MagicID: Flexible ID Fidelity Generation System

0

Sign in to get full access
Overview
- Introduces MagicID, a flexible system for generating ID images with customizable fidelity
- Aims to enable personalized identity generation for applications like digital avatars
- Leverages a multi-modal network to generate high-quality ID images from diverse inputs
Plain English Explanation
MagicID is a system that can create personalized ID images, like digital avatars, by combining different types of information. It uses a multi-modal neural network, which means it can take in various inputs - like photos, text descriptions, or biometric data - and generate a realistic-looking ID image.
This allows for more flexibility and customization compared to traditional ID generation methods. For example, someone could create a digital version of themselves with specific features or styles. The system is designed to work well with a wide range of input data, so it can generate IDs that look natural and believable.
The key benefit of MagicID is that it gives users more control over their digital identities. Rather than being limited to standard ID photos, people can create personalized IDs that reflect their unique preferences and characteristics. This could be useful for things like virtual avatars, digital credentials, or other applications where a customized ID is desirable.
Technical Explanation
MagicID is a multi-modal deep learning framework for generating high-fidelity ID images from diverse inputs. The system takes in a combination of modalities, such as facial photos, textual descriptions, and biometric data, and uses a neural network to produce a realistic ID image.
The core of MagicID is a cross-modal encoder-decoder architecture. The encoder component learns to extract relevant features from the input data, while the decoder generates the output ID image. This allows the system to effectively combine information from different modalities to create the final ID.
Extensive experiments are conducted to evaluate MagicID's performance on a range of ID generation tasks. The results demonstrate the system's ability to produce high-quality ID images that closely match the input characteristics, outperforming previous methods. MagicID also exhibits strong generalization capabilities, handling diverse input data with consistency.
Critical Analysis
The paper provides a thorough technical explanation of the MagicID system and its capabilities. However, it does not fully address some potential limitations or concerns:
- The system's reliance on a multi-modal approach may introduce additional complexity and potential points of failure compared to single-modal ID generation methods.
- The paper does not discuss the ethical implications of enabling highly customizable digital identities, such as potential misuse or privacy concerns.
- The evaluation focuses on quantitative metrics, but more user-centric assessments of the generated IDs' realism and acceptability could provide valuable insights.
Further research could explore ways to mitigate these issues, such as developing robust safeguards or exploring user perceptions of personalized ID systems. Additionally, investigating the long-term societal impacts of such technologies would be beneficial.
Conclusion
MagicID presents a novel approach to ID image generation that leverages multi-modal deep learning to enable flexible and customizable digital identities. By combining diverse inputs, the system can produce high-fidelity ID images that closely match user preferences and characteristics.
This technology has the potential to revolutionize various applications, from virtual avatars to digital credentials, by empowering users to create personalized digital representations of themselves. However, it also raises important questions about the ethical and social implications of such advancements.
As the field of AI-generated identities continues to evolve, ongoing research and thoughtful discourse will be crucial to ensure these technologies are developed and deployed responsibly, balancing personalization and user autonomy with appropriate safeguards and considerations for the broader societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MagicID: Flexible ID Fidelity Generation System
Zhaoli Deng, Wen Liu, Fanyi Wang, Junkang Zhang, Fan Chen, Meng Zhang, Wendong Zhang, Zhenpeng Mi
Portrait Fidelity Generation is a prominent research area in generative models, with a primary focus on enhancing both controllability and fidelity. Current methods face challenges in generating high-fidelity portrait results when faces occupy a small portion of the image with a low resolution, especially in multi-person group photo settings. To tackle these issues, we propose a systematic solution called MagicID, based on a self-constructed million-level multi-modal dataset named IDZoom. MagicID consists of Multi-Mode Fusion training strategy (MMF) and DDIM Inversion based ID Restoration inference framework (DIIR). During training, MMF iteratively uses the skeleton and landmark modalities from IDZoom as conditional guidance. By introducing the Clone Face Tuning in training stage and Mask Guided Multi-ID Cross Attention (MGMICA) in inference stage, explicit constraints on face positional features are achieved for multi-ID group photo generation. The DIIR aims to address the issue of artifacts. The DDIM Inversion is used in conjunction with face landmarks, global and local face features to achieve face restoration while keeping the background unchanged. Additionally, DIIR is plug-and-play and can be applied to any diffusion-based portrait generation method. To validate the effectiveness of MagicID, we conducted extensive comparative and ablation experiments. The experimental results demonstrate that MagicID has significant advantages in both subjective and objective metrics, and achieves controllable generation in multi-person scenarios.
