Make a Cheap Scaling: A Self-Cascade Diffusion Model for Higher-Resolution Adaptation

0
Sign in to get full access
Overview
- The paper presents a self-cascade diffusion model called "Make a Cheap Scaling" that can generate high-resolution images from low-resolution inputs.
- The model uses a novel architecture and training approach to efficiently scale up diffusion models without incurring high computational costs.
- The researchers claim their method can produce high-quality, high-resolution images while being more computationally efficient than previous approaches.
Plain English Explanation
The paper describes a new technique called "Make a Cheap Scaling" that allows diffusion models to generate high-resolution images from low-resolution inputs. Diffusion models are a type of machine learning model that can create realistic-looking images, but they often struggle to produce high-resolution outputs.
The key idea behind "Make a Cheap Scaling" is to use a multi-stage approach where the model first generates a low-resolution image and then progressively refines it to create a higher-resolution version. This is more efficient than trying to generate a high-resolution image from scratch, as it allows the model to focus on the key details rather than having to generate everything from the ground up.
The researchers claim their method can produce high-quality, high-resolution images while being more computationally efficient than previous approaches that tried to scale up diffusion models. This could make it easier and cheaper to deploy diffusion models in real-world applications that require high-resolution outputs, such as digital art creation or photo editing.
Technical Explanation
The paper introduces a self-cascade diffusion model architecture called "Make a Cheap Scaling" that can efficiently generate high-resolution images from low-resolution inputs. The key elements of their approach are:
-
Multi-Stage Architecture: The model consists of multiple stages, where each stage takes the output of the previous stage and refines it to produce a higher-resolution image. This allows the model to focus on adding details progressively rather than having to generate the entire high-resolution image at once.
-
Learned Upsampling: The researchers use a learned upsampling module that is trained end-to-end with the diffusion model. This module learns how to effectively scale up the low-resolution images produced by the earlier stages of the model.
-
Adaptive Computation: The number of refinement steps performed by each stage of the model is dynamically adjusted based on the complexity of the input image. This helps to minimize the computational cost while still producing high-quality outputs.
Through extensive experiments, the researchers demonstrate that their "Make a Cheap Scaling" approach can generate high-resolution images that are comparable in quality to state-of-the-art diffusion models, but at a fraction of the computational cost.
Critical Analysis
The paper presents a novel and promising approach to scaling up diffusion models for higher-resolution image generation. The key strengths of the "Make a Cheap Scaling" method are its efficient multi-stage architecture, learned upsampling module, and adaptive computation strategy.
However, the paper does not address some potential limitations of the approach:
- Generalization: The researchers primarily evaluate their method on a few common image datasets. It's unclear how well the model would generalize to more diverse or complex image domains.
- Qualitative Evaluation: While the researchers provide quantitative metrics, a more thorough qualitative analysis of the generated images could help better understand the strengths and weaknesses of their approach.
- Computational Requirements: The paper focuses on the relative computational efficiency of "Make a Cheap Scaling" compared to other methods, but it does not provide detailed information about the actual hardware requirements or inference time.
Addressing these issues in future work could further strengthen the "Make a Cheap Scaling" approach and its practical applicability.
Conclusion
The "Make a Cheap Scaling" paper presents an innovative self-cascade diffusion model that can efficiently generate high-resolution images from low-resolution inputs. By using a multi-stage architecture, learned upsampling, and adaptive computation, the researchers demonstrate a way to scale up diffusion models without incurring prohibitive computational costs.
