Machine Learning and Data Analysis Using Posets: A Survey

0
📊
Sign in to get full access
Overview
- This paper provides a comprehensive survey on using partially ordered sets (posets) for machine learning and data analysis.
- Posets are mathematical structures that can represent hierarchical or ordered relationships in data, and the paper explores how they can be leveraged for various ML and data analysis tasks.
- Key topics covered include the basics of partial order theory, applications of posets in machine learning and formal concept analysis, as well as challenges and future research directions.
Plain English Explanation
Posets are a way of organizing and representing information that has a natural hierarchy or ordering. Imagine you have a collection of items, like different types of fruits, and you want to show how they are related to each other. Some fruits might be considered "bigger" than others, like an apple is larger than a cherry. A poset can capture these kinds of ordered relationships.
The researchers in this paper look at how posets can be used in machine learning and data analysis. For example, if you have a dataset about people's preferences, a poset could help you identify patterns and clusters in the data based on the ordering of the preferences. Or in a text analysis task, a poset could reveal the hierarchical structure of concepts and ideas expressed in the text.
The key advantage of using posets is that they can uncover meaningful relationships in complex, multi-dimensional data that might be missed by other analytical techniques. By leveraging the inherent structure of posets, machine learning models can gain deeper insights and make more informed decisions.
Technical Explanation
The paper first provides an overview of the basic concepts and properties of partially ordered sets (posets). Posets are mathematical structures that generalize the familiar concept of a total order (e.g. the ordering of real numbers) to allow for partial orderings, where some elements may not be comparable.
The authors then survey a range of applications of posets in machine learning and data analysis. For instance, posets can be used to represent and analyze the hierarchical structure of concepts in text data through formal concept analysis. They can also be applied to multi-label classification tasks, where the goal is to predict multiple target labels for each input, by exploiting the ordered relationships between labels.
Additionally, the paper discusses how poset-based techniques can handle missing or uncertain data, and how they can be combined with deep learning models to leverage their complementary strengths. The authors also highlight several open challenges, such as efficient algorithms for poset-based learning and the interpretability of poset-based models.
Critical Analysis
The paper provides a thorough and well-structured overview of the use of posets in machine learning and data analysis, highlighting the key benefits and challenges of this approach. The authors do a good job of covering a diverse range of applications, from text analysis to multi-label classification, demonstrating the versatility of poset-based techniques.
One potential limitation is that the paper focuses mainly on the theoretical and methodological aspects, without delving deeply into empirical evaluations or case studies. Providing more concrete examples of how poset-based methods have been successfully applied in real-world scenarios could further strengthen the paper's impact and usefulness for practitioners.
Additionally, the authors could have discussed in more depth the trade-offs and potential downsides of using posets, such as the computational complexity of poset-based algorithms or the challenges in constructing appropriate poset structures for certain applications. Acknowledging these issues would help readers gain a more balanced understanding of the strengths and weaknesses of this approach.
Overall, the paper is a valuable resource for researchers and practitioners interested in exploring the integration of posets with machine learning and data analysis. The comprehensive survey lays a solid foundation for further advancements in this emerging field.
Conclusion
This paper offers a comprehensive overview of the use of partially ordered sets (posets) in machine learning and data analysis. Posets provide a powerful way to represent and exploit the inherent hierarchical structure of complex data, enabling more nuanced and insightful analyses compared to traditional techniques.
The authors cover a wide range of applications, from text mining to multi-label classification, demonstrating the versatility of poset-based methods. They also discuss key theoretical concepts, algorithmic challenges, and opportunities for future research, providing a valuable resource for the research community.
