Magnetic Resonance Image Processing Transformer for General Reconstruction

0
🖼️
Sign in to get full access
Overview
- This paper proposes a deep learning model called Magnetic Resonance Image Processing Transformer (MR-IPT) for accelerated MRI reconstruction.
- MR-IPT is a transformer-based model that includes multi-head-tails and a single shared window transformer main body.
- The model was pre-trained on a large MRI dataset and then evaluated on the fastMRI knee dataset for downstream reconstruction tasks.
- The performance of MR-IPT was compared to conventional CNN-based networks in zero-shot and few-shot learning scenarios.
Plain English Explanation
The researchers developed a deep learning model called the Magnetic Resonance Image Processing Transformer (MR-IPT) to speed up the process of generating high-quality medical images from MRI scans. MRI scans can take a long time to complete, and this model aims to reduce the time required while maintaining the accuracy of the images.
The MR-IPT model is based on a type of deep learning called a transformer, which is a powerful technique for processing and generating sequential data, such as text or images. The model includes several key components, including "multi-head-tails" and a "single shared window transformer main body," which help it process MRI data efficiently.
To train the model, the researchers used a large dataset of MRI images from RadImageNet, which includes over 600,000 images covering multiple anatomical regions. They then tested the model on a dataset of knee MRI scans from the fastMRI project.
The researchers compared the performance of the MR-IPT model to more traditional convolutional neural network (CNN) models, both in situations where the model had a lot of training data (few-shot learning) and where it had very little training data (zero-shot learning). In both cases, the MR-IPT model outperformed the CNN-based models, suggesting that its transformer-based architecture and large-scale pre-training give it an advantage in medical image reconstruction tasks.
Technical Explanation
The researchers developed the Magnetic Resonance Image Processing Transformer (MR-IPT) model, which is a deep learning model based on transformer architecture. The model includes several key components, including "multi-head-tails" and a "single shared window transformer main body," which are designed to efficiently process MRI data.
To train the model, the researchers used a large dataset of MRI images from RadImageNet, which includes over 600,000 images covering multiple anatomical regions. They then tested the model on a dataset of knee MRI scans from the fastMRI project.
The researchers compared the performance of the MR-IPT model to more traditional convolutional neural network (CNN) models, both in situations where the model had a lot of training data (few-shot learning) and where it had very little training data (zero-shot learning). In the few-shot learning scenario, the MR-IPT model achieved a PSNR (Peak Signal-to-Noise Ratio) of 26.521 and an SSIM (Structural Similarity Index) of 0.6102 for 4-fold acceleration, and a PSNR of 24.861 and an SSIM of 0.4996 for 8-fold acceleration. These results surpassed the performance of the UNet128 CNN model, which achieved a PSNR of 25.056 and an SSIM of 0.5832 for 4-fold acceleration, and a PSNR of 22.984 and an SSIM of 0.4637 for 8-fold acceleration.
In the zero-shot learning scenario, where the models were tested on a dataset with very little training data, the MR-IPT model still outperformed the CNN-based models, providing a 5% performance boost compared to UNet128 in 8-fold acceleration and a 3% boost in 4-fold acceleration.
The researchers also evaluated the stability of the MR-IPT model by testing it on downstream datasets of varying sizes, ranging from 10 to 2500 images. This analysis showed that the MR-IPT model maintained its superior performance compared to the CNN-based models across these different dataset sizes.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the MR-IPT model for accelerated MRI reconstruction. The researchers have done a commendable job of comparing the performance of their model to conventional CNN-based networks in both zero-shot and few-shot learning scenarios, which provides valuable insights into the generalizability and robustness of the MR-IPT approach.
One potential limitation of the study is that it only evaluates the model's performance on the fastMRI knee dataset, which may not be representative of all types of MRI scans. It would be interesting to see how the MR-IPT model performs on a more diverse range of MRI data, such as brain, abdominal, or cardiac scans.
Additionally, the paper does not provide much detailed information about the specific architectural choices and training procedures used for the MR-IPT model. More transparency in these areas would allow other researchers to better understand the key factors contributing to the model's superior performance.
Overall, this research represents a significant advancement in the field of accelerated MRI reconstruction and suggests that transformer-based models like MR-IPT could be a promising direction for further exploration and development.
Conclusion
The Magnetic Resonance Image Processing Transformer (MR-IPT) model developed in this paper demonstrates the potential of transformer-based architectures for accelerated MRI reconstruction. The model's superior performance compared to conventional CNN-based networks, in both zero-shot and few-shot learning scenarios, highlights the benefits of its transformer-based structure and large-scale pre-training.
