Lynx: An Open Source Hallucination Evaluation Model

0
Sign in to get full access
Overview
- This paper introduces Lynx, an open-source model for evaluating hallucinations in language models.
- Hallucinations occur when language models generate text that is factually incorrect or imaginative, posing challenges for real-world applications.
- Lynx aims to provide a standardized framework for assessing hallucinations and their severity, enabling better model development and deployment.
Plain English Explanation
Lynx: An Open Source Hallucination Evaluation Model presents a new tool called Lynx that can help evaluate how often language models generate made-up or incorrect information, known as "hallucinations."
Language models are AI systems that can produce human-like text, but sometimes they create sentences that are not based on real facts. This can be a problem when these models are used for important tasks like customer service or medical advice. Lynx provides a standardized way to measure how often a language model hallucinates, which can help researchers and companies develop safer and more reliable models.
By using Lynx, developers can better understand the strengths and weaknesses of their language models. This can lead to improvements that make the models more truthful and trustworthy for real-world applications. Lynx's open-source nature also allows the wider AI community to contribute to its development and use it to assess a variety of language models.
Technical Explanation
Lynx: An Open Source Hallucination Evaluation Model describes a new framework for measuring hallucinations in language models. Hallucinations occur when a model generates factually incorrect or imaginative text that is not grounded in its training data.
The Lynx framework consists of several components:
- Prompts: A diverse set of prompts that elicit hallucinations from language models.
- Annotation guidelines: Clear criteria for human annotators to identify and categorize hallucinations.
- Evaluation metrics: Quantitative measures of hallucination frequency and severity.
The authors evaluate Lynx on a variety of language models, including GPT-3 and InstructGPT. They find that Lynx can effectively detect and analyze hallucinations, providing insight into model performance and robustness.
Lynx's open-source nature allows for ongoing community contributions and extensions, such as LUNA, which focuses on evaluating hallucinations in foundation models. The availability of Lynx enables more comprehensive model assessment, leading to the development of safer and more trustworthy language models.
Critical Analysis
The Lynx framework represents an important step forward in evaluating hallucinations in language models. By providing a standardized and open-source approach, the authors enable the wider AI community to assess a variety of models and identify areas for improvement.
One potential limitation of Lynx is the reliance on human annotation to identify hallucinations. While the authors provide clear guidelines, there may still be some subjectivity in the process. Automated methods for hallucination detection, as explored in SLPL-Shroom, could help address this challenge.
Additionally, the Lynx evaluation focuses on hallucinations in isolation, but in real-world settings, language models may exhibit other undesirable behaviors, such as biased or unethical outputs. A more comprehensive evaluation framework that considers a broader range of model properties would further strengthen the assessment of language model safety and reliability.
Conclusion
Lynx: An Open Source Hallucination Evaluation Model introduces a valuable tool for assessing hallucinations in language models. By providing a standardized and open-source framework, Lynx enables the AI community to better understand and improve the reliability of these models for real-world applications.
