MAiDE-up: Multilingual Deception Detection of GPT-generated Hotel Reviews
2404.12938
0
0
🔎
Abstract
Deceptive reviews are becoming increasingly common, especially given the increase in performance and the prevalence of LLMs. While work to date has addressed the development of models to differentiate between truthful and deceptive human reviews, much less is known about the distinction between real reviews and AI-authored fake reviews. Moreover, most of the research so far has focused primarily on English, with very little work dedicated to other languages. In this paper, we compile and make publicly available the MAiDE-up dataset, consisting of 10,000 real and 10,000 AI-generated fake hotel reviews, balanced across ten languages. Using this dataset, we conduct extensive linguistic analyses to (1) compare the AI fake hotel reviews to real hotel reviews, and (2) identify the factors that influence the deception detection model performance. We explore the effectiveness of several models for deception detection in hotel reviews across three main dimensions: sentiment, location, and language. We find that these dimensions influence how well we can detect AI-generated fake reviews.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Deceptive reviews, including those generated by AI, are becoming more common as language models improve.
- The research aims to analyze the differences between real and AI-generated fake hotel reviews, and to identify factors affecting the detection of deceptive reviews.
- The authors compiled a new dataset, MAiDE-up, consisting of 10,000 real and 10,000 AI-generated fake hotel reviews across 10 languages.
- The study explores the effectiveness of various models for detecting deception in hotel reviews, focusing on sentiment, location, and language as key dimensions.
Plain English Explanation
The paper looks at the growing problem of deceptive reviews, which can be written by humans or generated by AI language models. While past research has focused on distinguishing truthful and deceptive human reviews, little is known about how to identify reviews written by AI as opposed to real people.
To address this, the researchers created a new dataset called MAiDE-up, which contains 10,000 real hotel reviews and 10,000 fake reviews generated by AI, across 10 different languages. They then analyzed this dataset to understand the differences between real and AI-generated reviews, and to see what factors make it easier or harder to detect deceptive reviews.
The key factors they looked at were the sentiment (positive or negative) expressed in the reviews, the locations mentioned, and the language used. By studying how these factors influence the ability to identify fake reviews, the researchers hope to develop better tools for detecting deception in online reviews.
Technical Explanation
The researchers compiled the MAiDE-up dataset, which contains 10,000 real hotel reviews and 10,000 AI-generated fake hotel reviews, balanced across 10 different languages. They used this dataset to conduct extensive linguistic analyses to (1) compare the characteristics of the AI-generated fake reviews to the real reviews, and (2) identify which factors most influence the performance of models designed to detect deceptive reviews.
The study explored the effectiveness of various machine learning models for detecting deception in hotel reviews across three main dimensions: sentiment (positive or negative), location, and language. The results showed that these dimensions do indeed impact the ability to distinguish AI-generated fake reviews from real human-written reviews.
For example, the researchers found that reviews expressing strong sentiment, whether positive or negative, were easier to identify as fake compared to more neutral reviews. Similarly, reviews mentioning obscure or unusual locations were more readily detected as AI-generated, while reviews referencing common travel destinations were more challenging to classify.
The findings suggest that the language used in fake reviews, as well as the contextual factors like sentiment and location, play a significant role in determining how effectively deception can be identified. This has important implications for developing more robust anti-spoofing and deception detection systems.
Critical Analysis
The researchers acknowledge several limitations in their study. First, the dataset they compiled, while substantial, may not fully represent the diversity of real and AI-generated reviews found in the wild. The authors note that the AI-generated reviews were created using a specific model, and the characteristics of fake reviews could differ if generated by other techniques.
Additionally, the paper focuses on textual features of the reviews, but does not explore other potentially relevant signals, such as user metadata or review timestamps. Incorporating a broader range of features into the deception detection models could lead to improved performance.
The study also does not address the potential for AI-generated reviews to become more sophisticated and harder to detect over time, as language models continue to advance. Investigating how deception detection models can adapt to evolving AI-generated content is an important area for future research.
Despite these limitations, the work provides valuable insights into the challenges of distinguishing real and AI-generated reviews, and highlights the need for ongoing research and innovation in this important field.
Conclusion
This paper takes an important step in understanding the growing problem of deceptive online reviews, particularly those generated by AI language models. By compiling a large, multilingual dataset of real and fake hotel reviews, the researchers were able to conduct a detailed analysis of the linguistic and contextual factors that influence the ability to detect deception.
