Trustworthy Multimodal Fusion for Sentiment Analysis in Ordinal Sentiment Space
2404.08923
0
0
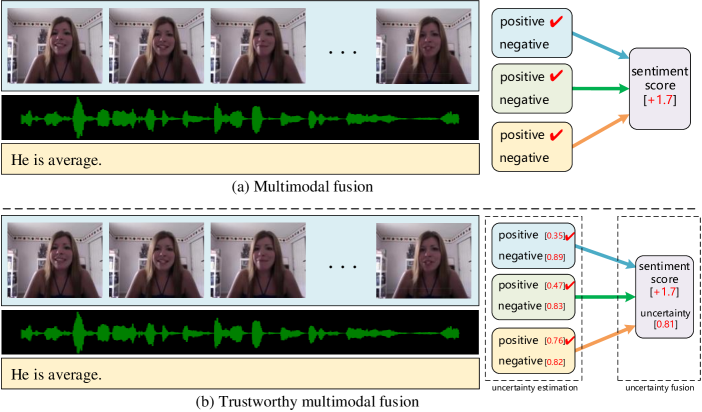
Abstract
Multimodal video sentiment analysis aims to integrate multiple modal information to analyze the opinions and attitudes of speakers. Most previous work focuses on exploring the semantic interactions of intra- and inter-modality. However, these works ignore the reliability of multimodality, i.e., modalities tend to contain noise, semantic ambiguity, missing modalities, etc. In addition, previous multimodal approaches treat different modalities equally, largely ignoring their different contributions. Furthermore, existing multimodal sentiment analysis methods directly regress sentiment scores without considering ordinal relationships within sentiment categories, with limited performance. To address the aforementioned problems, we propose a trustworthy multimodal sentiment ordinal network (TMSON) to improve performance in sentiment analysis. Specifically, we first devise a unimodal feature extractor for each modality to obtain modality-specific features. Then, an uncertainty distribution estimation network is customized, which estimates the unimodal uncertainty distributions. Next, Bayesian fusion is performed on the learned unimodal distributions to obtain multimodal distributions for sentiment prediction. Finally, an ordinal-aware sentiment space is constructed, where ordinal regression is used to constrain the multimodal distributions. Our proposed TMSON outperforms baselines on multimodal sentiment analysis tasks, and empirical results demonstrate that TMSON is capable of reducing uncertainty to obtain more robust predictions.
Create account to get full access
Overview
- This paper presents a trustworthy multimodal fusion approach for sentiment analysis in ordinal sentiment space.
- It addresses the challenges of combining visual, textual, and audio modalities to accurately predict sentiment scores on an ordinal scale.
- The proposed method aims to provide reliable uncertainty estimates along with sentiment predictions, enabling more trustworthy decision-making.
Plain English Explanation
Sentiment analysis is the process of understanding the emotional tone or attitude expressed in text, images, or audio. In many applications, like analyzing customer reviews or social media posts, it's important to not just categorize sentiment as positive or negative, but to measure it on a more nuanced scale, like "strongly positive," "neutral," or "slightly negative."
This paper introduces a new way to combine information from different sources, like text, images, and audio, to make more accurate and trustworthy predictions of sentiment on an ordinal scale. The key innovation is that the model not only provides a sentiment score, but also estimates how certain it is about that score. This extra information can help users understand how much they can trust the model's predictions, which is crucial for making important decisions based on the analysis.
The researchers tested their approach on several standard datasets for multimodal sentiment analysis, and found that it outperformed other state-of-the-art methods in terms of accuracy and reliability of the uncertainty estimates. By making sentiment analysis more trustworthy, this work could have applications in areas like customer experience monitoring, mental health tracking, and political polling.
Technical Explanation
The paper proposes a Trustworthy Multimodal Fusion (TMF) model for sentiment analysis in ordinal sentiment space. The core innovation is a novel fusion module that learns to combine visual, textual, and audio features in a way that produces not just a sentiment score, but also a reliable estimate of the model's uncertainty about that score.
The fusion module uses attention mechanisms to dynamically weigh the importance of each modality based on the input. It also includes a dedicated uncertainty estimation branch that predicts the variance of the ordinal sentiment score. This allows the model to express its confidence in the predicted sentiment, rather than just providing a point estimate.
The TMF model is evaluated on several standard multimodal sentiment analysis datasets, including M2SA, MOSEI, and MOSI. The results show that TMF outperforms other state-of-the-art multimodal fusion methods in terms of both sentiment prediction accuracy and the reliability of the uncertainty estimates.
Critical Analysis
The paper makes a compelling case for the importance of trustworthy sentiment analysis, particularly in ordinal sentiment spaces where precise score predictions are required. The authors have addressed a key limitation of many existing multimodal fusion approaches, which is the lack of reliable uncertainty estimates.
However, the paper does not explore the limitations of the proposed TMF model in depth. For example, it's unclear how the model would perform on more diverse or challenging datasets, or how it would scale to real-world applications with larger and noisier data. Additionally, the paper does not discuss potential biases or fairness issues that may arise from the multimodal fusion approach.
