MaIL: Improving Imitation Learning with Mamba
2406.08234
0
0
Abstract
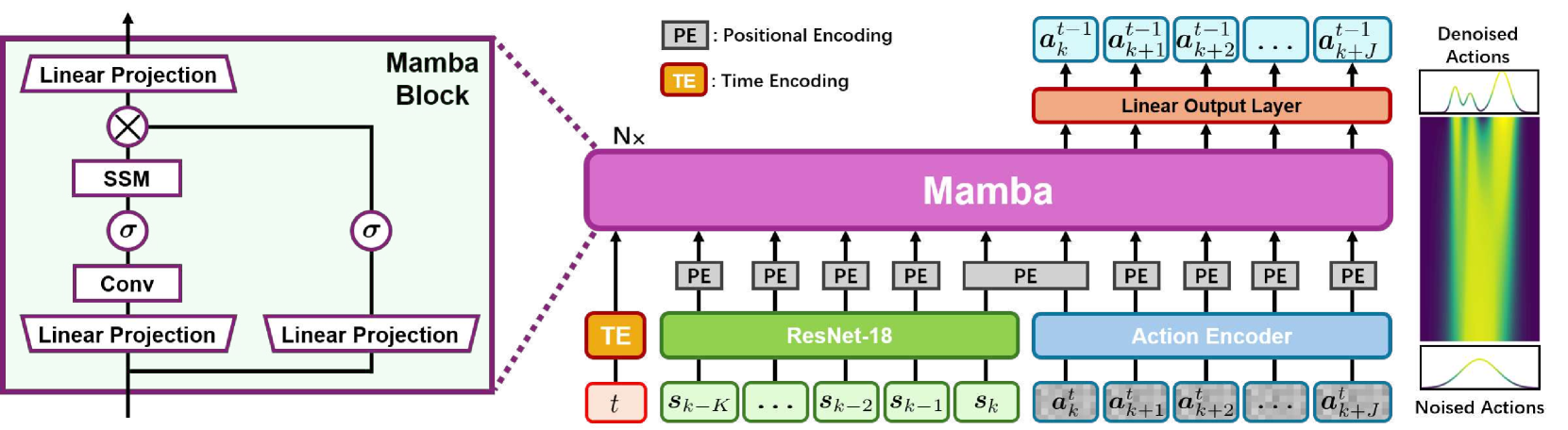
This work introduces Mamba Imitation Learning (MaIL), a novel imitation learning (IL) architecture that offers a computationally efficient alternative to state-of-the-art (SoTA) Transformer policies. Transformer-based policies have achieved remarkable results due to their ability in handling human-recorded data with inherently non-Markovian behavior. However, their high performance comes with the drawback of large models that complicate effective training. While state space models (SSMs) have been known for their efficiency, they were not able to match the performance of Transformers. Mamba significantly improves the performance of SSMs and rivals against Transformers, positioning it as an appealing alternative for IL policies. MaIL leverages Mamba as a backbone and introduces a formalism that allows using Mamba in the encoder-decoder structure. This formalism makes it a versatile architecture that can be used as a standalone policy or as part of a more advanced architecture, such as a diffuser in the diffusion process. Extensive evaluations on the LIBERO IL benchmark and three real robot experiments show that MaIL: i) outperforms Transformers in all LIBERO tasks, ii) achieves good performance even with small datasets, iii) is able to effectively process multi-modal sensory inputs, iv) is more robust to input noise compared to Transformers.
Create account to get full access
Overview
- This paper introduces MaIL, a new approach to improving imitation learning that uses a technique called "Mamba".
- Imitation learning is a machine learning method where an agent learns to perform a task by observing an expert demonstrator.
- The authors claim that MaIL can outperform existing imitation learning methods on a variety of tasks.
Plain English Explanation
The paper describes a new way to help AI systems learn tasks by watching and imitating expert demonstrations. This approach, called MaIL, uses a technique called "Mamba" to improve the learning process.
Imitation learning is when an AI system tries to mimic the behavior of a human or other expert in order to perform a task. This can be a powerful way for AI to learn, as it allows the system to leverage the knowledge and skills of the expert. However, existing imitation learning methods have some limitations.
The authors claim that their MaIL approach, which incorporates Mamba, can overcome these limitations and lead to better performance on a range of tasks. The key idea is to have the AI system not just blindly imitate the expert, but to also learn how to learn from the expert demonstrations in an intelligent way.
This builds on previous work on Mamba-based models, which have shown promise in areas like language modeling and vision. The authors adapt these Mamba techniques to the imitation learning setting, leading to the MaIL framework.
Overall, this research aims to make imitation learning more effective, with the potential to improve the performance of AI systems in a wide variety of real-world applications where learning from expert demonstrations is valuable.
Technical Explanation
The paper introduces a new imitation learning method called MaIL that utilizes a technique called "Mamba". Imitation learning is a machine learning approach where an agent learns to perform a task by observing an expert demonstrator.
