On Softmax Direct Preference Optimization for Recommendation
2406.09215
0
0
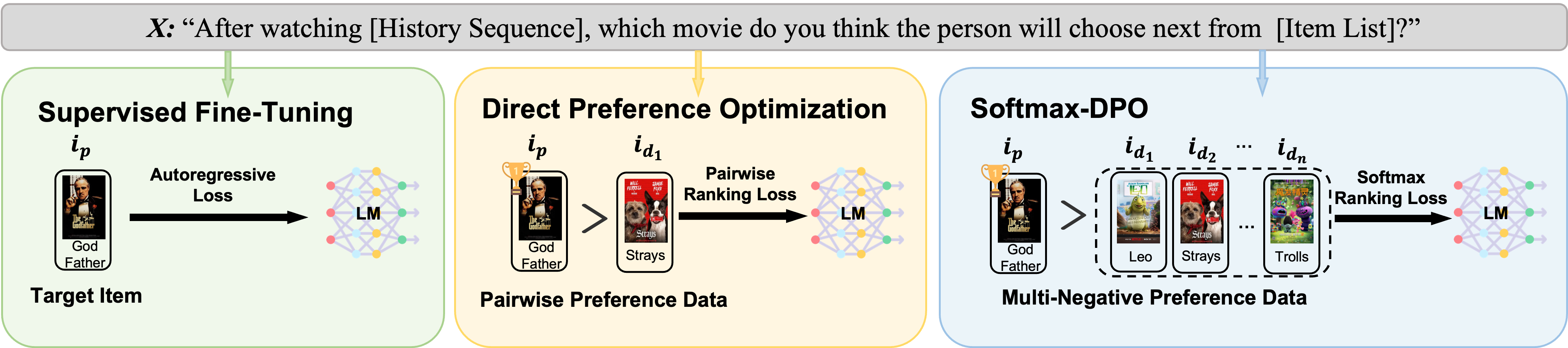
Abstract
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
Create account to get full access
Overview
- This paper proposes a new method for optimizing recommendation systems called "Softmax Direct Preference Optimization" (SDPO).
- SDPO aims to directly optimize for user preferences, rather than traditional approaches that focus on predicting user ratings or rankings.
- The method uses a softmax function to model user preferences and is designed to be more efficient and scalable than previous direct preference optimization techniques.
Plain English Explanation
Recommendation systems are tools that suggest products, content, or information that users might like. Traditional recommendation systems often try to predict how a user will rate or rank different items. On Softmax Direct Preference Optimization for Recommendation introduces a new approach that focuses directly on optimizing for user preferences instead.
The key idea is to use a mathematical function called "softmax" to model how a user prefers one item over another. This is more efficient and scalable than some previous direct preference optimization methods. The authors show that this Softmax Direct Preference Optimization (SDPO) approach can outperform traditional recommendation techniques on several benchmark datasets.
The main benefit of SDPO is that it allows recommendation systems to directly optimize for what users actually prefer, rather than just trying to predict their ratings or rankings. This can lead to recommendations that better match user tastes and preferences. The authors also suggest SDPO could be used to fine-tune large language models to align them with user preferences.
Technical Explanation
The paper proposes a new method called Softmax Direct Preference Optimization (SDPO) for optimizing recommendation systems. Rather than predicting user ratings or rankings, SDPO directly models user preferences using a softmax function.
Specifically, the authors define a preference function P(i,j) that represents the probability a user prefers item i over item j. This preference function is modeled using a softmax over some learned score function s(i) for each item i. The key advantage is that this softmax formulation allows for efficient optimization of the preference function end-to-end.
The authors show that this SDPO approach outperforms traditional recommendation methods like Filtered Direct Preference Optimization and Mallows DPO on several benchmark datasets. They also present an efficient algorithm for training the SDPO model that scales linearly with the number of items.
Additionally, the authors discuss how SDPO could be used to fine-tune large language models to better align them with user preferences, as well as how it relates to other direct preference optimization techniques.
Critical Analysis
The paper presents a compelling new approach to optimizing recommendation systems by directly modeling user preferences. The softmax formulation is a clever way to make direct preference optimization more efficient and scalable. The authors demonstrate strong empirical results compared to previous methods.
However, the paper does not fully address some potential limitations and areas for further research. For example, it's unclear how well SDPO would perform on highly sparse or noisy user preference data, or how it would handle complex, contextual preferences. The authors also do not explore using SDPO to soft preference optimization for aligning language models with user preferences.
Additionally, the paper could have provided more insight into the theoretical properties and guarantees of the SDPO approach. A deeper analysis of the optimization dynamics and convergence behavior may help users better understand the strengths and weaknesses of the method.
Overall, the Softmax Direct Preference Optimization technique represents an important advance in recommendation system design. However, further research is needed to fully understand its capabilities and limitations in practical applications.
Conclusion
This paper introduces a new method called Softmax Direct Preference Optimization (SDPO) that aims to directly optimize recommendation systems for user preferences rather than just predicting ratings or rankings. The key innovation is the use of a softmax function to model preference probabilities, which allows for efficient end-to-end optimization.