Further research could investigate the robustness and generalizability of the TMF model, as well as explore ways to make the uncertainty estimates more interpretable and actionable for end users. Comparisons to other multimodal fusion techniques could also provide additional insights into the strengths and limitations of the proposed approach.
Conclusion
The Trustworthy Multimodal Fusion (TMF) model presented in this paper represents an important step forward in the field of multimodal sentiment analysis. By combining visual, textual, and audio features in a way that provides reliable uncertainty estimates, the model enables more trustworthy and informed decision-making based on sentiment analysis.
The strong performance of TMF on standard benchmarks suggests that it could have significant real-world applications, particularly in areas where accurate and transparent sentiment analysis is crucial, such as customer experience monitoring, mental health tracking, and political polling. As the use of AI systems becomes more widespread, the ability to quantify and convey uncertainty will be essential for building trust and ensuring responsible deployment.
Overall, this paper makes a valuable contribution to the ongoing efforts to develop more robust and trustworthy multimodal AI systems for sentiment analysis and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Multimodal Multi-loss Fusion Network for Sentiment Analysis
Zehui Wu, Ziwei Gong, Jaywon Koo, Julia Hirschberg
0
0
This paper investigates the optimal selection and fusion of feature encoders across multiple modalities and combines these in one neural network to improve sentiment detection. We compare different fusion methods and examine the impact of multi-loss training within the multi-modality fusion network, identifying surprisingly important findings relating to subnet performance. We have also found that integrating context significantly enhances model performance. Our best model achieves state-of-the-art performance for three datasets (CMU-MOSI, CMU-MOSEI and CH-SIMS). These results suggest a roadmap toward an optimized feature selection and fusion approach for enhancing sentiment detection in neural networks.
