Machine Unlearning using a Multi-GAN based Model

0
📈
Sign in to get full access
Overview
- This paper presents a new machine unlearning approach that uses multiple Generative Adversarial Network (GAN) based models.
- The proposed method has two phases: data reorganization and fine-tuning the pre-trained model.
- The GAN models generate synthetic data for the retain and forget datasets, and the class labels of the synthetic and original forget datasets are inverted.
- The combined datasets are used to fine-tune the pre-trained model, resulting in the unlearned model.
- Experiments were conducted on the CIFAR-10 dataset, and the unlearned models were tested using Membership Inference Attacks (MIA).
Plain English Explanation
The paper introduces a new way to [object Object] information that a machine learning model has learned, known as "machine unlearning." This is useful when you want to [object Object] certain data that the model has been trained on, such as sensitive or personal information.
The key idea is to use [object Object] generated by [object Object] to help the model "unlearn" the information it has learned. The paper has two main steps:
-
Data Reorganization: The researchers use GANs to create new, synthetic data that has the opposite [object Object] of the data the model should forget. This helps the model learn to ignore that information.
-
Fine-Tuning: The researchers then use the combined dataset, including the original data and the new synthetic data, to [object Object] the model. This helps the model "unlearn" the information it had previously learned.
The researchers tested this approach on the [object Object] and found that it was effective at helping the model forget the information it had learned, as measured by [object Object].
Technical Explanation
The proposed machine unlearning approach utilizes [object Object] based models. The method comprises two phases:
-
Data Reorganization: In this phase, the researchers use GANs to generate synthetic data with [object Object] for the "forget" datasets. This helps the model learn to ignore the information it had previously learned.
-
Fine-Tuning: The researchers then use the combined dataset, including the original data and the new synthetic data, to [object Object] the pre-trained model. This helps the model "unlearn" the information it had previously learned.
The GAN models consist of two pairs of generators and discriminators. The generator-discriminator pairs generate synthetic data for the "retain" and "forget" datasets. Then, the pre-trained model is used to get the class labels of the synthetic datasets. The class labels of the synthetic and original "forget" datasets are inverted. Finally, all the combined datasets are used to fine-tune the pre-trained model, resulting in the unlearned model.
The researchers conducted experiments on the [object Object] and tested the unlearned models using [object Object]. The inverted class labels procedure and synthetically generated data helped the model outperform state-of-the-art models and other standard unlearning classifiers.
Critical Analysis
The paper presents a novel and interesting approach to machine unlearning, which is an important topic in machine learning as models are often trained on sensitive data that needs to be forgotten. The use of GAN-based models to generate synthetic data with inverted class labels is a clever way to help the model unlearn specific information.
However, the paper does not address some potential limitations or areas for further research. For example, the effectiveness of this approach may depend on the quality and diversity of the synthetic data generated by the GANs, which can be challenging to achieve in practice. Additionally, the impact of the inverted class labels on the model's performance and generalization capabilities could be further investigated.
It would also be valuable to understand how this approach compares to other machine unlearning techniques, such as [object Object] or [object Object], in terms of their effectiveness, efficiency, and practical considerations.
Conclusion
This paper presents a novel machine unlearning approach that utilizes multiple GAN-based models. The key idea is to use synthetic data with inverted class labels to help the model unlearn specific information it has learned. The researchers demonstrate the effectiveness of this approach on the CIFAR-10 dataset and show that it outperforms other state-of-the-art unlearning methods.
While the paper introduces an interesting and promising technique, there are still some potential limitations and areas for further research that could be explored. Overall, this work contributes to the growing field of machine unlearning, which is crucial for developing AI systems that can safely and effectively forget sensitive or outdated information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Machine Unlearning using a Multi-GAN based Model
Amartya Hatua, Trung T. Nguyen, Andrew H. Sung
This article presents a new machine unlearning approach that utilizes multiple Generative Adversarial Network (GAN) based models. The proposed method comprises two phases: i) data reorganization in which synthetic data using the GAN model is introduced with inverted class labels of the forget datasets, and ii) fine-tuning the pre-trained model. The GAN models consist of two pairs of generators and discriminators. The generator discriminator pairs generate synthetic data for the retain and forget datasets. Then, a pre-trained model is utilized to get the class labels of the synthetic datasets. The class labels of synthetic and original forget datasets are inverted. Finally, all combined datasets are used to fine-tune the pre-trained model to get the unlearned model. We have performed the experiments on the CIFAR-10 dataset and tested the unlearned models using Membership Inference Attacks (MIA). The inverted class labels procedure and synthetically generated data help to acquire valuable information that enables the model to outperform state-of-the-art models and other standard unlearning classifiers.
