The Mamba in the Llama: Distilling and Accelerating Hybrid Models

1

Sign in to get full access
Overview
- Introduces a new hybrid model called Mamba that combines the strengths of transformers and more efficient models
- Mamba is distilled from a large language model (like Llama) to be more compact and efficient while retaining key capabilities
- Mamba can accelerate inference speed compared to the original model
Plain English Explanation
The paper presents a new hybrid model called Mamba that aims to combine the powerful capabilities of transformer-based language models like Llama with more efficient model architectures.
The key idea is to distill the knowledge from a large, complex model like Llama into a more compact Mamba model. This allows Mamba to retain the core abilities of the original model while being smaller and faster to run.
The authors show that Mamba can achieve comparable performance to the original model, but with significantly faster inference speed. This makes Mamba an attractive option for applications where efficiency and speed are important, without sacrificing too much capability.
Technical Explanation
The paper introduces the Mamba architecture, which is designed to distill the knowledge from a large, powerful transformer-based language model like Llama into a more compact and efficient model.
Mamba uses a hybrid approach, combining elements of transformers with other efficient model types. This allows Mamba to retain key capabilities of the original model while being smaller and faster to run during inference.
The authors demonstrate that Mamba can achieve comparable performance to the original large language model, but with significantly faster inference speed. This makes Mamba a promising option for applications where efficiency and speed are important, without sacrificing too much capability.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Mamba model, including comparisons to the original large language model and other efficient architectures. The results show clear benefits of the Mamba approach in terms of inference speed and efficiency, without major degradation in overall performance.
However, the paper does not delve deeply into the limitations or potential issues with Mamba. For example, it is unclear how Mamba would scale to even larger language models, or how it would perform on more specialized tasks beyond the general language modeling benchmark used.
Additionally, the paper does not discuss potential fairness or bias concerns that could arise from distilling a large, complex model into a more compact form. Further research would be needed to understand how these issues may be impacted.
Overall, the paper makes a compelling case for the Mamba approach, but there are still open questions and areas for further exploration.
Conclusion
This paper introduces the Mamba model, a novel hybrid architecture that combines the strengths of transformers and more efficient models. By distilling the knowledge from a large language model like Llama, Mamba is able to achieve comparable performance with significantly faster inference speed.
The key innovation of Mamba is its ability to retain important capabilities while being more compact and efficient. This makes Mamba a promising option for applications where speed and resource usage are critical factors, without sacrificing too much overall model capability.
While the paper provides a thorough evaluation, there are still open questions around Mamba's scalability, specialized task performance, and potential fairness/bias concerns. Further research in these areas could help solidify Mamba's place as a valuable addition to the toolkit of efficient and high-performing AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao
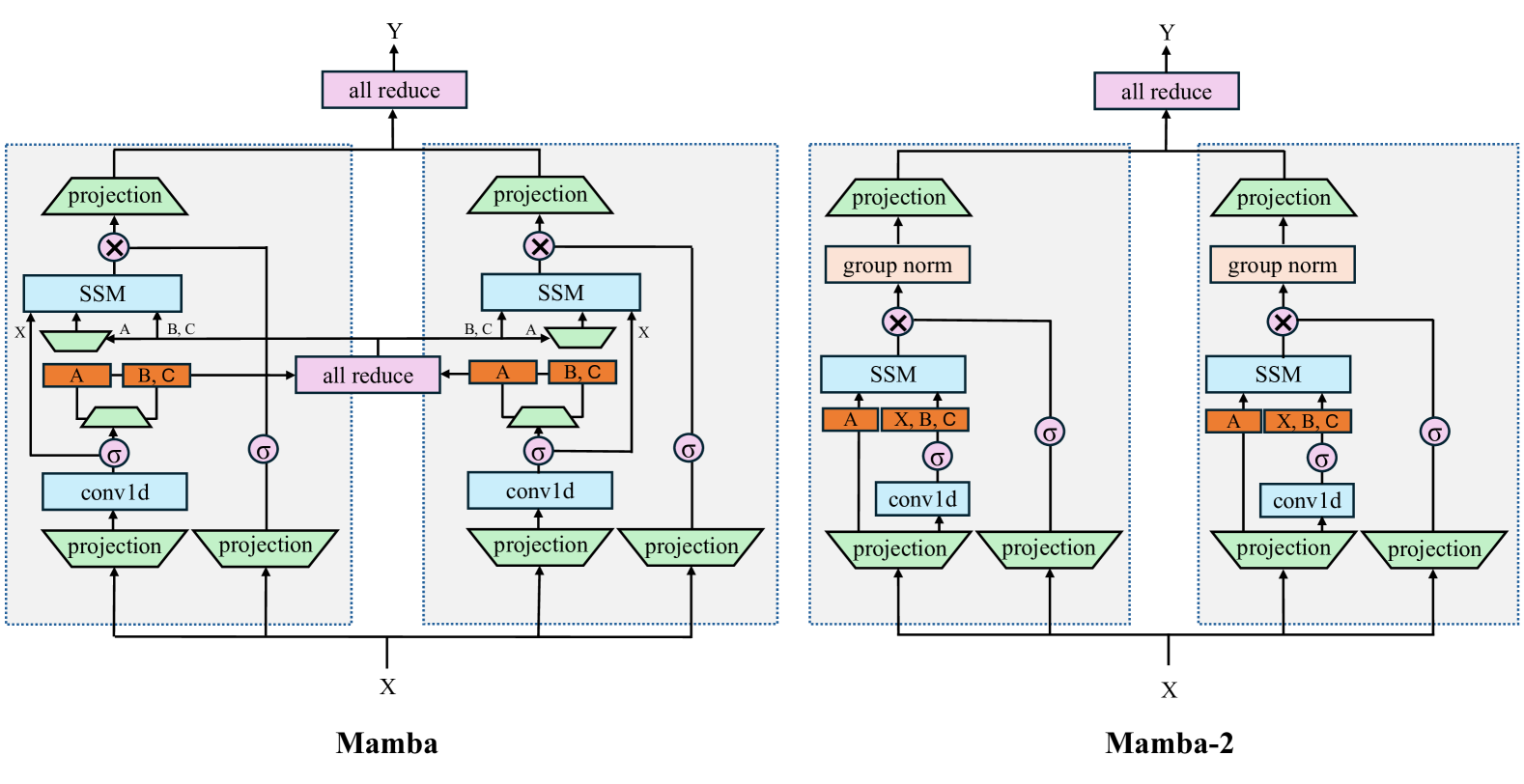
Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics. Given the focus on training large-scale Transformer models, we consider the challenge of converting these pretrained models for deployment. We demonstrate that it is feasible to distill large Transformers into linear RNNs by reusing the linear projection weights from attention layers with academic GPU resources. The resulting hybrid model, which incorporates a quarter of the attention layers, achieves performance comparable to the original Transformer in chat benchmarks and outperforms open-source hybrid Mamba models trained from scratch with trillions of tokens in both chat benchmarks and general benchmarks. Moreover, we introduce a hardware-aware speculative decoding algorithm that accelerates the inference speed of Mamba and hybrid models. Overall we show how, with limited computation resources, we can remove many of the original attention layers and generate from the resulting model more efficiently. Our top-performing model, distilled from Llama3-8B-Instruct, achieves a 29.61 length-controlled win rate on AlpacaEval 2 against GPT-4 and 7.35 on MT-Bench, surpassing the best instruction-tuned linear RNN model.
Read more8/28/2024
30
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
Read more6/13/2024