As data continues to grow in volume and complexity, the ability to effectively leverage the underlying structure and relationships within the data will become increasingly important. The insights offered in this paper suggest that poset-based approaches have significant potential to advance the state of the art in machine learning and data analysis, with far-reaching implications across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Machine Learning and Data Analysis Using Posets: A Survey
Arnauld Mesinga Mwafise
Posets are discrete mathematical structures which are ubiquitous in a broad range of data analysis and machine learning applications. Research connecting posets to the data science domain has been ongoing for many years. In this paper, a comprehensive review of a wide range of studies on data analysis and machine learning using posets are examined in terms of their theory, algorithms and applications. In addition, the applied lattice theory domain of formal concept analysis will also be highlighted in terms of its machine learning applications.
Read more5/28/2024
0
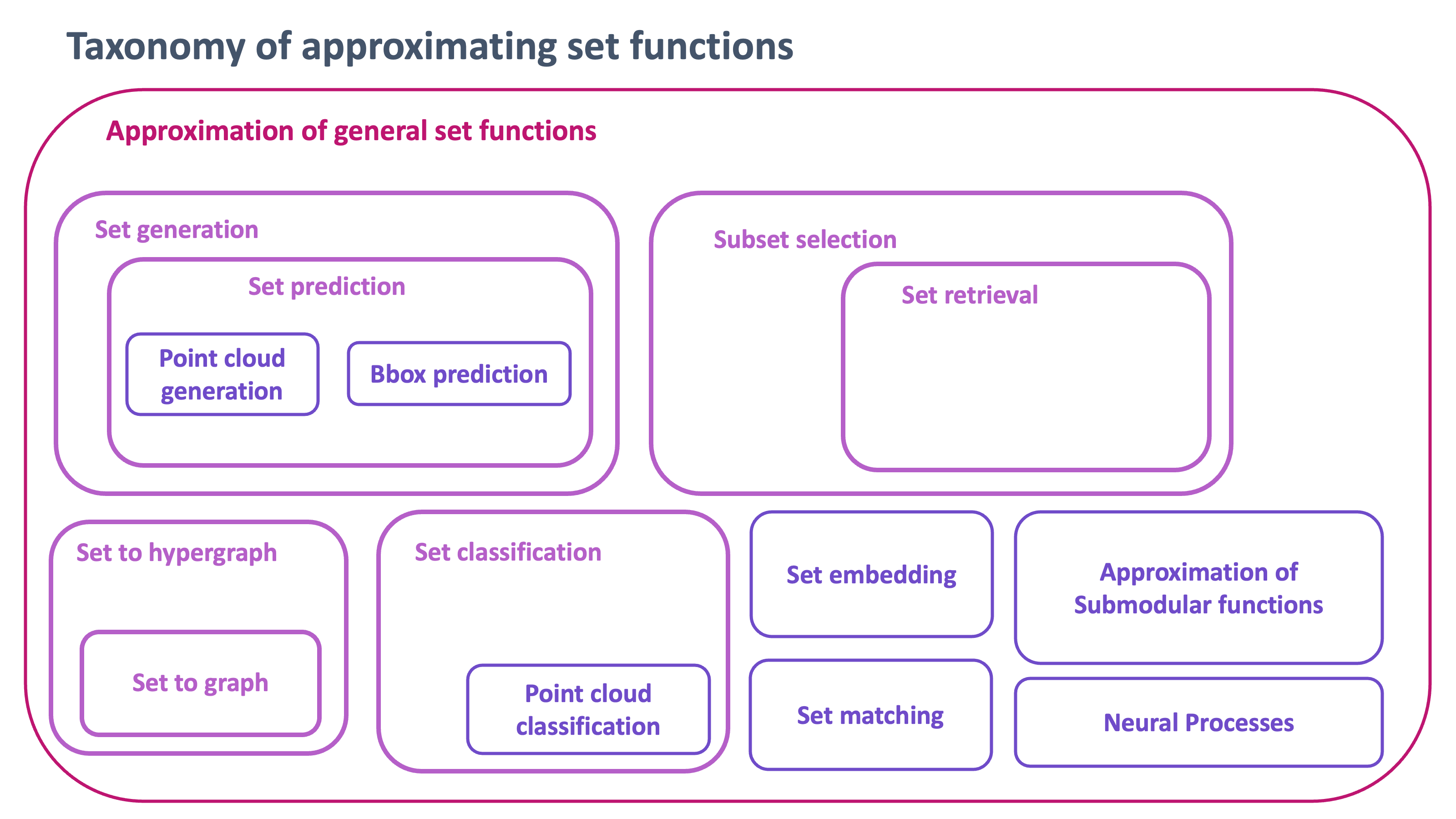
On permutation-invariant neural networks
Masanari Kimura, Ryotaro Shimizu, Yuki Hirakawa, Ryosuke Goto, Yuki Saito
Conventional machine learning algorithms have traditionally been designed under the assumption that input data follows a vector-based format, with an emphasis on vector-centric paradigms. However, as the demand for tasks involving set-based inputs has grown, there has been a paradigm shift in the research community towards addressing these challenges. In recent years, the emergence of neural network architectures such as Deep Sets and Transformers has presented a significant advancement in the treatment of set-based data. These architectures are specifically engineered to naturally accommodate sets as input, enabling more effective representation and processing of set structures. Consequently, there has been a surge of research endeavors dedicated to exploring and harnessing the capabilities of these architectures for various tasks involving the approximation of set functions. This comprehensive survey aims to provide an overview of the diverse problem settings and ongoing research efforts pertaining to neural networks that approximate set functions. By delving into the intricacies of these approaches and elucidating the associated challenges, the survey aims to equip readers with a comprehensive understanding of the field. Through this comprehensive perspective, we hope that researchers can gain valuable insights into the potential applications, inherent limitations, and future directions of set-based neural networks. Indeed, from this survey we gain two insights: i) Deep Sets and its variants can be generalized by differences in the aggregation function, and ii) the behavior of Deep Sets is sensitive to the choice of the aggregation function. From these observations, we show that Deep Sets, one of the well-known permutation-invariant neural networks, can be generalized in the sense of a quasi-arithmetic mean.
