ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving

0
Sign in to get full access
Overview
- This paper proposes a novel approach called "ConsistentID" for generating portrait images with fine-grained identity preservation.
- The method leverages multimodal inputs, including text, image, and 3D facial scans, to capture a subject's identity and generate consistent portraits across different expressions, poses, and styles.
- The authors demonstrate the effectiveness of their approach through extensive experiments and comparisons to state-of-the-art methods.
Plain English Explanation
The paper introduces a new way to generate portrait images that maintain a person's unique identity, even when the portrait is altered to show different expressions, poses, or styles. The key innovation is the use of multiple types of input data, including text descriptions, existing images, and 3D scans of the person's face. By combining these diverse sources of information, the system can capture the individual's identity more accurately and generate portraits that look consistent with that identity, no matter how the portrait is changed.
This is important because previous portrait generation methods often struggled to preserve the subject's identity when significant changes were made to the image. The ConsistentID approach aims to solve this problem, allowing for more flexible and personalized portrait generation that maintains a strong connection to the original individual.
Technical Explanation
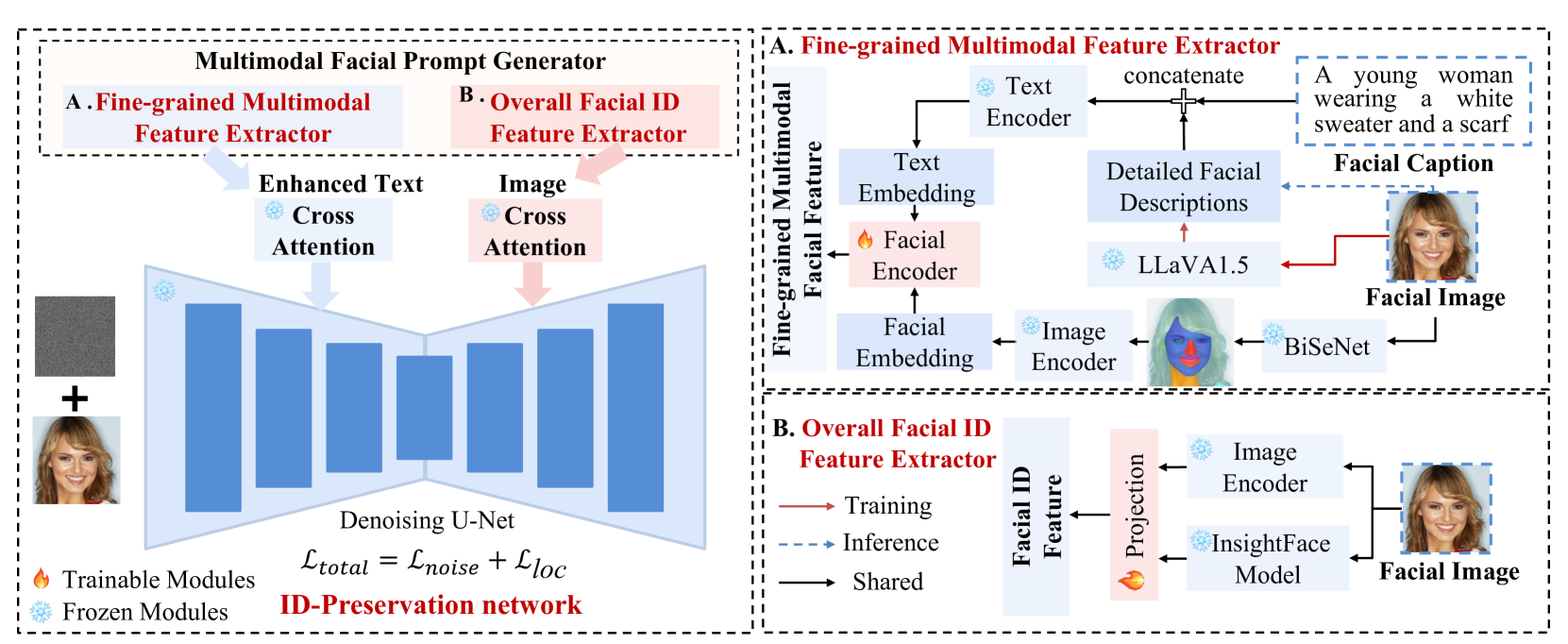
The ConsistentID model takes in a combination of text, images, and 3D facial scans as input, and uses this multimodal information to generate portrait images that preserve the subject's identity. The text provides a high-level description of the person, the images offer visual examples, and the 3D scans capture precise details about the facial structure.
The architecture of the model includes several key components:
- A multimodal feature extractor that encodes the diverse input data into a unified representation.
- A portrait generation module that uses this combined representation to produce the output portrait image.
- An identity preservation module that ensures the generated portrait maintains the subject's unique identity.
Through extensive experiments, the authors demonstrate that ConsistentID outperforms previous state-of-the-art methods in preserving identity across a wide range of portrait variations, including changes to expression, pose, and style. The universally-applicable fingerprinting approach developed in this work also shows promise for other applications that require consistent identity representation.
Critical Analysis
The paper presents a well-designed and thorough study, with robust experimental evaluations to support the claims. However, there are a few potential limitations and areas for further research:
- The reliance on 3D facial scans as input data may limit the practical applicability of the method, as such scans are not always readily available.
- The paper does not explore the use of this approach for generating animated or video-based portraits, which could be an interesting direction for future work.
- While the identity preservation capabilities are impressive, the paper does not delve into potential ethical concerns around the creation of highly realistic and personalized portrait images.
Overall, the ConsistentID method represents a significant advance in the field of portrait generation, with the potential to enable more flexible and personalized visual representations while preserving individual identity. Further research to address the limitations and explore additional applications would be valuable.
Conclusion
The ConsistentID approach proposed in this paper offers a novel solution for generating portrait images that maintain a subject's unique identity, even with changes to expression, pose, and style. By leveraging multimodal input data, including text, images, and 3D facial scans, the model is able to capture fine-grained details about the individual and produce consistent portraits that preserve their identity. This work represents an important step forward in the field of portrait generation and has the potential to enable more personalized and flexible visual representations with strong identity preservation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving
Jiehui Huang, Xiao Dong, Wenhui Song, Hanhui Li, Jun Zhou, Yuhao Cheng, Shutao Liao, Long Chen, Yiqiang Yan, Shengcai Liao, Xiaodan Liang
Diffusion-based technologies have made significant strides, particularly in personalized and customized facialgeneration. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face. To address these limitations, we introduce ConsistentID, an innovative method crafted for diverseidentity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image. ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consistency in facial regions. Together, these components significantly enhance the accuracy of ID preservation by introducing fine-grained multimodal ID information from facial regions. To facilitate training of ConsistentID, we present a fine-grained portrait dataset, FGID, with over 500,000 facial images, offering greater diversity and comprehensiveness than existing public facial datasets. % such as LAION-Face, CelebA, FFHQ, and SFHQ. Experimental results substantiate that our ConsistentID achieves exceptional precision and diversity in personalized facial generation, surpassing existing methods in the MyStyle dataset. Furthermore, while ConsistentID introduces more multimodal ID information, it maintains a fast inference speed during generation.
Read more4/26/2024

