Assessing Implicit Retrieval Robustness of Large Language Models

0
💬
Sign in to get full access
Overview
- This paper evaluates the retrieval robustness of large language models, which is crucial for retrieval-augmented generation frameworks.
- The researchers instructed the models to directly output the final answer without explicitly judging the relevance of the retrieved context.
- They found that fine-tuning on a mix of gold and distracting context significantly enhances the model's robustness to retrieval inaccuracies, while maintaining its ability to extract correct answers when retrieval is accurate.
Plain English Explanation
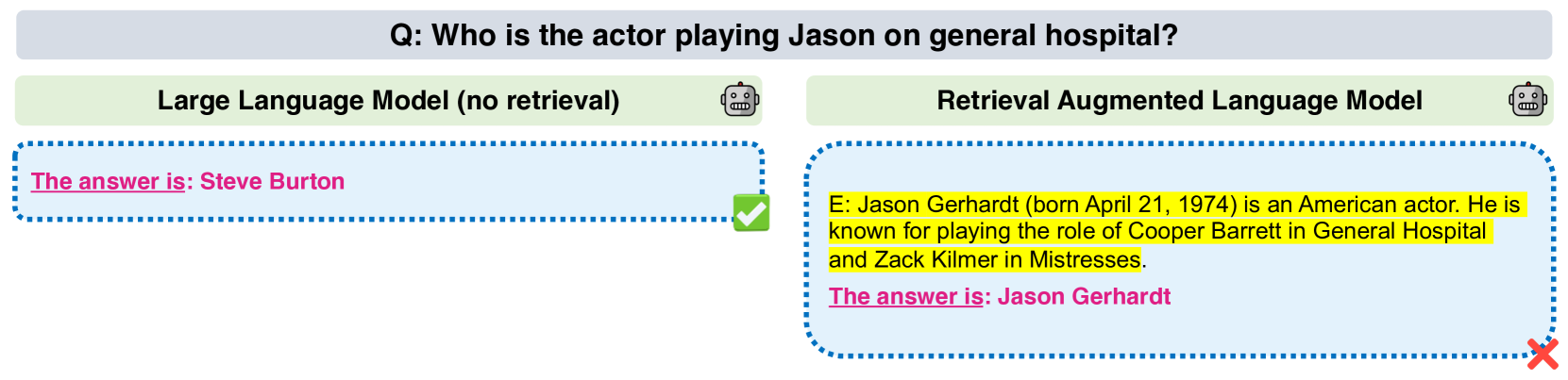
Large language models can be enhanced by retrieval-augmented generation, which allows them to access external knowledge. However, the effectiveness of this approach depends on the retrieval robustness of the model. If the model's retrieval is not robust, its performance will be limited by the accuracy of the retriever, leading to poor results when the retrieved context is irrelevant.
In this study, the researchers evaluated the implicit retrieval robustness of various large language models. Instead of explicitly asking the models to judge the relevance of the retrieved context, the researchers instructed the models to directly output the final answer. This allowed the researchers to assess how well the models could handle both relevant and irrelevant retrieved information.
The key finding is that fine-tuning the models on a mix of accurate (gold) and inaccurate (distracting) context significantly improved the models' robustness to retrieval inaccuracies. At the same time, the models maintained their ability to extract correct answers when the retrieved context was accurate. This suggests that large language models can implicitly handle relevant and irrelevant retrieved context by learning solely from the supervision of the final answer, without the need for an additional process to explicitly judge relevance.
Technical Explanation
The researchers evaluated the retrieval robustness of various large language models in the context of retrieval-augmented generation. Instead of explicitly instructing the models to judge the relevance of the retrieved context, the researchers asked the models to directly output the final answer.
By fine-tuning the models on a mix of gold (accurate) and distracting (inaccurate) context, the researchers found that the models' performance became more robust to retrieval inaccuracies. This means the models could handle both relevant and irrelevant retrieved information, and still produce correct answers when the retrieved context was accurate.
The researchers' approach differs from traditional information retrieval, which often involves a separate process to determine the relevance of the retrieved context. The findings suggest that large language models can implicitly learn to handle relevant and irrelevant retrieved context by focusing solely on the supervision of the final answer, without the need for an additional relevance judgment step.
Critical Analysis
The researchers provide an interesting approach to evaluating the retrieval robustness of large language models. By instructing the models to directly output the final answer, rather than explicitly judging the relevance of the retrieved context, the researchers were able to gain insights into the models' implicit ability to handle both relevant and irrelevant information.
One potential limitation of the study is that it focuses on a specific set of large language models and datasets. The researchers acknowledge that the models' performance may vary depending on the specific task and dataset, and further research is needed to understand the generalizability of their findings.
Additionally, the study does not explore the underlying mechanisms that allow the fine-tuned models to become more robust to retrieval inaccuracies. Further research could investigate the specific learning processes or architectural changes that contribute to this improved robustness.
Another area for future research could be examining the trade-offs between improving retrieval robustness and maintaining the model's ability to leverage accurate retrieved context. The researchers suggest that the end-to-end approach they explored may be preferable to an additional relevance judgment step, but the optimal balance between these two aspects may depend on the specific application and requirements.
Conclusion
This paper presents an insightful evaluation of the retrieval robustness of large language models, a crucial aspect for the effectiveness of retrieval-augmented generation frameworks. The key finding is that fine-tuning the models on a mix of accurate and inaccurate retrieved context can significantly enhance their ability to handle retrieval inaccuracies, while still maintaining their performance when the retrieved context is relevant.
This research suggests that large language models can implicitly learn to manage relevant and irrelevant retrieved information, without the need for an explicit relevance judgment step. This has important implications for the design of retrieval-augmented systems, as it highlights the potential to simplify the architecture and training process while preserving the benefits of external knowledge integration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Assessing Implicit Retrieval Robustness of Large Language Models
Xiaoyu Shen, Rexhina Blloshmi, Dawei Zhu, Jiahuan Pei, Wei Zhang
Retrieval-augmented generation has gained popularity as a framework to enhance large language models with external knowledge. However, its effectiveness hinges on the retrieval robustness of the model. If the model lacks retrieval robustness, its performance is constrained by the accuracy of the retriever, resulting in significant compromises when the retrieved context is irrelevant. In this paper, we evaluate the implicit retrieval robustness of various large language models, instructing them to directly output the final answer without explicitly judging the relevance of the retrieved context. Our findings reveal that fine-tuning on a mix of gold and distracting context significantly enhances the model's robustness to retrieval inaccuracies, while still maintaining its ability to extract correct answers when retrieval is accurate. This suggests that large language models can implicitly handle relevant or irrelevant retrieved context by learning solely from the supervision of the final answer in an end-to-end manner. Introducing an additional process for explicit relevance judgment can be unnecessary and disrupts the end-to-end approach.
Read more6/27/2024
0
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Read more5/7/2024