This research has the potential to make high-resolution image generation more accessible and practical for a wide range of applications, from digital art creation to photo editing. As the field of diffusion models continues to evolve, the "Make a Cheap Scaling" approach could serve as an important step towards developing more efficient and powerful image synthesis techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Make a Cheap Scaling: A Self-Cascade Diffusion Model for Higher-Resolution Adaptation
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xiaodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xintao Wang, Qifeng Chen, Ying Shan, Bihan Wen
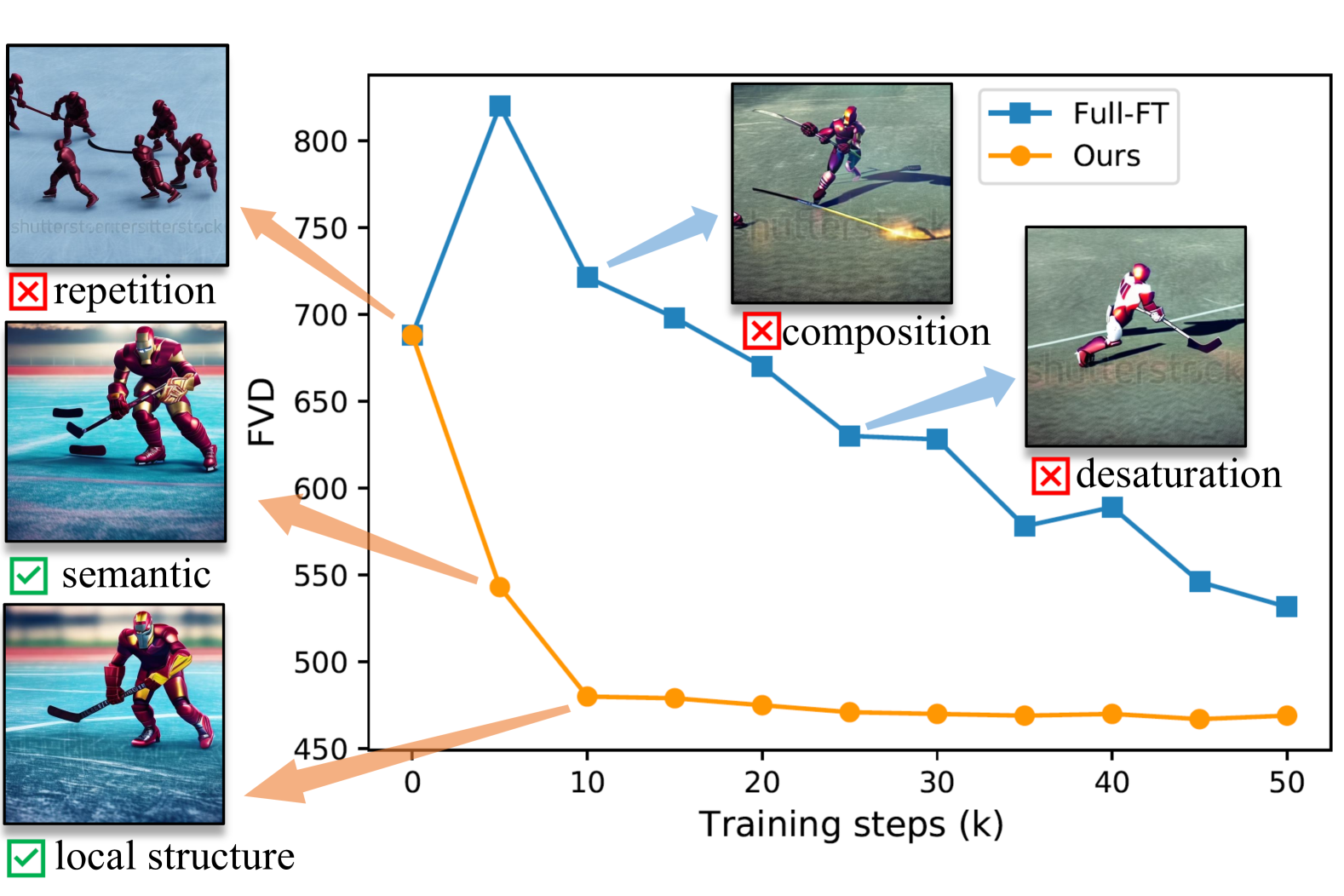
Diffusion models have proven to be highly effective in image and video generation; however, they encounter challenges in the correct composition of objects when generating images of varying sizes due to single-scale training data. Adapting large pre-trained diffusion models to higher resolution demands substantial computational and optimization resources, yet achieving generation capabilities comparable to low-resolution models remains challenging. This paper proposes a novel self-cascade diffusion model that leverages the knowledge gained from a well-trained low-resolution image/video generation model, enabling rapid adaptation to higher-resolution generation. Building on this, we employ the pivot replacement strategy to facilitate a tuning-free version by progressively leveraging reliable semantic guidance derived from the low-resolution model. We further propose to integrate a sequence of learnable multi-scale upsampler modules for a tuning version capable of efficiently learning structural details at a new scale from a small amount of newly acquired high-resolution training data. Compared to full fine-tuning, our approach achieves a $5times$ training speed-up and requires only 0.002M tuning parameters. Extensive experiments demonstrate that our approach can quickly adapt to higher-resolution image and video synthesis by fine-tuning for just $10k$ steps, with virtually no additional inference time.
