in system capabilities. Finally, we present a case study of how our application can aid in understanding failure mechanisms in a popular large multi-modal model: LLaVA.
Create account to get full access
Overview
- This paper presents LVLM-Intrepret, a tool for interpreting the inner workings of large vision-language models.
- The tool aims to provide insights into how these powerful models process and understand visual and textual information.
- Key features include visualizing model attention, analyzing the importance of different input components, and probing the model's learned representations.
Plain English Explanation
LVLM-Intrepret is a new tool that helps us understand how large AI models that can process both images and text actually work under the hood. These types of "vision-language" models have become incredibly powerful, but it's not always clear how they make their decisions.
The LVLM-Intrepret tool gives us a window into the inner workings of these models. It lets us see where the model is focusing its "attention" when processing an image and text together. We can also analyze which parts of the input the model finds most important for its task. And we can explore the higher-level concepts and representations the model has learned.
By using this interpretability tool, researchers and developers can gain valuable insights into how these advanced AI models actually work. This can help improve the models, make them more trustworthy, and unlock new applications. It's an important step towards making powerful vision-language AI more transparent and understandable.
Technical Explanation
The paper introduces LVLM-Intrepret, a tool for interpreting large vision-language models (LVLMs). LVLMs are a class of AI models that can process and understand both visual and textual information jointly.
The key components of LVLM-Intrepret include:
-
Attention Visualization: The tool can visualize the model's attention patterns, showing where the model is focusing when processing an image and text together.
-
Input Attribution: LVLM-Intrepret can analyze the importance of different input components (visual regions, words, etc.) for the model's overall prediction.
-
Representation Probing: The tool provides methods to interrogate the higher-level representations learned by the LVLM, revealing the conceptual knowledge captured by the model.
The authors demonstrate LVLM-Intrepret on several popular vision-language models, including CLIP and LXMERT. Through case studies, they show how the tool can provide valuable insights into model behavior and assist in model development and analysis.
Critical Analysis
The authors present a comprehensive interpretability tool that addresses an important need - understanding the inner workings of powerful vision-language AI models. By providing attention visualization, input attribution, and representation probing capabilities, LVLM-Intrepret offers a multi-faceted approach to model interpretation.
However, the paper does not discuss potential limitations or caveats of the tool. For example, the interpretability methods may be sensitive to model architecture or training data, and their reliability and generalizability should be further examined. Additionally, the paper could have provided more discussion on how the insights from LVLM-Intrepret can be applied to improve model development or real-world applications.
Overall, LVLM-Intrepret is a valuable contribution to the field of AI interpretability, but additional research is needed to fully understand the tool's capabilities, limitations, and practical impact.
Conclusion
The LVLM-Intrepret tool represents an important step towards making large, multimodal AI models more transparent and understandable. By providing rich interpretability capabilities, the tool can help researchers, developers, and users gain valuable insights into how these powerful models process and understand visual and textual information.
While further research is needed to fully explore the tool's potential and limitations, LVLM-Intrepret demonstrates the value of interpretability in advancing the development and responsible deployment of advanced AI technologies. As vision-language models continue to evolve, tools like this will play a crucial role in ensuring they are reliable, trustworthy, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
0
0
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
5/29/2024

Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, Feng Zhao
0
0
Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks over 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.
4/10/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
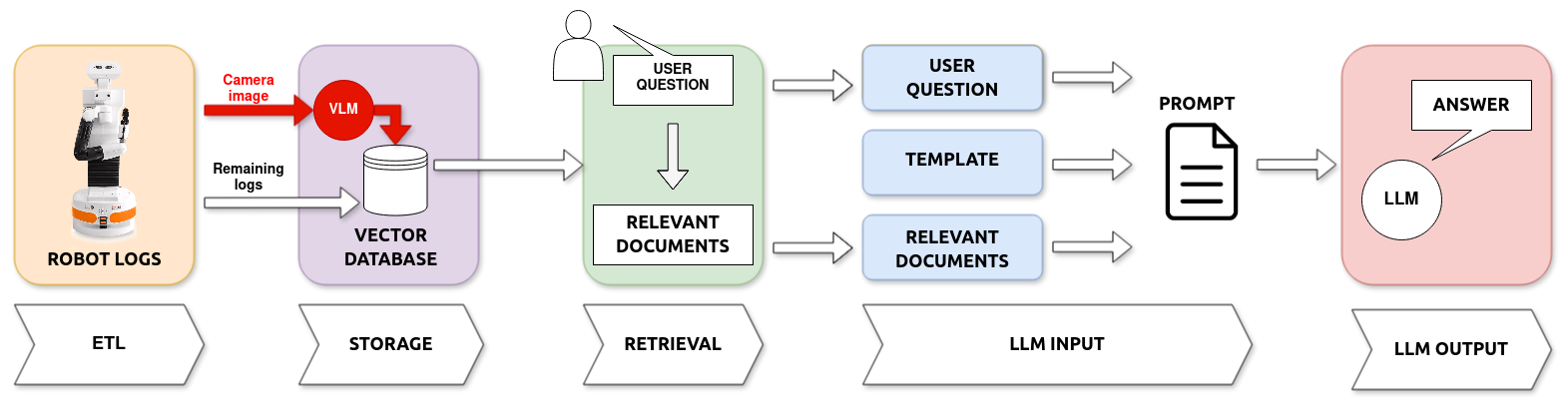
Enhancing Robot Explanation Capabilities through Vision-Language Models: a Preliminary Study by Interpreting Visual Inputs for Improved Human-Robot Interaction
David Sobr'in-Hidalgo, Miguel 'Angel Gonz'alez-Santamarta, 'Angel Manuel Guerrero-Higueras, Francisco Javier Rodr'iguez-Lera, Vicente Matell'an-Olivera
0
0
This paper presents an improved system based on our prior work, designed to create explanations for autonomous robot actions during Human-Robot Interaction (HRI). Previously, we developed a system that used Large Language Models (LLMs) to interpret logs and produce natural language explanations. In this study, we expand our approach by incorporating Vision-Language Models (VLMs), enabling the system to analyze textual logs with the added context of visual input. This method allows for generating explanations that combine data from the robot's logs and the images it captures. We tested this enhanced system on a basic navigation task where the robot needs to avoid a human obstacle. The findings from this preliminary study indicate that adding visual interpretation improves our system's explanations by precisely identifying obstacles and increasing the accuracy of the explanations provided.
4/16/2024