Read more4/1/2024
🤖
0
Category-Theoretical and Topos-Theoretical Frameworks in Machine Learning: A Survey
Yiyang Jia, Guohong Peng, Zheng Yang, Tianhao Chen
In this survey, we provide an overview of category theory-derived machine learning from four mainstream perspectives: gradient-based learning, probability-based learning, invariance and equivalence-based learning, and topos-based learning. For the first three topics, we primarily review research in the past five years, updating and expanding on the previous survey by Shiebler et al.. The fourth topic, which delves into higher category theory, particularly topos theory, is surveyed for the first time in this paper. In certain machine learning methods, the compositionality of functors plays a vital role, prompting the development of specific categorical frameworks. However, when considering how the global properties of a network reflect in local structures and how geometric properties are expressed with logic, the topos structure becomes particularly significant and profound.
Read more8/30/2024

0
Lessons on Datasets and Paradigms in Machine Learning for Symbolic Computation: A Case Study on CAD
Tereso del R'io, Matthew England
Symbolic Computation algorithms and their implementation in computer algebra systems often contain choices which do not affect the correctness of the output but can significantly impact the resources required: such choices can benefit from having them made separately for each problem via a machine learning model. This study reports lessons on such use of machine learning in symbolic computation, in particular on the importance of analysing datasets prior to machine learning and on the different machine learning paradigms that may be utilised. We present results for a particular case study, the selection of variable ordering for cylindrical algebraic decomposition, but expect that the lessons learned are applicable to other decisions in symbolic computation. We utilise an existing dataset of examples derived from applications which was found to be imbalanced with respect to the variable ordering decision. We introduce an augmentation technique for polynomial systems problems that allows us to balance and further augment the dataset, improving the machine learning results by 28% and 38% on average, respectively. We then demonstrate how the existing machine learning methodology used for the problem $-$ classification $-$ might be recast into the regression paradigm. While this does not have a radical change on the performance, it does widen the scope in which the methodology can be applied to make choices.
Read more6/21/2024