Read more7/29/2024
0
Adversarial Machine Unlearning
Zonglin Di, Sixie Yu, Yevgeniy Vorobeychik, Yang Liu
This paper focuses on the challenge of machine unlearning, aiming to remove the influence of specific training data on machine learning models. Traditionally, the development of unlearning algorithms runs parallel with that of membership inference attacks (MIA), a type of privacy threat to determine whether a data instance was used for training. However, the two strands are intimately connected: one can view machine unlearning through the lens of MIA success with respect to removed data. Recognizing this connection, we propose a game-theoretic framework that integrates MIAs into the design of unlearning algorithms. Specifically, we model the unlearning problem as a Stackelberg game in which an unlearner strives to unlearn specific training data from a model, while an auditor employs MIAs to detect the traces of the ostensibly removed data. Adopting this adversarial perspective allows the utilization of new attack advancements, facilitating the design of unlearning algorithms. Our framework stands out in two ways. First, it takes an adversarial approach and proactively incorporates the attacks into the design of unlearning algorithms. Secondly, it uses implicit differentiation to obtain the gradients that limit the attacker's success, thus benefiting the process of unlearning. We present empirical results to demonstrate the effectiveness of the proposed approach for machine unlearning.
Read more6/13/2024
0
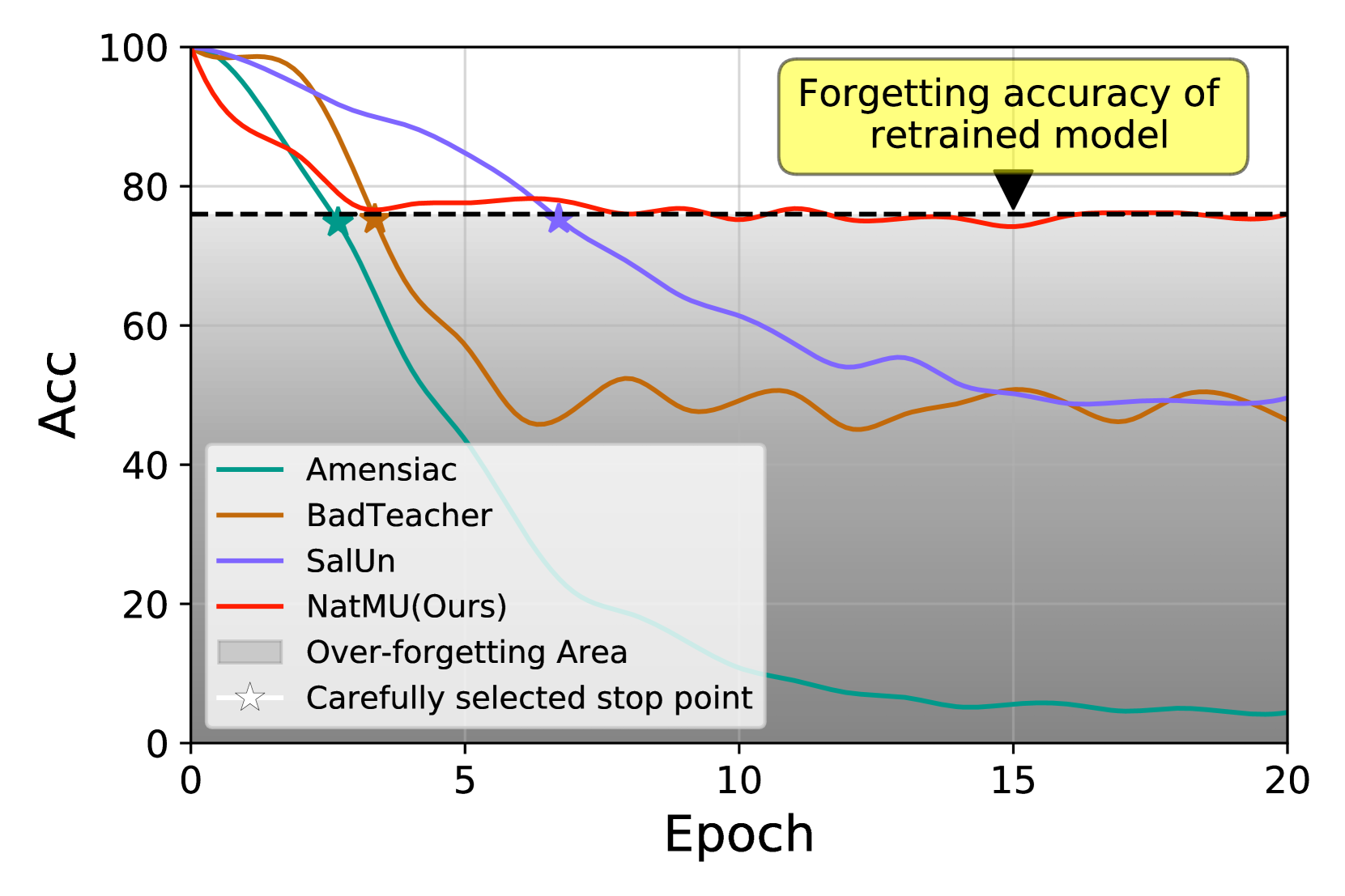
Towards Natural Machine Unlearning
Zhengbao He, Tao Li, Xinwen Cheng, Zhehao Huang, Xiaolin Huang
Machine unlearning (MU) aims to eliminate information that has been learned from specific training data, namely forgetting data, from a pre-trained model. Currently, the mainstream of existing MU methods involves modifying the forgetting data with incorrect labels and subsequently fine-tuning the model. While learning such incorrect information can indeed remove knowledge, the process is quite unnatural as the unlearning process undesirably reinforces the incorrect information and leads to over-forgetting. Towards more textit{natural} machine unlearning, we inject correct information from the remaining data to the forgetting