A Mallows-like Criterion for Anomaly Detection with Random Forest Implementation

0

Sign in to get full access
Overview
- This paper proposes a new Mallows-like criterion for anomaly detection using a random forest implementation.
- The method aims to identify anomalous data points by evaluating how well they fit within the overall data distribution.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets and compare it to existing anomaly detection techniques.
Plain English Explanation
The paper presents a new way to detect anomalies, or unusual data points, in a dataset. The key idea is to use a Mallows-like criterion, which is a statistical measure of how well a data point fits within the overall distribution of the data.
The authors implemented this approach using a random forest machine learning model. Random forests are a type of algorithm that can learn patterns in data by building many small decision trees. The Mallows-like criterion is used to evaluate how well each data point matches the patterns learned by the random forest.
Data points that have a high Mallows-like score are considered anomalies, as they don't fit well with the rest of the data. This approach allows the authors to identify unusual or suspicious data points that may be of interest for further investigation.
The researchers tested their method on several benchmark datasets and found that it performed well compared to other anomaly detection techniques. This suggests the Mallows-like criterion could be a useful tool for identifying anomalies in a variety of real-world applications, such as detecting fraud, monitoring industrial processes, or identifying cybersecurity threats.
Technical Explanation
The paper proposes a new anomaly detection method based on a Mallows-like criterion. The Mallows distance is a statistical measure that quantifies how similar two probability distributions are. The authors adapt this concept to evaluate how well each data point fits within the overall data distribution learned by a random forest model.
Specifically, the random forest is trained on the input data, and then the Mallows-like score is calculated for each data point. This score reflects how likely the data point is to have been generated by the same underlying distribution as the rest of the data. Data points with low Mallows-like scores are considered anomalies, as they do not align well with the patterns captured by the random forest.
The authors evaluate their proposed method on several public anomaly detection benchmark datasets, including Arrhythmia, Shuttle, and Thyroid. They compare the performance of their Mallows-based approach to other popular anomaly detection techniques, such as one-class support vector machines and isolation forests.
The results demonstrate that the Mallows-like criterion can effectively identify anomalous data points, often outperforming the competing methods. The authors attribute this to the ability of the random forest to capture the underlying data distribution, and the Mallows-like score's sensitivity to deviations from that distribution.
Critical Analysis
The paper presents a novel and promising approach to anomaly detection, with a solid theoretical foundation in the Mallows distance concept. The random forest implementation allows the method to scale to high-dimensional datasets, which is a key advantage over some other anomaly detection techniques.
However, the paper does not address certain practical considerations that may arise when applying this method in real-world scenarios. For example, the authors do not discuss how the method would perform in the presence of noisy or missing data, or how it might be affected by class imbalance in the training data.
Additionally, while the benchmark dataset results are encouraging, it would be valuable to see the method evaluated on more diverse and complex datasets that better reflect the types of anomalies encountered in real-world applications. Further research could also explore ways to improve the interpretability of the Mallows-like scores, to help users understand why certain data points are flagged as anomalies.
Overall, the proposed Mallows-like criterion for anomaly detection is a promising contribution to the field, but additional research and real-world testing would be needed to fully assess its limitations and potential for practical applications.
Conclusion
This paper presents a novel anomaly detection method that uses a Mallows-like criterion to evaluate how well each data point fits within the overall data distribution learned by a random forest model. The authors demonstrate the effectiveness of this approach on several benchmark datasets and show that it can outperform other popular anomaly detection techniques.
The Mallows-like criterion offers a principled way to identify anomalous data points, which could be valuable in a wide range of applications, such as fraud detection, process monitoring, and cybersecurity. While the paper highlights the potential of this method, further research is needed to address practical considerations and explore its performance on more diverse and complex real-world datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Mallows-like Criterion for Anomaly Detection with Random Forest Implementation
Gaoxiang Zhao, Lu Wang, Xiaoqiang Wang
The effectiveness of anomaly signal detection can be significantly undermined by the inherent uncertainty of relying on one specified model. Under the framework of model average methods, this paper proposes a novel criterion to select the weights on aggregation of multiple models, wherein the focal loss function accounts for the classification of extremely imbalanced data. This strategy is further integrated into Random Forest algorithm by replacing the conventional voting method. We have evaluated the proposed method on benchmark datasets across various domains, including network intrusion. The findings indicate that our proposed method not only surpasses the model averaging with typical loss functions but also outstrips common anomaly detection algorithms in terms of accuracy and robustness.
