Cooperative Sentiment Agents for Multimodal Sentiment Analysis

0
Sign in to get full access
Overview
- Multimodal Sentiment Analysis: Analyzing sentiment in data that combines multiple modalities, such as text, audio, and video.
- Multimodal Representation Learning: Developing models that can effectively learn and represent the relationship between different modalities.
- Cooperative Sentiment Agents: An approach where multiple models work together to perform multimodal sentiment analysis.
Plain English Explanation
Multimodal sentiment analysis involves understanding the emotional tone or sentiment expressed in data that combines multiple types of information, such as text, audio, and video. This is a complex task because the different modalities can provide complementary or contradictory information that needs to be reconciled.
The researchers in this paper propose an approach called "Cooperative Sentiment Agents" to address this challenge. The key idea is to have multiple specialized models, or "agents," that each focus on analyzing a particular modality, such as text or video. These agents then work together, sharing information and insights, to arrive at a final sentiment analysis.
This cooperative approach is designed to leverage the strengths of each individual modality while mitigating their weaknesses. For example, text analysis may excel at detecting explicit emotional language, while video analysis could be better at picking up on subtle non-verbal cues. By combining their efforts, the researchers aim to achieve more accurate and reliable multimodal sentiment analysis.
Technical Explanation
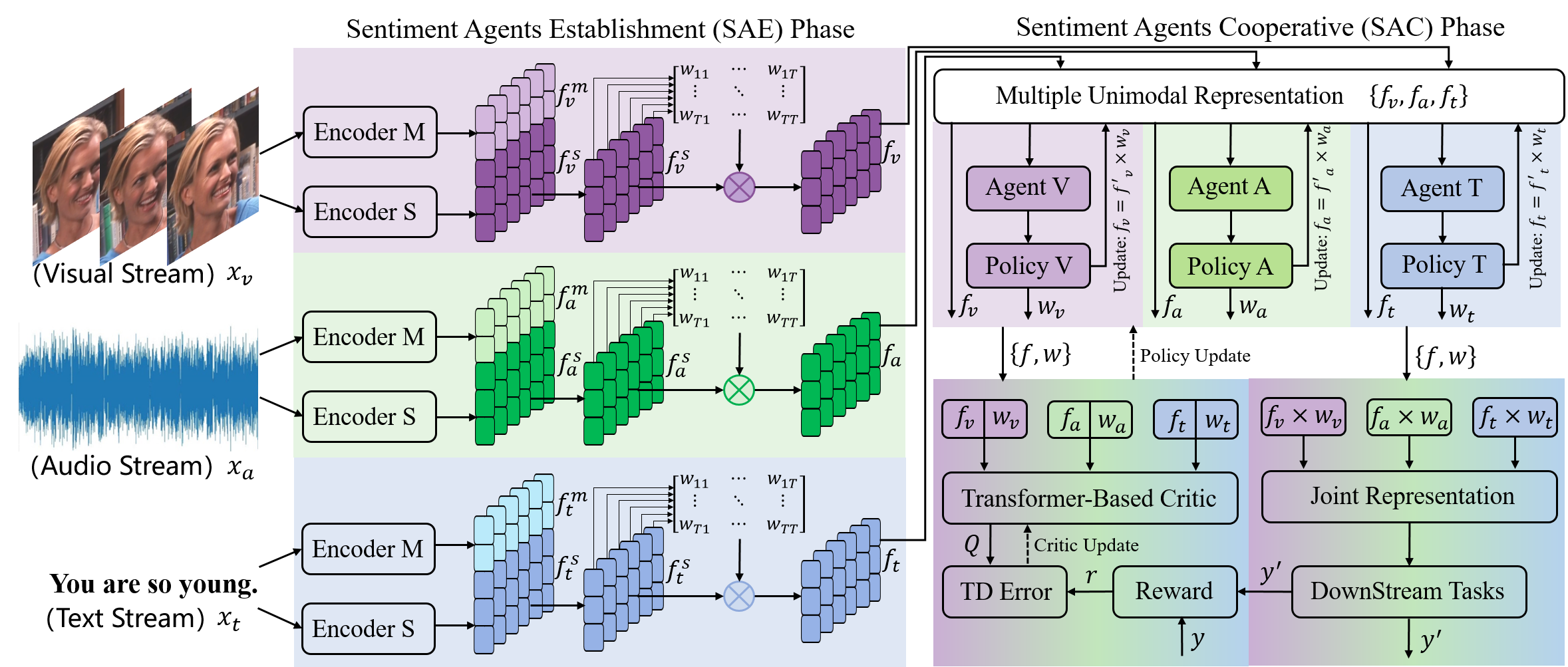
The paper presents a novel framework for multimodal sentiment analysis called "Cooperative Sentiment Agents." The key idea is to have multiple specialized models, or "agents," that each focus on analyzing a particular modality, such as text, audio, or video. These agents then work together, sharing information and insights, to arrive at a final sentiment analysis.
The architecture includes several components:
- Modality-Specific Encoders: Each agent is equipped with an encoder that processes the input from its assigned modality, such as a text encoder or a video encoder.
- Cooperative Reasoning Module: This module facilitates the exchange of information between the different agents, allowing them to learn from each other's analyses and reach a consensus.
- Fusion Layer: The final sentiment prediction is made by combining the outputs from the different agents using a fusion mechanism.
The researchers evaluate their approach on several multimodal sentiment analysis benchmarks, including MOSI, MOSEI, and CMU-MOSEI. The results demonstrate that the Cooperative Sentiment Agents framework outperforms state-of-the-art multimodal sentiment analysis models, highlighting the benefits of the cooperative approach.