6/4/2024
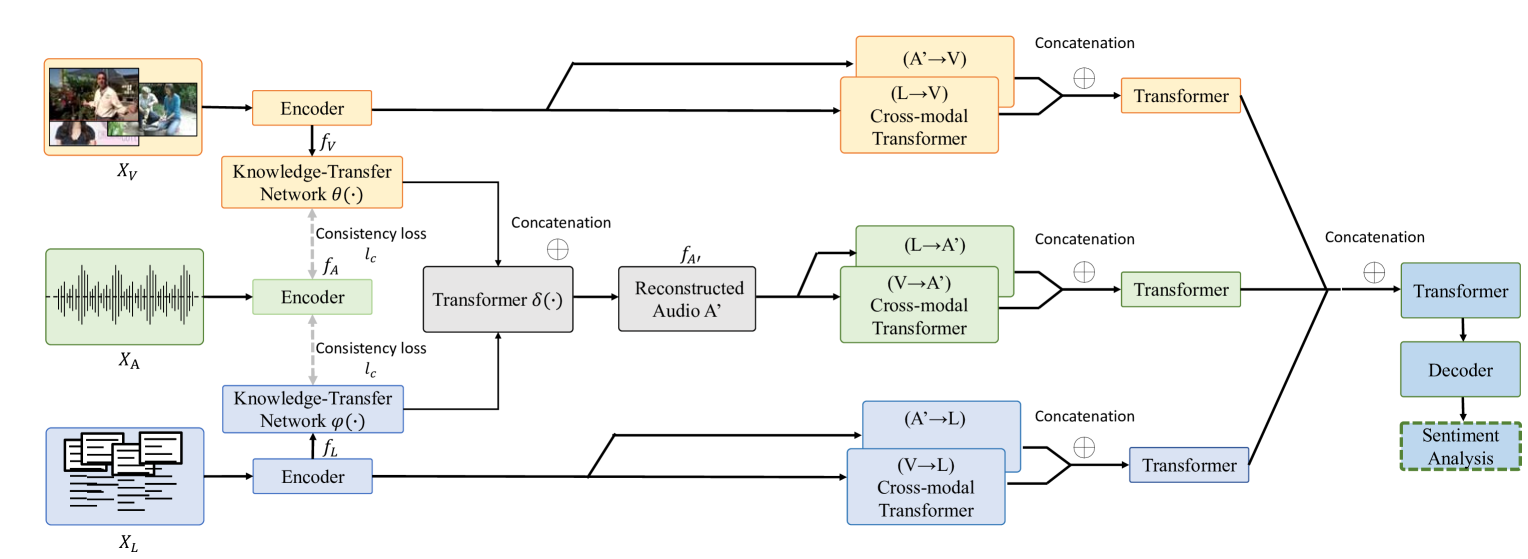
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
0
0
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
6/21/2024
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Gaurish Thakkar, Sherzod Hakimov, Marko Tadi'c
0
0
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
6/13/2024
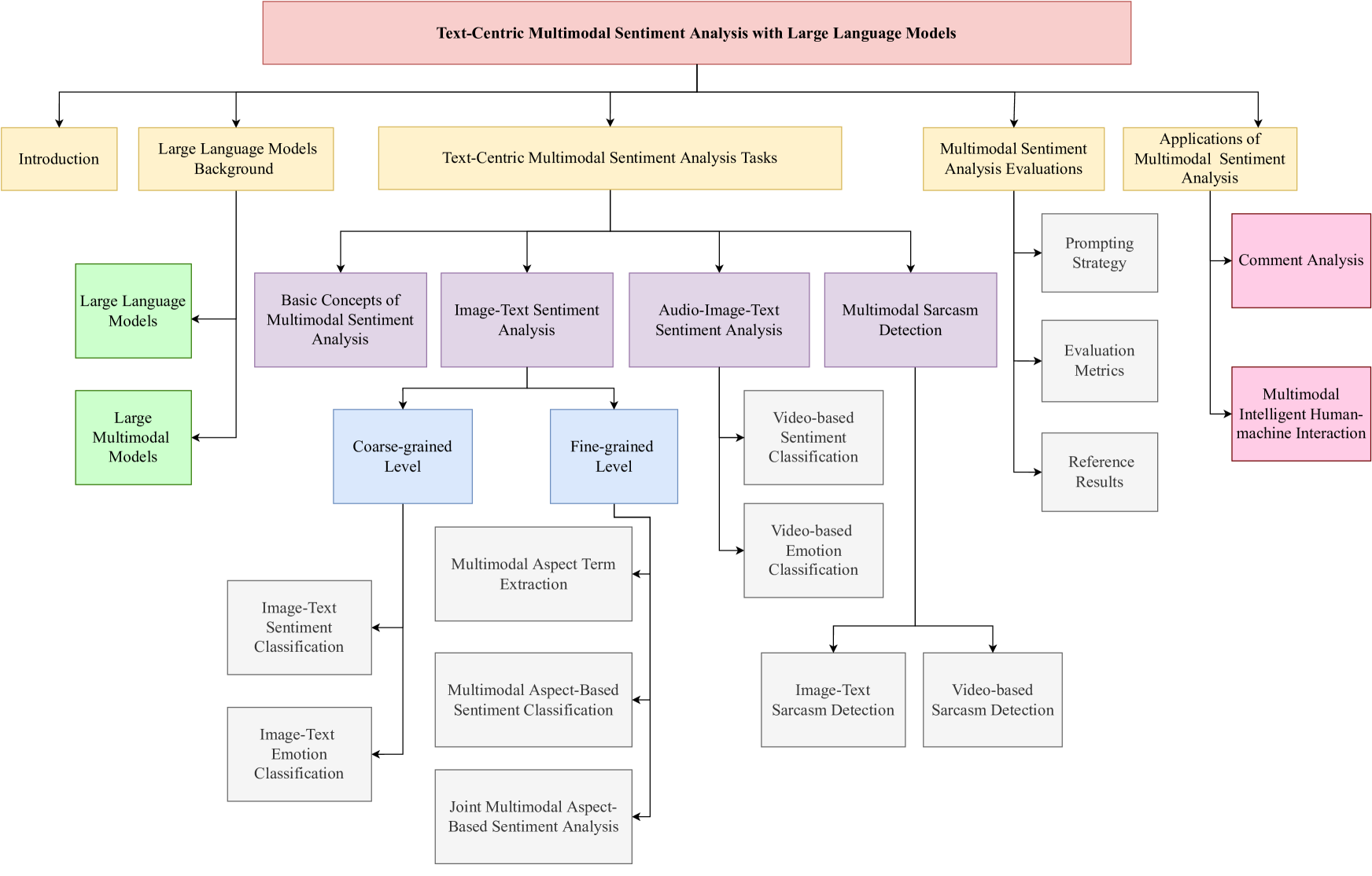
Large Language Models Meet Text-Centric Multimodal Sentiment Analysis: A Survey
Hao Yang, Yanyan Zhao, Yang Wu, Shilong Wang, Tian Zheng, Hongbo Zhang, Wanxiang Che, Bing Qin
0
0
Compared to traditional sentiment analysis, which only considers text, multimodal sentiment analysis needs to consider emotional signals from multimodal sources simultaneously and is therefore more consistent with the way how humans process sentiment in real-world scenarios. It involves processing emotional information from various sources such as natural language, images, videos, audio, physiological signals, etc. However, although other modalities also contain diverse emotional cues, natural language usually contains richer contextual information and therefore always occupies a crucial position in multimodal sentiment analysis. The emergence of ChatGPT has opened up immense potential for applying large language models (LLMs) to text-centric multimodal tasks. However, it is still unclear how existing LLMs can adapt better to text-centric multimodal sentiment analysis tasks. This survey aims to (1) present a comprehensive review of recent research in text-centric multimodal sentiment analysis tasks, (2) examine the potential of LLMs for text-centric multimodal sentiment analysis, outlining their approaches, advantages, and limitations, (3) summarize the application scenarios of LLM-based multimodal sentiment analysis technology, and (4) explore the challenges and potential research directions for multimodal sentiment analysis in the future.
6/13/2024