Read more5/30/2024

0
Anomaly Detection Within Mission-Critical Call Processing
Sean Doris, Iosif Salem, Stefan Schmid
With increasingly larger and more complex telecommunication networks, there is a need for improved monitoring and reliability. Requirements increase further when working with mission-critical systems requiring stable operations to meet precise design and client requirements while maintaining high availability. This paper proposes a novel methodology for developing a machine learning model that can assist in maintaining availability (through anomaly detection) for client-server communications in mission-critical systems. To that end, we validate our methodology for training models based on data classified according to client performance. The proposed methodology evaluates the use of machine learning to perform anomaly detection of a single virtualized server loaded with simulated network traffic (using SIPp) with media calls. The collected data for the models are classified based on the round trip time performance experienced on the client side to determine if the trained models can detect anomalous client side performance only using key performance indicators available on the server. We compared the performance of seven different machine learning models by testing different trained and untrained test stressor scenarios. In the comparison, five models achieved an F1-score above 0.99 for the trained test scenarios. Random Forest was the only model able to attain an F1-score above 0.9 for all untrained test scenarios with the lowest being 0.980. The results suggest that it is possible to generate accurate anomaly detection to evaluate degraded client-side performance.
Read more8/28/2024

0
New!Fair Anomaly Detection For Imbalanced Groups
Ziwei Wu, Lecheng Zheng, Yuancheng Yu, Ruizhong Qiu, John Birge, Jingrui He
Anomaly detection (AD) has been widely studied for decades in many real-world applications, including fraud detection in finance, and intrusion detection for cybersecurity, etc. Due to the imbalanced nature between protected and unprotected groups and the imbalanced distributions of normal examples and anomalies, the learning objectives of most existing anomaly detection methods tend to solely concentrate on the dominating unprotected group. Thus, it has been recognized by many researchers about the significance of ensuring model fairness in anomaly detection. However, the existing fair anomaly detection methods tend to erroneously label most normal examples from the protected group as anomalies in the imbalanced scenario where the unprotected group is more abundant than the protected group. This phenomenon is caused by the improper design of learning objectives, which statistically focus on learning the frequent patterns (i.e., the unprotected group) while overlooking the under-represented patterns (i.e., the protected group). To address these issues, we propose FairAD, a fairness-aware anomaly detection method targeting the imbalanced scenario. It consists of a fairness-aware contrastive learning module and a rebalancing autoencoder module to ensure fairness and handle the imbalanced data issue, respectively. Moreover, we provide the theoretical analysis that shows our proposed contrastive learning regularization guarantees group fairness. Empirical studies demonstrate the effectiveness and efficiency of FairAD across multiple real-world datasets.