Critical Analysis
The paper presents a compelling approach to multimodal sentiment analysis, but it's important to consider some potential limitations and areas for further research:
- Complexity and Computational Cost: The Cooperative Sentiment Agents framework involves multiple specialized models working together, which could increase the overall complexity and computational cost compared to more centralized approaches. The researchers should explore ways to optimize the architecture and make it more efficient.
- Interpretability: While the cooperative approach aims to leverage the strengths of different modalities, it may also introduce challenges in interpreting the final sentiment predictions. It would be valuable to investigate techniques that can provide better insight into how the individual agents contribute to the overall analysis.
- Generalization to Other Domains: The paper focuses on evaluating the framework on common multimodal sentiment analysis benchmarks. It would be interesting to see how well the Cooperative Sentiment Agents approach generalizes to other domains or tasks that involve multimodal data, such as emotion recognition or audio-visual privacy.
Overall, the Cooperative Sentiment Agents framework represents an innovative approach to addressing the challenges of multimodal sentiment analysis. Further research and development in this area could lead to significant advancements in our ability to understand and interpret complex, multimodal data.
Conclusion
The "Cooperative Sentiment Agents" framework proposed in this paper offers a novel and promising approach to multimodal sentiment analysis. By leveraging multiple specialized models that work together, the framework aims to effectively capture the nuances and complementary information present in different data modalities, such as text, audio, and video.
The key contribution of this research is the cooperative, multi-agent architecture that allows for the exchange of insights and the reconciliation of potentially conflicting signals from the various modalities. This collaborative approach has demonstrated superior performance on standard multimodal sentiment analysis benchmarks, suggesting it as a valuable tool for understanding the emotional tone and sentiment expressed in complex, real-world data.
As the field of multimodal learning continues to evolve, the Cooperative Sentiment Agents framework provides a compelling direction for further exploration and development. By combining the strengths of multiple specialized models, this approach holds the potential to unlock new frontiers in our ability to accurately and reliably interpret the rich tapestry of multimodal information that surrounds us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cooperative Sentiment Agents for Multimodal Sentiment Analysis
Shanmin Wang, Hui Shuai, Qingshan Liu, Fei Wang
In this paper, we propose a new Multimodal Representation Learning (MRL) method for Multimodal Sentiment Analysis (MSA), which facilitates the adaptive interaction between modalities through Cooperative Sentiment Agents, named Co-SA. Co-SA comprises two critical components: the Sentiment Agents Establishment (SAE) phase and the Sentiment Agents Cooperation (SAC) phase. During the SAE phase, each sentiment agent deals with an unimodal signal and highlights explicit dynamic sentiment variations within the modality via the Modality-Sentiment Disentanglement (MSD) and Deep Phase Space Reconstruction (DPSR) modules. Subsequently, in the SAC phase, Co-SA meticulously designs task-specific interaction mechanisms for sentiment agents so that coordinating multimodal signals to learn the joint representation. Specifically, Co-SA equips an independent policy model for each sentiment agent that captures significant properties within the modality. These policies are optimized mutually through the unified reward adaptive to downstream tasks. Benefitting from the rewarding mechanism, Co-SA transcends the limitation of pre-defined fusion modes and adaptively captures unimodal properties for MRL in the multimodal interaction setting. To demonstrate the effectiveness of Co-SA, we apply it to address Multimodal Sentiment Analysis (MSA) and Multimodal Emotion Recognition (MER) tasks. Our comprehensive experimental results demonstrate that Co-SA excels at discovering diverse cross-modal features, encompassing both common and complementary aspects. The code can be available at https://github.com/smwanghhh/Co-SA.
Read more4/22/2024
0
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Gaurish Thakkar, Sherzod Hakimov, Marko Tadi'c
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
Read more6/13/2024
0
Towards Multimodal Sentiment Analysis Debiasing via Bias Purification
Dingkang Yang, Mingcheng Li, Dongling Xiao, Yang Liu, Kun Yang, Zhaoyu Chen, Yuzheng Wang, Peng Zhai, Ke Li, Lihua Zhang
Multimodal Sentiment Analysis (MSA) aims to understand human intentions by integrating emotion-related clues from diverse modalities, such as visual, language, and audio. Unfortunately, the current MSA task invariably suffers from unplanned dataset biases, particularly multimodal utterance-level label bias and word-level context bias. These harmful biases potentially mislead models to focus on statistical shortcuts and spurious correlations, causing severe performance bottlenecks. To alleviate these issues, we present a Multimodal Counterfactual Inference Sentiment (MCIS) analysis framework based on causality rather than conventional likelihood. Concretely, we first formulate a causal graph to discover harmful biases from already-trained vanilla models. In the inference phase, given a factual multimodal input, MCIS imagines two counterfactual scenarios to purify and mitigate these biases. Then, MCIS can make unbiased decisions from biased observations by comparing factual and counterfactual outcomes. We conduct extensive experiments on several standard MSA benchmarks. Qualitative and quantitative results show the effectiveness of the proposed framework.
Read more7/8/2024

0
Evaluation of data inconsistency for multi-modal sentiment analysis
Yufei Wang, Mengyue Wu
Emotion semantic inconsistency is an ubiquitous challenge in multi-modal sentiment analysis (MSA). MSA involves analyzing sentiment expressed across various modalities like text, audio, and videos. Each modality may convey distinct aspects of sentiment, due to subtle and nuanced expression of human beings, leading to inconsistency, which may hinder the prediction of artificial agents. In this work, we introduce a modality conflicting test set and assess the performance of both traditional multi-modal sentiment analysis models and multi-modal large language models (MLLMs). Our findings reveal significant performance degradation across traditional models when confronted with semantically conflicting data and point out the drawbacks of MLLMs when handling multi-modal emotion analysis. Our research presents a new challenge and offer valuable insights for the future development of sentiment analysis systems.
Read more6/6/2024