0
Towards Building a Robust Knowledge Intensive Question Answering Model with Large Language Models
Xingyun Hong, Yan Shao, Zhilin Wang, Manni Duan, Jin Xiongnan
The development of LLMs has greatly enhanced the intelligence and fluency of question answering, while the emergence of retrieval enhancement has enabled models to better utilize external information. However, the presence of noise and errors in retrieved information poses challenges to the robustness of LLMs. In this work, to evaluate the model's performance under multiple interferences, we first construct a dataset based on machine reading comprehension datasets simulating various scenarios, including critical information absence, noise, and conflicts. To address the issue of model accuracy decline caused by noisy external information, we propose a data augmentation-based fine-tuning method to enhance LLM's robustness against noise. Additionally, contrastive learning approach is utilized to preserve the model's discrimination capability of external information. We have conducted experiments on both existing LLMs and our approach, the results are evaluated by GPT-4, which indicates that our proposed methods improve model robustness while strengthening the model's discrimination capability.
Read more9/19/2024

0
Evaluating the Adversarial Robustness of Retrieval-Based In-Context Learning for Large Language Models
Simon Chi Lok Yu, Jie He, Pasquale Minervini, Jeff Z. Pan
With the emergence of large language models, such as LLaMA and OpenAI GPT-3, In-Context Learning (ICL) gained significant attention due to its effectiveness and efficiency. However, ICL is very sensitive to the choice, order, and verbaliser used to encode the demonstrations in the prompt. Retrieval-Augmented ICL methods try to address this problem by leveraging retrievers to extract semantically related examples as demonstrations. While this approach yields more accurate results, its robustness against various types of adversarial attacks, including perturbations on test samples, demonstrations, and retrieved data, remains under-explored. Our study reveals that retrieval-augmented models can enhance robustness against test sample attacks, outperforming vanilla ICL with a 4.87% reduction in Attack Success Rate (ASR); however, they exhibit overconfidence in the demonstrations, leading to a 2% increase in ASR for demonstration attacks. Adversarial training can help improve the robustness of ICL methods to adversarial attacks; however, such a training scheme can be too costly in the context of LLMs. As an alternative, we introduce an effective training-free adversarial defence method, DARD, which enriches the example pool with those attacked samples. We show that DARD yields improvements in performance and robustness, achieving a 15% reduction in ASR over the baselines. Code and data are released to encourage further research: https://github.com/simonucl/adv-retreival-icl
Read more7/11/2024