Read more9/18/2024
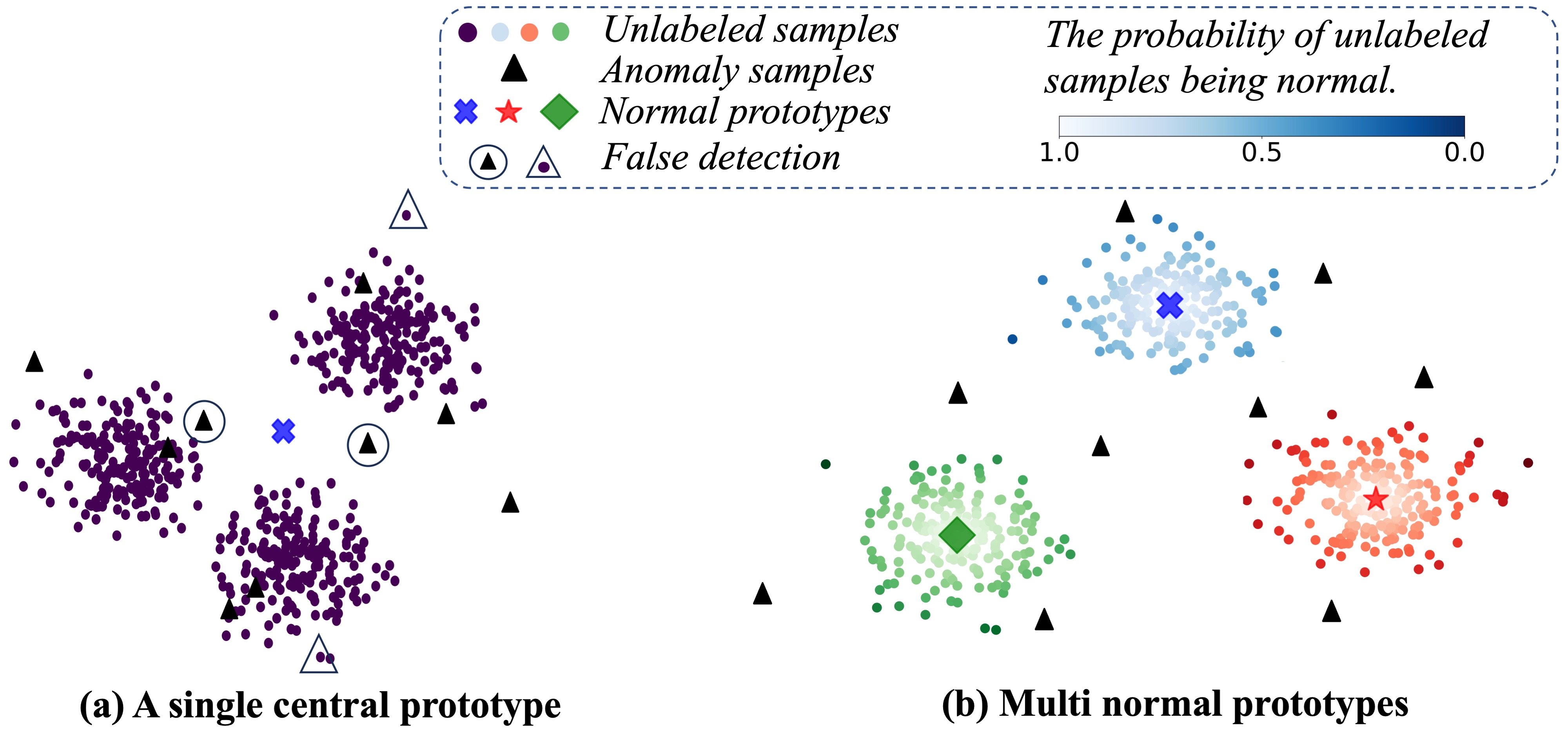
0
Reconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection
Zhijin Dong, Hongzhi Liu, Boyuan Ren, Weimin Xiong, Zhonghai Wu
Anomaly detection is a crucial task in various domains. Most of the existing methods assume the normal sample data clusters around a single central prototype while the real data may consist of multiple categories or subgroups. In addition, existing methods always assume all unlabeled data are normal while they inevitably contain some anomalous samples. To address these issues, we propose a reconstruction-based multi-normal prototypes learning framework that leverages limited labeled anomalies in conjunction with abundant unlabeled data for anomaly detection. Specifically, we assume the normal sample data may satisfy multi-modal distribution, and utilize deep embedding clustering and contrastive learning to learn multiple normal prototypes to represent it. Additionally, we estimate the likelihood of each unlabeled sample being normal based on the multi-normal prototypes, guiding the training process to mitigate the impact of contaminated anomalies in the unlabeled data. Extensive experiments on various datasets demonstrate the superior performance of our method compared to state-of-the-art techniques.
Read more8/28/2024