The findings of this research suggest that the MR-IPT framework could serve as a solid backbone for other downstream medical imaging tasks, leveraging its ability to effectively learn and generalize from limited data. As the field of medical imaging continues to evolve, innovations like the MR-IPT model will be crucial in improving the efficiency and accuracy of diagnostic tools, ultimately leading to better patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Magnetic Resonance Image Processing Transformer for General Reconstruction
Guoyao Shen, Mengyu Li, Stephan Anderson, Chad W. Farris, Xin Zhang
Purpose: To develop and evaluate a deep learning model for general accelerated MRI reconstruction. Materials and Methods: This retrospective study built a magnetic resonance image processing transformer (MR-IPT) which includes multi-head-tails and a single shared window transformer main body. Three mutations of MR-IPT with different transformer structures were implemented to guide the design of our MR-IPT model. Pre-trained on the MRI set of RadImageNet including 672675 images with multiple anatomy categories, the model was further migrated and evaluated on fastMRI knee dataset with 25012 images for downstream reconstruction tasks. We performed comparison studies with three CNN-based conventional networks in zero- and few-shot learning scenarios. Transfer learning process was conducted on both MR-IPT and CNN networks to further validate the generalizability of MR-IPT. To study the model performance stability, we evaluated our model with various downstream dataset sizes ranging from 10 to 2500 images. Result: The MR-IPT model provided superior performance in multiple downstream tasks compared to conventional CNN networks. MR-IPT achieved a PSNR/SSIM of 26.521/0.6102 (4-fold) and 24.861/0.4996 (8-fold) in 10-epoch learning, surpassing UNet128 at 25.056/0.5832 (4-fold) and 22.984/0.4637 (8-fold). With the same large-scale pre-training, MR-IPT provided a 5% performance boost compared to UNet128 in zero-shot learning in 8-fold and 3% in 4-fold. Conclusion: MR-IPT framework benefits from its transformer-based structure and large-scale pre-training and can serve as a solid backbone in other downstream tasks with zero- and few-shot learning.
Read more5/27/2024
0
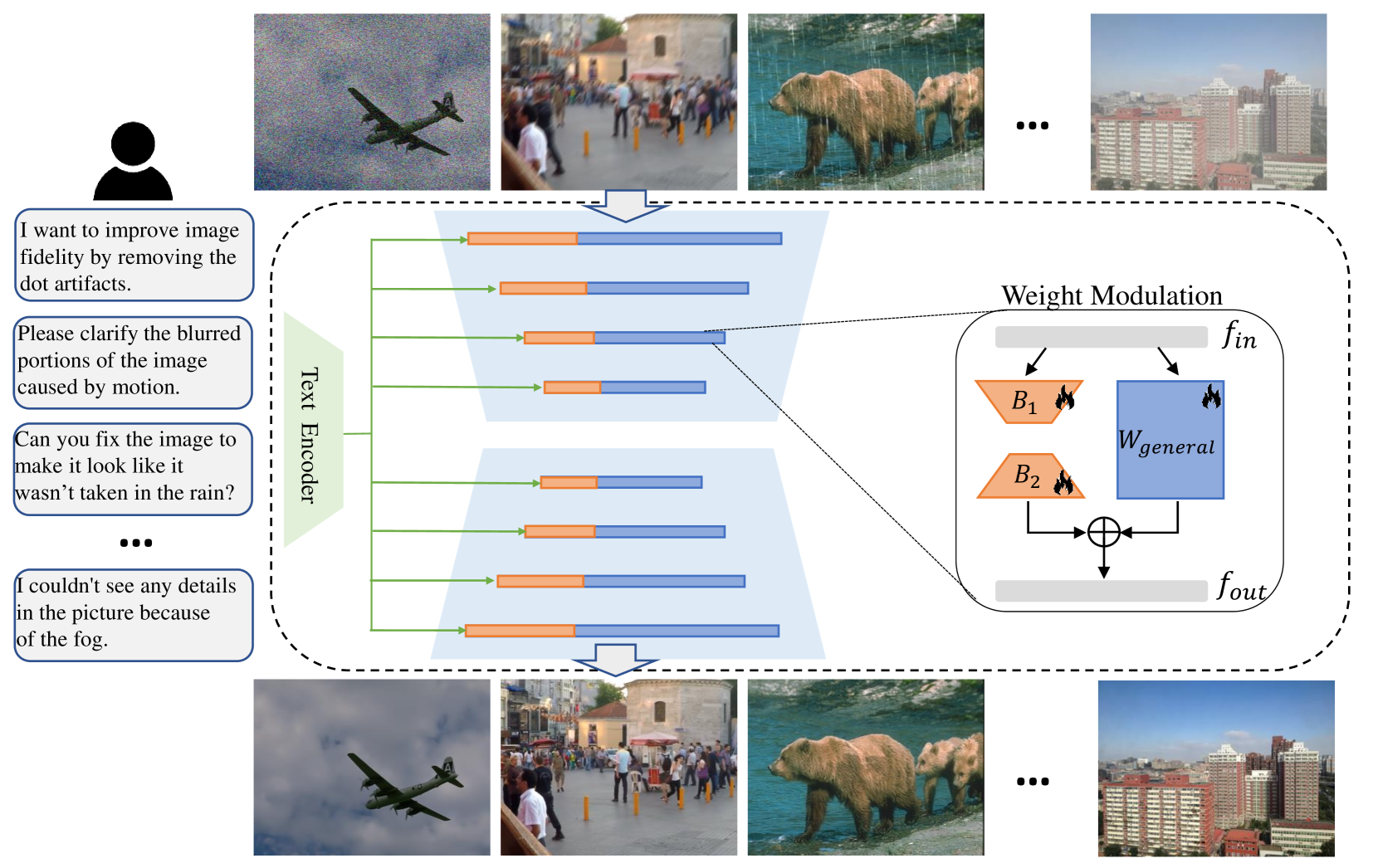
Instruct-IPT: All-in-One Image Processing Transformer via Weight Modulation
Yuchuan Tian, Jianhong Han, Hanting Chen, Yuanyuan Xi, Guoyang Zhang, Jie Hu, Chao Xu, Yunhe Wang