The availability of Lynx, along with related efforts like LUNA and SLPL-Shroom, represents significant progress in the development of trustworthy and safe language models. As the field of AI continues to advance, maintaining a strong focus on model evaluation and robustness will be crucial for ensuring these technologies are deployed responsibly and in service of societal wellbeing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lynx: An Open Source Hallucination Evaluation Model
Selvan Sunitha Ravi, Bartosz Mielczarek, Anand Kannappan, Douwe Kiela, Rebecca Qian
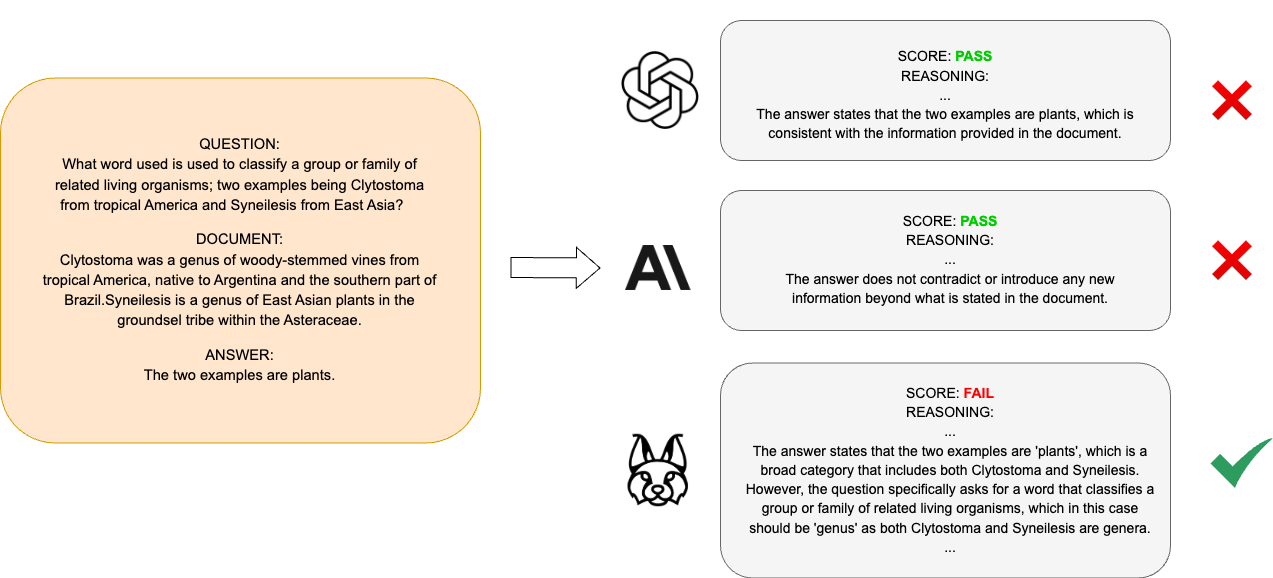
Retrieval Augmented Generation (RAG) techniques aim to mitigate hallucinations in Large Language Models (LLMs). However, LLMs can still produce information that is unsupported or contradictory to the retrieved contexts. We introduce LYNX, a SOTA hallucination detection LLM that is capable of advanced reasoning on challenging real-world hallucination scenarios. To evaluate LYNX, we present HaluBench, a comprehensive hallucination evaluation benchmark, consisting of 15k samples sourced from various real-world domains. Our experiment results show that LYNX outperforms GPT-4o, Claude-3-Sonnet, and closed and open-source LLM-as-a-judge models on HaluBench. We release LYNX, HaluBench and our evaluation code for public access.
Read more7/24/2024
0
HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
Zhiying Zhu, Yiming Yang, Zhiqing Sun
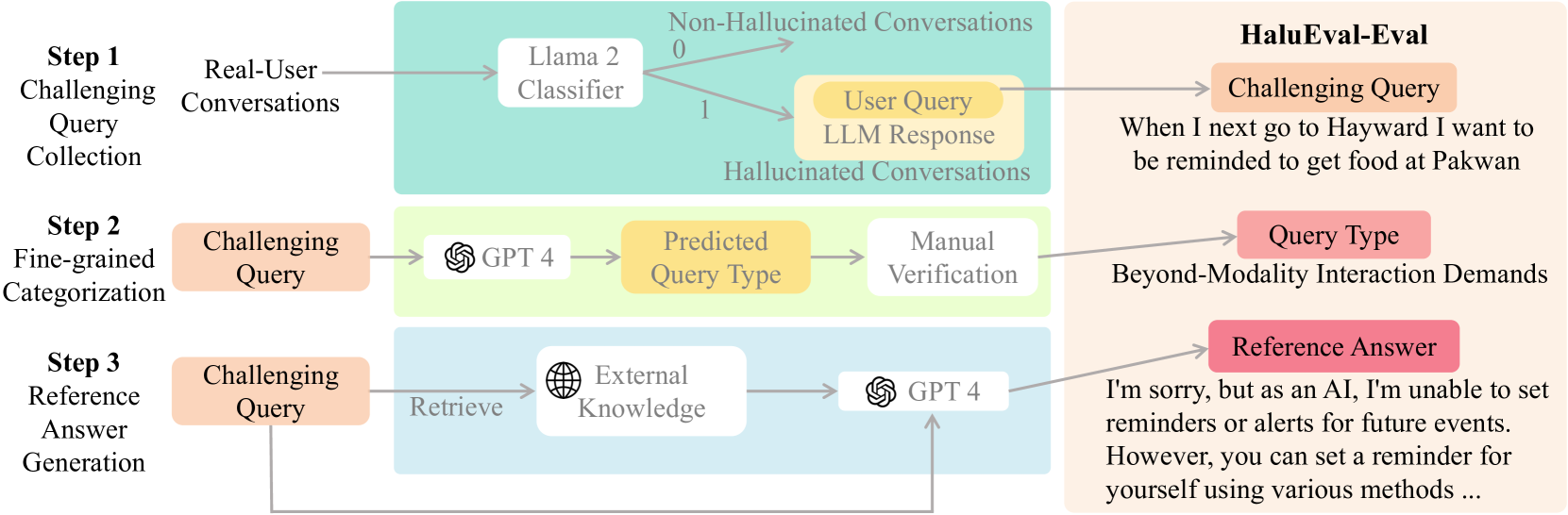
Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from ShareGPT, an existing real-world user-LLM interaction datasets, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension of and improving LLM reliability in scenarios reflective of real-world interactions. Our benchmark is available at https://github.com/HaluEval-Wild/HaluEval-Wild.
