Making Alice Appear Like Bob: A Probabilistic Preference Obfuscation Method For Implicit Feedback Recommendation Models

0

Sign in to get full access
Overview
- This paper proposes a novel probabilistic preference obfuscation method to protect user privacy in implicit feedback recommendation models.
- The method aims to make a user's preferences appear similar to those of another user, while still preserving the overall performance of the recommendation system.
- The authors evaluate their approach on several real-world datasets and show that it can effectively obfuscate user preferences while maintaining recommendation quality.
Plain English Explanation
Recommendation systems are widely used to suggest products, content, or services that users might like. These systems often rely on "implicit feedback" - such as the items a user has viewed or interacted with - to infer their preferences. However, this data can reveal sensitive information about the user's interests and behaviors.
The authors of this paper have developed a new technique to protect user privacy in these recommendation systems. Their method works by "obfuscating" or disguising a user's true preferences, making them appear similar to another user's preferences. This way, the recommendation system cannot easily identify the individual user's actual interests.
The key idea is to introduce a probabilistic transformation that shifts the user's preferences towards those of a "target" user, while still preserving the overall quality of the recommendations. This is achieved by carefully modeling the uncertainty and randomness in the user's feedback data.
The researchers tested their approach on several real-world datasets and found that it can effectively obfuscate user preferences without significantly degrading the recommendation performance. This suggests that their method could be a useful tool for enhancing privacy in recommendation systems, while still providing valuable personalized suggestions to users.
Technical Explanation
The paper introduces a "Probabilistic Preference Obfuscation" (PPO) method to protect user privacy in implicit feedback recommendation models. The core idea is to transform a user's observed preferences to make them appear similar to those of a "target" user, while preserving the overall recommendation performance.
The authors model the user's observed feedback (e.g., item ratings or interactions) as a noisy realization of their true underlying preferences. They then propose a probabilistic transformation that shifts the user's preferences towards the target user's preferences, by carefully accounting for the uncertainty and randomness in the feedback data.
Specifically, the PPO method works as follows:
- For each user, a "target" user is selected, whose preferences will be used to obfuscate the original user's data.
- A probabilistic model is used to estimate the original user's true preferences from their observed feedback.
- A transformation is applied to shift the user's preferences towards those of the target user, while preserving the overall recommendation quality.
The authors evaluate their approach on several real-world datasets, including MovieLens, Amazon, and Criteo. They compare the PPO method to various baselines, including fair recommendation and preference obfuscation approaches. The results show that PPO can effectively obfuscate user preferences while maintaining recommendation performance.
Critical Analysis
The paper presents a promising approach for enhancing privacy in recommendation systems, but there are a few potential limitations and areas for further research:
-
The authors assume that the target user's preferences are known or can be accurately estimated. In practice, this may not always be the case, and the performance of the PPO method could depend on the quality of the target user selection.
-
The paper focuses on obfuscating individual user preferences, but does not address the potential for group-level privacy leaks. It would be valuable to investigate how the PPO method could be extended to protect against such attacks.
-
The evaluation is conducted on relatively simple recommendation tasks and datasets. It would be interesting to see how the PPO method performs on more complex, real-world recommendation scenarios, such as those involving temporal dynamics, contextual information, or large-scale systems.
-
The paper does not provide a thorough analysis of the computational complexity and scalability of the PPO method. As recommendation systems often need to operate at scale, the efficiency of the approach would be an important practical consideration.
Despite these potential limitations, the paper presents a novel and well-designed approach to the important problem of privacy-preserving recommendations. The authors' probabilistic preference obfuscation technique represents a valuable contribution to the field, and future research could build upon this work to further enhance the privacy and utility of recommendation systems.
Conclusion
This paper introduces a new probabilistic preference obfuscation (PPO) method to protect user privacy in implicit feedback recommendation models. The key idea is to transform a user's observed preferences to make them appear similar to those of a "target" user, while preserving the overall recommendation performance.
The authors demonstrate the effectiveness of their approach on several real-world datasets, showing that PPO can effectively obfuscate user preferences without significantly degrading recommendation quality. This suggests that their technique could be a useful tool for enhancing privacy in recommendation systems, while still providing valuable personalized suggestions to users.
While the paper presents a promising approach, there are a few potential limitations and areas for further research, such as the quality of target user selection, group-level privacy protection, and the scalability of the method. Future work could explore these issues and continue to advance the state-of-the-art in privacy-preserving recommendations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Making Alice Appear Like Bob: A Probabilistic Preference Obfuscation Method For Implicit Feedback Recommendation Models
Gustavo Escobedo, Marta Moscati, Peter Muellner, Simone Kopeinik, Dominik Kowald, Elisabeth Lex, Markus Schedl
Users' interaction or preference data used in recommender systems carry the risk of unintentionally revealing users' private attributes (e.g., gender or race). This risk becomes particularly concerning when the training data contains user preferences that can be used to infer these attributes, especially if they align with common stereotypes. This major privacy issue allows malicious attackers or other third parties to infer users' protected attributes. Previous efforts to address this issue have added or removed parts of users' preferences prior to or during model training to improve privacy, which often leads to decreases in recommendation accuracy. In this work, we introduce SBO, a novel probabilistic obfuscation method for user preference data designed to improve the accuracy--privacy trade-off for such recommendation scenarios. We apply SBO to three state-of-the-art recommendation models (i.e., BPR, MultVAE, and LightGCN) and two popular datasets (i.e., MovieLens-1M and LFM-2B). Our experiments reveal that SBO outperforms comparable approaches with respect to the accuracy--privacy trade-off. Specifically, we can reduce the leakage of users' protected attributes while maintaining on-par recommendation accuracy.