samples when changing their labels. Through pairing these adjusted samples with their labels, the model will tend to use the injected correct information and naturally suppress the information meant to be forgotten. Albeit straightforward, such a first step towards natural machine unlearning can significantly outperform current state-of-the-art approaches. In particular, our method substantially reduces the over-forgetting and leads to strong robustness to hyperparameters, making it a promising candidate for practical machine unlearning.
Read more5/27/2024

0
Learn while Unlearn: An Iterative Unlearning Framework for Generative Language Models
Haoyu Tang, Ye Liu, Xukai Liu, Kai Zhang, Yanghai Zhang, Qi Liu, Enhong Chen
Recent advancements in machine learning, especially in Natural Language Processing (NLP), have led to the development of sophisticated models trained on vast datasets, but this progress has raised concerns about potential sensitive information leakage. In response, regulatory measures like the EU General Data Protection Regulation (GDPR) have driven the exploration of Machine Unlearning techniques, which aim to enable models to selectively forget certain data entries. While early approaches focused on pre-processing methods, recent research has shifted towards training-based machine unlearning methods. However, many existing methods require access to original training data, posing challenges in scenarios where such data is unavailable. Besides, directly facilitating unlearning may undermine the language model's general expressive ability. To this end, in this paper, we introduce the Iterative Contrastive Unlearning (ICU) framework, which addresses these challenges by incorporating three key components. We propose a Knowledge Unlearning Induction module for unlearning specific target sequences and a Contrastive Learning Enhancement module to prevent degrading in generation capacity. Additionally, an Iterative Unlearning Refinement module is integrated to make the process more adaptive to each target sample respectively. Experimental results demonstrate the efficacy of ICU in maintaining performance while efficiently unlearning sensitive information, offering a promising avenue for privacy-conscious machine learning applications.
Read more7/31/2024