Read more9/17/2024
0
Luna: An Evaluation Foundation Model to Catch Language Model Hallucinations with High Accuracy and Low Cost
Masha Belyi, Robert Friel, Shuai Shao, Atindriyo Sanyal
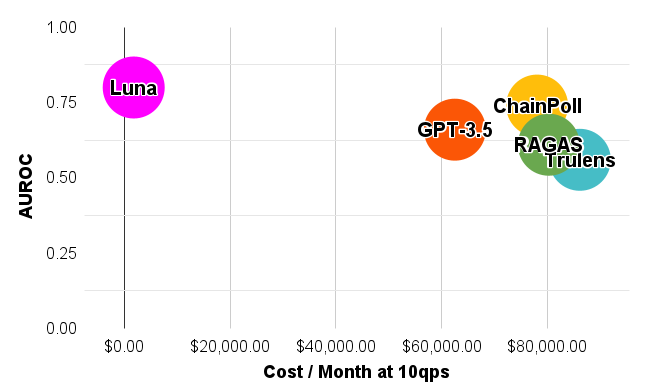
Retriever Augmented Generation (RAG) systems have become pivotal in enhancing the capabilities of language models by incorporating external knowledge retrieval mechanisms. However, a significant challenge in deploying these systems in industry applications is the detection and mitigation of hallucinations: instances where the model generates information that is not grounded in the retrieved context. Addressing this issue is crucial for ensuring the reliability and accuracy of responses generated by large language models (LLMs) in diverse industry settings. Current hallucination detection techniques fail to deliver accuracy, low latency, and low cost simultaneously. We introduce Luna: a DeBERTA-large (440M) encoder, finetuned for hallucination detection in RAG settings. We demonstrate that Luna outperforms GPT-3.5 and commercial evaluation frameworks on the hallucination detection task, with 97% and 91% reduction in cost and latency, respectively. Luna is lightweight and generalizes across multiple industry verticals and out-of-domain data, making it an ideal candidate for industry LLM applications.
Read more6/6/2024
🛸
0
The Two Sides of the Coin: Hallucination Generation and Detection with LLMs as Evaluators for LLMs
Anh Thu Maria Bui, Saskia Felizitas Brech, Natalie Hu{ss}feldt, Tobias Jennert, Melanie Ullrich, Timo Breuer, Narjes Nikzad Khasmakhi, Philipp Schaer
Hallucination detection in Large Language Models (LLMs) is crucial for ensuring their reliability. This work presents our participation in the CLEF ELOQUENT HalluciGen shared task, where the goal is to develop evaluators for both generating and detecting hallucinated content. We explored the capabilities of four LLMs: Llama 3, Gemma, GPT-3.5 Turbo, and GPT-4, for this purpose. We also employed ensemble majority voting to incorporate all four models for the detection task. The results provide valuable insights into the strengths and weaknesses of these LLMs in handling hallucination generation and detection tasks.
Read more7/15/2024