0
MagicID: Flexible ID Fidelity Generation System
Zhaoli Deng, Wen Liu, Fanyi Wang, Junkang Zhang, Fan Chen, Meng Zhang, Wendong Zhang, Zhenpeng Mi
Portrait Fidelity Generation is a prominent research area in generative models, with a primary focus on enhancing both controllability and fidelity. Current methods face challenges in generating high-fidelity portrait results when faces occupy a small portion of the image with a low resolution, especially in multi-person group photo settings. To tackle these issues, we propose a systematic solution called MagicID, based on a self-constructed million-level multi-modal dataset named IDZoom. MagicID consists of Multi-Mode Fusion training strategy (MMF) and DDIM Inversion based ID Restoration inference framework (DIIR). During training, MMF iteratively uses the skeleton and landmark modalities from IDZoom as conditional guidance. By introducing the Clone Face Tuning in training stage and Mask Guided Multi-ID Cross Attention (MGMICA) in inference stage, explicit constraints on face positional features are achieved for multi-ID group photo generation. The DIIR aims to address the issue of artifacts. The DDIM Inversion is used in conjunction with face landmarks, global and local face features to achieve face restoration while keeping the background unchanged. Additionally, DIIR is plug-and-play and can be applied to any diffusion-based portrait generation method. To validate the effectiveness of MagicID, we conducted extensive comparative and ablation experiments. The experimental results demonstrate that MagicID has significant advantages in both subjective and objective metrics, and achieves controllable generation in multi-person scenarios.
Read more8/21/2024

0
UniPortrait: A Unified Framework for Identity-Preserving Single- and Multi-Human Image Personalization
Junjie He, Yifeng Geng, Liefeng Bo
This paper presents UniPortrait, an innovative human image personalization framework that unifies single- and multi-ID customization with high face fidelity, extensive facial editability, free-form input description, and diverse layout generation. UniPortrait consists of only two plug-and-play modules: an ID embedding module and an ID routing module. The ID embedding module extracts versatile editable facial features with a decoupling strategy for each ID and embeds them into the context space of diffusion models. The ID routing module then combines and distributes these embeddings adaptively to their respective regions within the synthesized image, achieving the customization of single and multiple IDs. With a carefully designed two-stage training scheme, UniPortrait achieves superior performance in both single- and multi-ID customization. Quantitative and qualitative experiments demonstrate the advantages of our method over existing approaches as well as its good scalability, e.g., the universal compatibility with existing generative control tools. The project page is at https://aigcdesigngroup.github.io/UniPortrait-Page/ .
Read more9/9/2024
🛸
0
Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
Renshuai Liu, Bowen Ma, Wei Zhang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Xuan Cheng
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
Read more4/9/2024