Read more9/23/2024
🏋️
0
Upsample Guidance: Scale Up Diffusion Models without Training
Juno Hwang, Yong-Hyun Park, Junghyo Jo
Diffusion models have demonstrated superior performance across various generative tasks including images, videos, and audio. However, they encounter difficulties in directly generating high-resolution samples. Previously proposed solutions to this issue involve modifying the architecture, further training, or partitioning the sampling process into multiple stages. These methods have the limitation of not being able to directly utilize pre-trained models as-is, requiring additional work. In this paper, we introduce upsample guidance, a technique that adapts pretrained diffusion model (e.g., $512^2$) to generate higher-resolution images (e.g., $1536^2$) by adding only a single term in the sampling process. Remarkably, this technique does not necessitate any additional training or relying on external models. We demonstrate that upsample guidance can be applied to various models, such as pixel-space, latent space, and video diffusion models. We also observed that the proper selection of guidance scale can improve image quality, fidelity, and prompt alignment.
Read more4/3/2024

0
DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Junyu Zhang, Eunbyung Park
Large-scale generative models, such as text-to-image diffusion models, have garnered widespread attention across diverse domains due to their creative and high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generating images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher-resolution datasets. However, this poses a formidable challenge due to the difficulty in collecting large-scale high-resolution images and substantial computational resources. While several preceding works have proposed alternatives to bypass the cumbersome training process, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond their original capability and propose a novel progressive approach that fully utilizes generated low-resolution images to guide the generation of higher-resolution images. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method. Project page: https://yhyun225.github.io/DiffuseHigh/
Read more8/28/2024

0
Hierarchical Patch Diffusion Models for High-Resolution Video Generation
Ivan Skorokhodov, Willi Menapace, Aliaksandr Siarohin, Sergey Tulyakov
Diffusion models have demonstrated remarkable performance in image and video synthesis. However, scaling them to high-resolution inputs is challenging and requires restructuring the diffusion pipeline into multiple independent components, limiting scalability and complicating downstream applications. This makes it very efficient during training and unlocks end-to-end optimization on high-resolution videos. We improve PDMs in two principled ways. First, to enforce consistency between patches, we develop deep context fusion -- an architectural technique that propagates the context information from low-scale to high-scale patches in a hierarchical manner. Second, to accelerate training and inference, we propose adaptive computation, which allocates more network capacity and computation towards coarse image details. The resulting model sets a new state-of-the-art FVD score of 66.32 and Inception Score of 87.68 in class-conditional video generation on UCF-101 $256^2$, surpassing recent methods by more than 100%. Then, we show that it can be rapidly fine-tuned from a base $36times 64$ low-resolution generator for high-resolution $64 times 288 times 512$ text-to-video synthesis. To the best of our knowledge, our model is the first diffusion-based architecture which is trained on such high resolutions entirely end-to-end. Project webpage: https://snap-research.github.io/hpdm.
Read more6/13/2024