The authors demonstrate that SDPO outperforms previous direct preference optimization techniques on several benchmark datasets. They also discuss how SDPO could be used to fine-tune large language models to better align them with user preferences. While the paper has some limitations, it represents an important step forward in designing more effective and user-centric recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
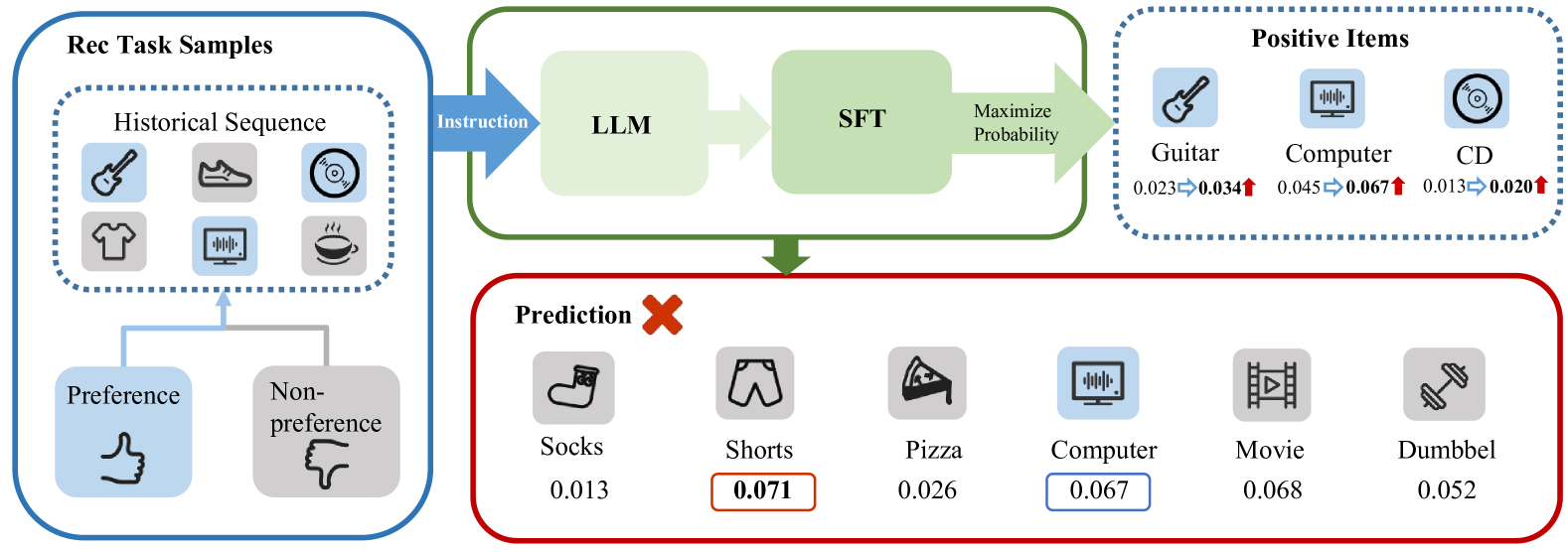
Finetuning Large Language Model for Personalized Ranking
Zhuoxi Bai, Ning Wu, Fengyu Cai, Xinyi Zhu, Yun Xiong
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across various domains, motivating researchers to investigate their potential use in recommendation systems. However, directly applying LLMs to recommendation tasks has proven challenging due to the significant disparity between the data used for pre-training LLMs and the specific requirements of recommendation tasks. In this study, we introduce Direct Multi-Preference Optimization (DMPO), a streamlined framework designed to bridge the gap and enhance the alignment of LLMs for recommendation tasks. DMPO enhances the performance of LLM-based recommenders by simultaneously maximizing the probability of positive samples and minimizing the probability of multiple negative samples. We conducted experimental evaluations to compare DMPO against traditional recommendation methods and other LLM-based recommendation approaches. The results demonstrate that DMPO significantly improves the recommendation capabilities of LLMs across three real-world public datasets in few-shot scenarios. Additionally, the experiments indicate that DMPO exhibits superior generalization ability in cross-domain recommendations. A case study elucidates the reasons behind these consistent improvements and also underscores DMPO's potential as an explainable recommendation system.
6/21/2024
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
0
0
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
4/24/2024
Mallows-DPO: Fine-Tune Your LLM with Preference Dispersions
Haoxian Chen, Hanyang Zhao, Henry Lam, David Yao, Wenpin Tang
0
0
Direct Preference Optimization (DPO) has recently emerged as a popular approach to improve reinforcement learning with human feedback (RLHF), leading to better techniques to fine-tune large language models (LLM). A weakness of DPO, however, lies in its lack of capability to characterize the diversity of human preferences. Inspired by Mallows' theory of preference ranking, we develop in this paper a new approach, the Mallows-DPO. A distinct feature of this approach is a dispersion index, which reflects the dispersion of human preference to prompts. We show that existing DPO models can be reduced to special cases of this dispersion index, thus unified with Mallows-DPO. More importantly, we demonstrate (empirically) how to use this dispersion index to enhance the performance of DPO in a broad array of benchmark tasks, from synthetic bandit selection to controllable generations and dialogues, while maintaining great generalization capabilities.
5/27/2024

Direct Preference Optimization with an Offset
Afra Amini, Tim Vieira, Ryan Cotterell
0
0
Direct preference optimization (DPO) is a successful fine-tuning strategy for aligning large language models with human preferences without the need to train a reward model or employ reinforcement learning. DPO, as originally formulated, relies on binary preference data and fine-tunes a language model to increase the likelihood of a preferred response over a dispreferred response. However, not all preference pairs are equal. Sometimes, the preferred response is only slightly better than the dispreferred one. In other cases, the preference is much stronger. For instance, if a response contains harmful or toxic content, the annotator will have a strong preference for that response. In this paper, we propose a generalization of DPO, termed DPO with an offset (ODPO), that does not treat every preference pair equally during fine-tuning. Intuitively, ODPO requires the difference between the likelihood of the preferred and dispreferred response to be greater than an offset value. The offset is determined based on the extent to which one response is preferred over another. Our experiments on various tasks suggest that ODPO significantly outperforms DPO in aligning language models, especially when the number of preference pairs is limited.
6/7/2024