The findings suggest that sentiment, location, and language all play a significant role in determining how effectively AI-generated fake reviews can be identified. This knowledge can help inform the development of more robust and adaptive deception detection systems, which will be crucial as the threat of AI-powered review manipulation continues to evolve.
Overall, this research represents an important contribution to the ongoing efforts to combat the spread of deceptive information online and maintain the integrity of user-generated content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Adapting Fake News Detection to the Era of Large Language Models
Jinyan Su, Claire Cardie, Preslav Nakov
0
0
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
4/16/2024
New!Who Writes the Review, Human or AI?
Panagiotis C. Theocharopoulos, Spiros V. Georgakopoulos, Sotiris K. Tasoulis, Vassilis P. Plagianakos
0
0
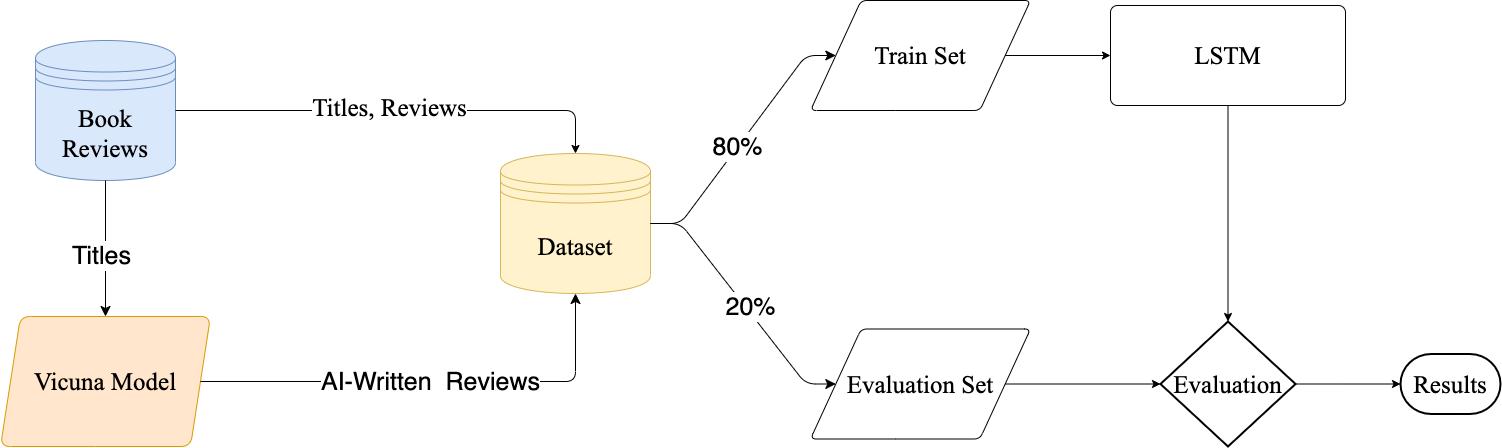
With the increasing use of Artificial Intelligence in Natural Language Processing, concerns have been raised regarding the detection of AI-generated text in various domains. This study aims to investigate this issue by proposing a methodology to accurately distinguish AI-generated and human-written book reviews. Our approach utilizes transfer learning, enabling the model to identify generated text across different topics while improving its ability to detect variations in writing style and vocabulary. To evaluate the effectiveness of the proposed methodology, we developed a dataset consisting of real book reviews and AI-generated reviews using the recently proposed Vicuna open-source language model. The experimental results demonstrate that it is feasible to detect the original source of text, achieving an accuracy rate of 96.86%. Our efforts are oriented toward the exploration of the capabilities and limitations of Large Language Models in the context of text identification. Expanding our knowledge in these aspects will be valuable for effectively navigating similar models in the future and ensuring the integrity and authenticity of human-generated content.
5/31/2024
🔎
An Assessment of Model-On-Model Deception
Julius Heitkoetter, Michael Gerovitch, Laker Newhouse
0
0
The trustworthiness of highly capable language models is put at risk when they are able to produce deceptive outputs. Moreover, when models are vulnerable to deception it undermines reliability. In this paper, we introduce a method to investigate complex, model-on-model deceptive scenarios. We create a dataset of over 10,000 misleading explanations by asking Llama-2 7B, 13B, 70B, and GPT-3.5 to justify the wrong answer for questions in the MMLU. We find that, when models read these explanations, they are all significantly deceived. Worryingly, models of all capabilities are successful at misleading others, while more capable models are only slightly better at resisting deception. We recommend the development of techniques to detect and defend against deception.
5/24/2024
🔎
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
0
0
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
5/22/2024