0
A Survey of Mamba
Haohao Qu, Liangbo Ning, Rui An, Wenqi Fan, Tyler Derr, Hui Liu, Xin Xu, Qing Li
As one of the most representative DL techniques, Transformer architecture has empowered numerous advanced models, especially the large language models (LLMs) that comprise billions of parameters, becoming a cornerstone in deep learning. Despite the impressive achievements, Transformers still face inherent limitations, particularly the time-consuming inference resulting from the quadratic computation complexity of attention calculation. Recently, a novel architecture named Mamba, drawing inspiration from classical state space models (SSMs), has emerged as a promising alternative for building foundation models, delivering comparable modeling abilities to Transformers while preserving near-linear scalability concerning sequence length. This has sparked an increasing number of studies actively exploring Mamba's potential to achieve impressive performance across diverse domains. Given such rapid evolution, there is a critical need for a systematic review that consolidates existing Mamba-empowered models, offering a comprehensive understanding of this emerging model architecture. In this survey, we therefore conduct an in-depth investigation of recent Mamba-associated studies, covering three main aspects: the advancements of Mamba-based models, the techniques of adapting Mamba to diverse data, and the applications where Mamba can excel. Specifically, we first review the foundational knowledge of various representative deep learning models and the details of Mamba-1&2 as preliminaries. Then, to showcase the significance of Mamba for AI, we comprehensively review the related studies focusing on Mamba models' architecture design, data adaptability, and applications. Finally, we present a discussion of current limitations and explore various promising research directions to provide deeper insights for future investigations.
Read more8/23/2024
🤷
91
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Read more6/3/2024