Due to the unaffordable size and intensive computation costs of low-level vision models, All-in-One models that are designed to address a handful of low-level vision tasks simultaneously have been popular. However, existing All-in-One models are limited in terms of the range of tasks and performance. To overcome these limitations, we propose Instruct-IPT -- an All-in-One Image Processing Transformer that could effectively address manifold image restoration tasks with large inter-task gaps, such as denoising, deblurring, deraining, dehazing, and desnowing. Rather than popular feature adaptation methods, we propose weight modulation that adapts weights to specific tasks. Firstly, we figure out task-sensitive weights via a toy experiment and introduce task-specific biases on top of them. Secondly, we conduct rank analysis for a good compression strategy and perform low-rank decomposition on the biases. Thirdly, we propose synchronous training that updates the task-general backbone model and the task-specific biases simultaneously. In this way, the model is instructed to learn general and task-specific knowledge. Via our simple yet effective method that instructs the IPT to be task experts, Instruct-IPT could better cooperate between tasks with distinct characteristics at humble costs. Further, we propose to maneuver Instruct-IPT with text instructions for better user interfaces. We have conducted experiments on Instruct-IPT to demonstrate the effectiveness of our method on manifold tasks, and we have effectively extended our method to diffusion denoisers as well. The code is available at https://github.com/huawei-noah/Pretrained-IPT.
Read more7/2/2024
🎯
0
Imaging transformer for MRI denoising with the SNR unit training: enabling generalization across field-strengths, imaging contrasts, and anatomy
Hui Xue, Sarah Hooper, Azaan Rehman, Iain Pierce, Thomas Treibel, Rhodri Davies, W Patricia Bandettini, Rajiv Ramasawmy, Ahsan Javed, Zheren Zhu, Yang Yang, James Moon, Adrienne Campbell, Peter Kellman
The ability to recover MRI signal from noise is key to achieve fast acquisition, accurate quantification, and high image quality. Past work has shown convolutional neural networks can be used with abundant and paired low and high-SNR images for training. However, for applications where high-SNR data is difficult to produce at scale (e.g. with aggressive acceleration, high resolution, or low field strength), training a new denoising network using a large quantity of high-SNR images can be infeasible. In this study, we overcome this limitation by improving the generalization of denoising models, enabling application to many settings beyond what appears in the training data. Specifically, we a) develop a training scheme that uses complex MRIs reconstructed in the SNR units (i.e., the images have a fixed noise level, SNR unit training) and augments images with realistic noise based on coil g-factor, and b) develop a novel imaging transformer (imformer) to handle 2D, 2D+T, and 3D MRIs in one model architecture. Through empirical evaluation, we show this combination improves performance compared to CNN models and improves generalization, enabling a denoising model to be used across field-strengths, image contrasts, and anatomy.