Read more6/18/2024
🛠️
0
Heteroscedastic Preferential Bayesian Optimization with Informative Noise Distributions
Marshal Arijona Sinaga, Julien Martinelli, Vikas Garg, Samuel Kaski
Preferential Bayesian optimization (PBO) is a sample-efficient framework for learning human preferences between candidate designs. PBO classically relies on homoscedastic noise models to represent human aleatoric uncertainty. Yet, such noise fails to accurately capture the varying levels of human aleatoric uncertainty, particularly when the user possesses partial knowledge among different pairs of candidates. For instance, a chemist with solid expertise in glucose-related molecules may easily compare two compounds from that family while struggling to compare alcohol-related molecules. Currently, PBO overlooks this uncertainty during the search for a new candidate through the maximization of the acquisition function, consequently underestimating the risk associated with human uncertainty. To address this issue, we propose a heteroscedastic noise model to capture human aleatoric uncertainty. This model adaptively assigns noise levels based on the distance of a specific input to a predefined set of reliable inputs known as anchors provided by the human. Anchors encapsulate partial knowledge and offer insight into the comparative difficulty of evaluating different candidate pairs. Such a model can be seamlessly integrated into the acquisition function, thus leading to candidate design pairs that elegantly trade informativeness and ease of comparison for the human expert. We perform an extensive empirical evaluation of the proposed approach, demonstrating a consistent improvement over homoscedastic PBO.
Read more5/24/2024
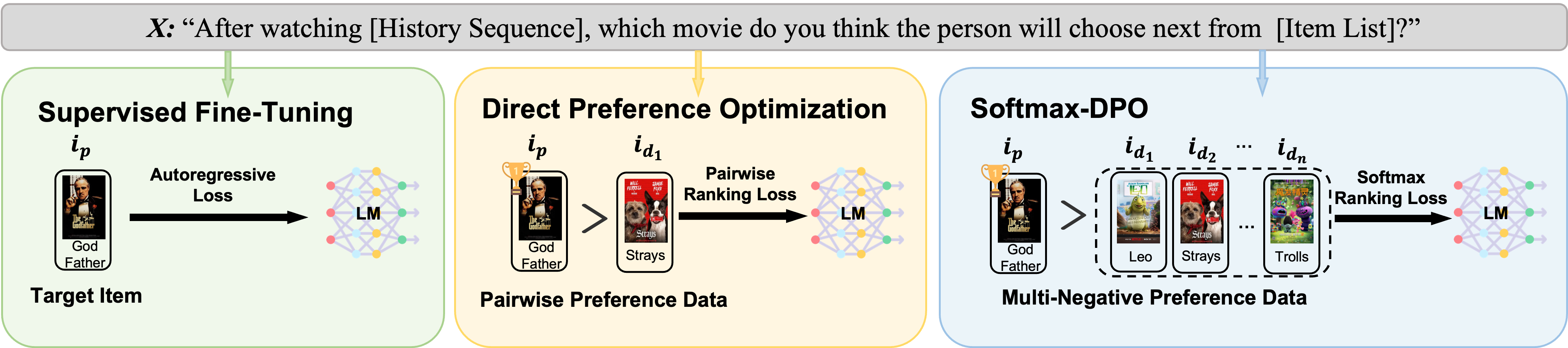
0
On Softmax Direct Preference Optimization for Recommendation
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, Tat-Seng Chua
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
Read more6/17/2024
🛠️
0
Principled Preferential Bayesian Optimization
Wenjie Xu, Wenbin Wang, Yuning Jiang, Bratislav Svetozarevic, Colin N. Jones
We study the problem of preferential Bayesian optimization (BO), where we aim to optimize a black-box function with only preference feedback over a pair of candidate solutions. Inspired by the likelihood ratio idea, we construct a confidence set of the black-box function using only the preference feedback. An optimistic algorithm with an efficient computational method is then developed to solve the problem, which enjoys an information-theoretic bound on the total cumulative regret, a first-of-its-kind for preferential BO. This bound further allows us to design a scheme to report an estimated best solution, with a guaranteed convergence rate. Experimental results on sampled instances from Gaussian processes, standard test functions, and a thermal comfort optimization problem all show that our method stably achieves better or competitive performance as compared to the existing state-of-the-art heuristics, which, however, do not have theoretical guarantees on regret bounds or convergence.
Read more5/30/2024