Read more8/21/2024
0
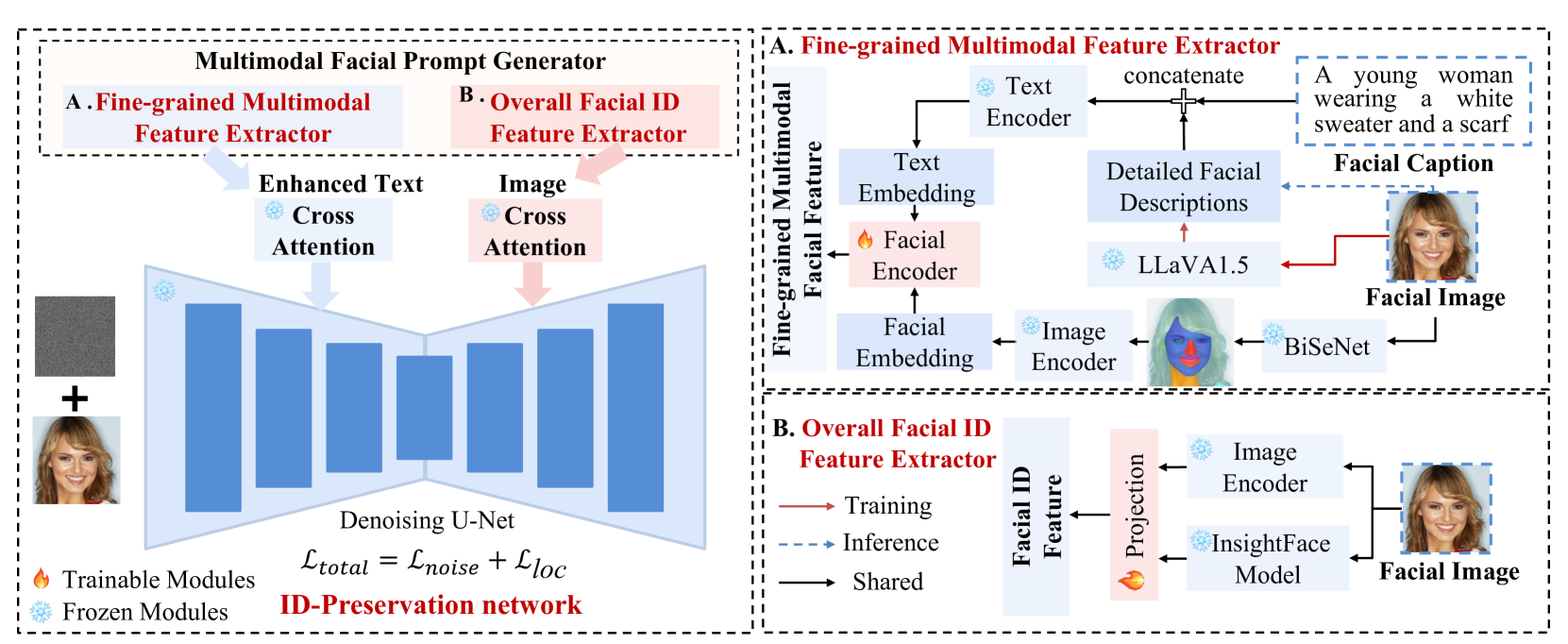
ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving
Jiehui Huang, Xiao Dong, Wenhui Song, Hanhui Li, Jun Zhou, Yuhao Cheng, Shutao Liao, Long Chen, Yiqiang Yan, Shengcai Liao, Xiaodan Liang
Diffusion-based technologies have made significant strides, particularly in personalized and customized facialgeneration. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face. To address these limitations, we introduce ConsistentID, an innovative method crafted for diverseidentity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image. ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consistency in facial regions. Together, these components significantly enhance the accuracy of ID preservation by introducing fine-grained multimodal ID information from facial regions. To facilitate training of ConsistentID, we present a fine-grained portrait dataset, FGID, with over 500,000 facial images, offering greater diversity and comprehensiveness than existing public facial datasets. % such as LAION-Face, CelebA, FFHQ, and SFHQ. Experimental results substantiate that our ConsistentID achieves exceptional precision and diversity in personalized facial generation, surpassing existing methods in the MyStyle dataset. Furthermore, while ConsistentID introduces more multimodal ID information, it maintains a fast inference speed during generation.
Read more4/26/2024
🖼️
0
MagicStyle: Portrait Stylization Based on Reference Image
Zhaoli Deng, Kaibin Zhou, Fanyi Wang, Zhenpeng Mi
The development of diffusion models has significantly advanced the research on image stylization, particularly in the area of stylizing a content image based on a given style image, which has attracted many scholars. The main challenge in this reference image stylization task lies in how to maintain the details of the content image while incorporating the color and texture features of the style image. This challenge becomes even more pronounced when the content image is a portrait which has complex textural details. To address this challenge, we propose a diffusion model-based reference image stylization method specifically for portraits, called MagicStyle. MagicStyle consists of two phases: Content and Style DDIM Inversion (CSDI) and Feature Fusion Forward (FFF). The CSDI phase involves a reverse denoising process, where DDIM Inversion is performed separately on the content image and the style image, storing the self-attention query, key and value features of both images during the inversion process. The FFF phase executes forward denoising, harmoniously integrating the texture and color information from the pre-stored feature queries, keys and values into the diffusion generation process based on our Well-designed Feature Fusion Attention (FFA). We conducted comprehensive comparative and ablation experiments to validate the effectiveness of our proposed MagicStyle and FFA.
Read more9/14/2024
❗
0
MagicPose: Realistic Human Poses and Facial Expressions Retargeting with Identity-aware Diffusion
Di Chang, Yichun Shi, Quankai Gao, Jessica Fu, Hongyi Xu, Guoxian Song, Qing Yan, Yizhe Zhu, Xiao Yang, Mohammad Soleymani
In this work, we propose MagicPose, a diffusion-based model for 2D human pose and facial expression retargeting. Specifically, given a reference image, we aim to generate a person's new images by controlling the poses and facial expressions while keeping the identity unchanged. To this end, we propose a two-stage training strategy to disentangle human motions and appearance (e.g., facial expressions, skin tone and dressing), consisting of (1) the pre-training of an appearance-control block and (2) learning appearance-disentangled pose control. Our novel design enables robust appearance control over generated human images, including body, facial attributes, and even background. By leveraging the prior knowledge of image diffusion models, MagicPose generalizes well to unseen human identities and complex poses without the need for additional fine-tuning. Moreover, the proposed model is easy to use and can be considered as a plug-in module/extension to Stable Diffusion. The code is available at: https://github.com/Boese0601/MagicDance
Read more5/7/2024