Read more4/4/2024
0
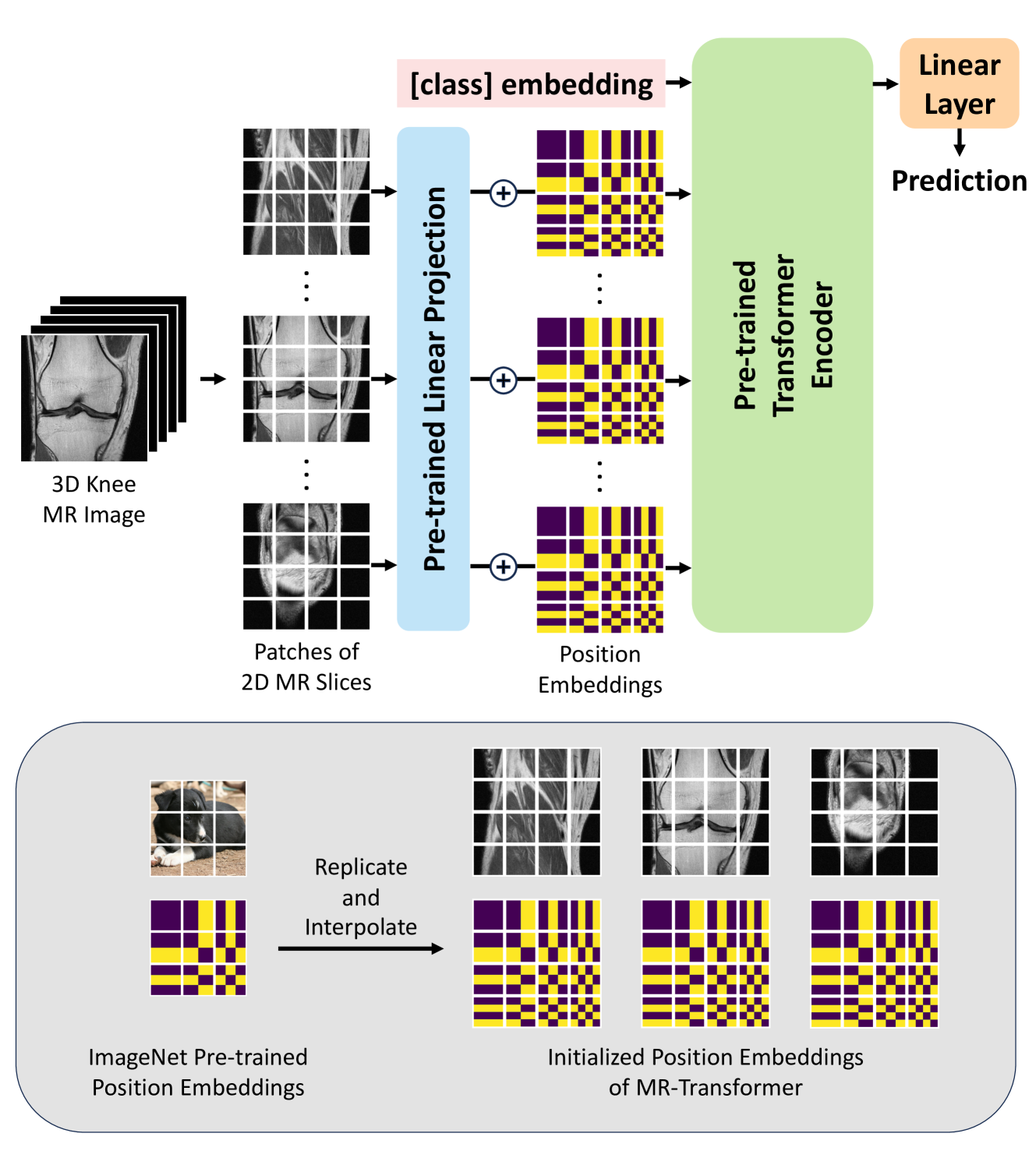
MR-Transformer: Vision Transformer for Total Knee Replacement Prediction Using Magnetic Resonance Imaging
Chaojie Zhang, Shengjia Chen, Ozkan Cigdem, Haresh Rengaraj Rajamohan, Kyunghyun Cho, Richard Kijowski, Cem M. Deniz
A transformer-based deep learning model, MR-Transformer, was developed for total knee replacement (TKR) prediction using magnetic resonance imaging (MRI). The model incorporates the ImageNet pre-training and captures three-dimensional (3D) spatial correlation from the MR images. The performance of the proposed model was compared to existing state-of-the-art deep learning models for knee injury diagnosis using MRI. Knee MR scans of four different tissue contrasts from the Osteoarthritis Initiative and Multicenter Osteoarthritis Study databases were utilized in the study. Experimental results demonstrated the state-of-the-art performance of the proposed model on TKR prediction using MRI.
Read more5/7/2024