The key innovation of MaIL is the incorporation of Mamba, a self-attention mechanism that allows the agent to intelligently focus on and learn from the most relevant parts of the expert demonstrations. This contrasts with standard imitation learning approaches, which tend to simply mimic the expert's actions without deeper understanding.
The authors evaluate MaIL on a range of benchmark imitation learning tasks and show that it can outperform existing methods. They attribute this improved performance to MaIL's ability to selectively attend to the most salient aspects of the expert demonstrations.
Furthermore, the authors demonstrate that the Mamba mechanism used in MaIL has connections to state-space models, which have been shown to be effective in other domains like robotics. This suggests that the Mamba approach may have broader applicability beyond just imitation learning.
Critical Analysis
The paper provides a compelling case for the effectiveness of the MaIL approach, with strong empirical results on benchmark tasks. However, the authors acknowledge several limitations and areas for future work.
One potential concern is the computational complexity of the Mamba mechanism, which could limit its scalability to very large or high-dimensional problems. The authors mention plans to investigate more efficient implementations in future work.
Additionally, the paper focuses on relatively simple, tabular environments. It would be valuable to see how MaIL performs on more complex, real-world tasks involving high-dimensional state spaces and continuous control.
The authors also note that MaIL, like other imitation learning methods, relies on the availability of expert demonstrations. In many practical settings, obtaining such demonstrations may be challenging or costly. Exploring ways to combine MaIL with other learning paradigms, such as reinforcement learning, could help address this limitation.
Overall, the MaIL approach represents an interesting and promising advance in imitation learning. However, as with any new technique, further research and validation will be needed to fully understand its strengths, weaknesses, and potential applications.
Conclusion
This paper introduces MaIL, a new imitation learning method that incorporates a technique called "Mamba" to improve the agent's ability to learn from expert demonstrations. The authors show that MaIL can outperform existing imitation learning approaches on a variety of benchmark tasks.
The key innovation of MaIL is its use of Mamba, a self-attention mechanism that allows the agent to selectively focus on the most relevant aspects of the expert's behavior. This contrasts with standard imitation learning, which tends to simply mimic the expert's actions without deeper understanding.
The authors also demonstrate connections between the Mamba mechanism and state-space models, suggesting that this approach may have broader applicability beyond just imitation learning. However, the paper also acknowledges limitations, such as computational complexity, that warrant further investigation.
Overall, this research represents an exciting advance in the field of imitation learning, with the potential to enhance the performance of AI systems in a wide range of real-world applications where learning from expert demonstrations is valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks
Jongho Park, Jaeseung Park, Zheyang Xiong, Nayoung Lee, Jaewoong Cho, Samet Oymak, Kangwook Lee, Dimitris Papailiopoulos
0
0
State-space models (SSMs), such as Mamba (Gu & Dao, 2023), have been proposed as alternatives to Transformer networks in language modeling, by incorporating gating, convolutions, and input-dependent token selection to mitigate the quadratic cost of multi-head attention. Although SSMs exhibit competitive performance, their in-context learning (ICL) capabilities, a remarkable emergent property of modern language models that enables task execution without parameter optimization, remain underexplored compared to Transformers. In this study, we evaluate the ICL performance of SSMs, focusing on Mamba, against Transformer models across various tasks. Our results show that SSMs perform comparably to Transformers in standard regression ICL tasks, while outperforming them in tasks like sparse parity learning. However, SSMs fall short in tasks involving non-standard retrieval functionality. To address these limitations, we introduce a hybrid model, MambaFormer, that combines Mamba with attention blocks, surpassing individual models in tasks where they struggle independently. Our findings suggest that hybrid architectures offer promising avenues for enhancing ICL in language models.
4/26/2024
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
0
0
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
6/13/2024

Demystify Mamba in Vision: A Linear Attention Perspective
Dongchen Han, Ziyi Wang, Zhuofan Xia, Yizeng Han, Yifan Pu, Chunjiang Ge, Jun Song, Shiji Song, Bo Zheng, Gao Huang
0
0
Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba's success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba's success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-Like Linear Attention (MLLA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
5/28/2024

RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Jiaming Liu, Mengzhen Liu, Zhenyu Wang, Lily Lee, Kaichen Zhou, Pengju An, Senqiao Yang, Renrui Zhang, Yandong Guo, Shanghang Zhang
0
0
A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing robot Multimodal Large Language Models (MLLMs) can handle a range of basic tasks, they still face challenges in two areas: 1) inadequate reasoning ability to tackle complex tasks, and 2) high computational costs for MLLM fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic MLLM that leverages the Mamba model to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual data with language embedding through co-training, empowering our model with visual common sense and robot-related reasoning. To further equip RoboMamba with action pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1% of the model) and time (20 minutes). In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 7 times faster than existing robot MLLMs. Our project web page: https://sites.google.com/view/robomamba-web
6/7/2024