MUSE: Mamba is Efficient Multi-scale Learner for Text-video Retrieval

0

Sign in to get full access
Overview
- The paper presents MUSE, a multi-scale learner for efficient text-video retrieval.
- MUSE, called "Mamba," uses a hierarchical architecture to capture information at multiple scales.
- MUSE is designed to be efficient, outperforming previous state-of-the-art models on several benchmarks.
Plain English Explanation
The researchers have developed a new model called MUSE, or "Mamba," that is designed to be an efficient way to match text descriptions with the corresponding videos. This is an important task in areas like video search and recommendation.
Mamba works by using a hierarchical approach, where it looks at the video and text at multiple different "scales" or levels of detail. This multi-scale approach allows it to capture important information at various granularities, which helps it make better matches between the text and video.
Importantly, Mamba is designed to be efficient, meaning it can make these text-video matches quickly and with low computational cost. This efficiency allows it to outperform previous state-of-the-art models on benchmark tests, making it a promising approach for real-world applications.
Technical Explanation
The core of the MUSE model is a hierarchical architecture that processes the input text and video at multiple scales. This multi-scale design allows MUSE to capture information at different levels of granularity, from high-level semantics to low-level details.
At the top level, MUSE uses transformers to encode the overall meaning of the text and video. These high-level representations are then passed to lower levels that extract more fine-grained features. For example, the lower levels might focus on specific objects, actions, or relationships present in the video.
By aggregating information across these multiple scales, MUSE is able to build a rich, multi-faceted understanding of the text-video pair. This allows it to make accurate retrieval decisions, outperforming prior approaches that relied on single-scale representations.
The researchers demonstrate MUSE's effectiveness on several text-video retrieval benchmarks, showing that it achieves state-of-the-art performance while being significantly more efficient than competing models.
Critical Analysis
The authors note that while MUSE achieves strong results, there is still room for improvement, particularly in scaling to even larger and more diverse datasets. They also acknowledge that the multi-scale approach introduces additional complexity that may be challenging to deploy in certain real-world scenarios.
Additionally, the paper does not delve into potential biases or ethical considerations that may arise from deploying a text-video retrieval system at scale. As these models become more widely used, it will be important for future research to carefully examine such issues.
Overall, the MUSE model represents an interesting and effective approach to the text-video retrieval task. Its multi-scale design and efficiency make it a promising direction for further exploration and refinement.
Conclusion
The MUSE model, or "Mamba," presents a novel hierarchical approach to efficiently matching text descriptions with corresponding videos. By processing the input at multiple scales, MUSE is able to capture rich, multi-faceted representations that outperform previous state-of-the-art methods on several benchmarks.
While the multi-scale design introduces some additional complexity, MUSE's efficiency makes it a compelling option for real-world applications in domains like video search and recommendation. As the field continues to advance, it will be important to further explore the capabilities and limitations of this approach, as well as its potential societal impacts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MUSE: Mamba is Efficient Multi-scale Learner for Text-video Retrieval
Haoran Tang, Meng Cao, Jinfa Huang, Ruyang Liu, Peng Jin, Ge Li, Xiaodan Liang
Text-Video Retrieval (TVR) aims to align and associate relevant video content with corresponding natural language queries. Most existing TVR methods are based on large-scale pre-trained vision-language models (e.g., CLIP). However, due to the inherent plain structure of CLIP, few TVR methods explore the multi-scale representations which offer richer contextual information for a more thorough understanding. To this end, we propose MUSE, a multi-scale mamba with linear computational complexity for efficient cross-resolution modeling. Specifically, the multi-scale representations are generated by applying a feature pyramid on the last single-scale feature map. Then, we employ the Mamba structure as an efficient multi-scale learner to jointly learn scale-wise representations. Furthermore, we conduct comprehensive studies to investigate different model structures and designs. Extensive results on three popular benchmarks have validated the superiority of MUSE.
Read more8/21/2024

0
ML-Mamba: Efficient Multi-Modal Large Language Model Utilizing Mamba-2
Wenjun Huang, Jiakai Pan, Jiahao Tang, Yanyu Ding, Yifei Xing, Yuhe Wang, Zhengzhuo Wang, Jianguo Hu
Multimodal Large Language Models (MLLMs) have attracted much attention for their multifunctionality. However, traditional Transformer architectures incur significant overhead due to their secondary computational complexity. To address this issue, we introduce ML-Mamba, a multimodal language model, which utilizes the latest and efficient Mamba-2 model for inference. Mamba-2 is known for its linear scalability and fast processing of long sequences. We replace the Transformer-based backbone with a pre-trained Mamba-2 model and explore methods for integrating 2D visual selective scanning mechanisms into multimodal learning while also trying various visual encoders and Mamba-2 model variants. Our extensive experiments in various multimodal benchmark tests demonstrate the competitive performance of ML-Mamba and highlight the potential of state space models in multimodal tasks. The experimental results show that: (1) we empirically explore how to effectively apply the 2D vision selective scan mechanism for multimodal learning. We propose a novel multimodal connector called the Mamba-2 Scan Connector (MSC), which enhances representational capabilities. (2) ML-Mamba achieves performance comparable to state-of-the-art methods such as TinyLaVA and MobileVLM v2 through its linear sequential modeling while faster inference speed; (3) Compared to multimodal models utilizing Mamba-1, the Mamba-2-based ML-Mamba exhibits superior inference performance and effectiveness.
Read more8/22/2024
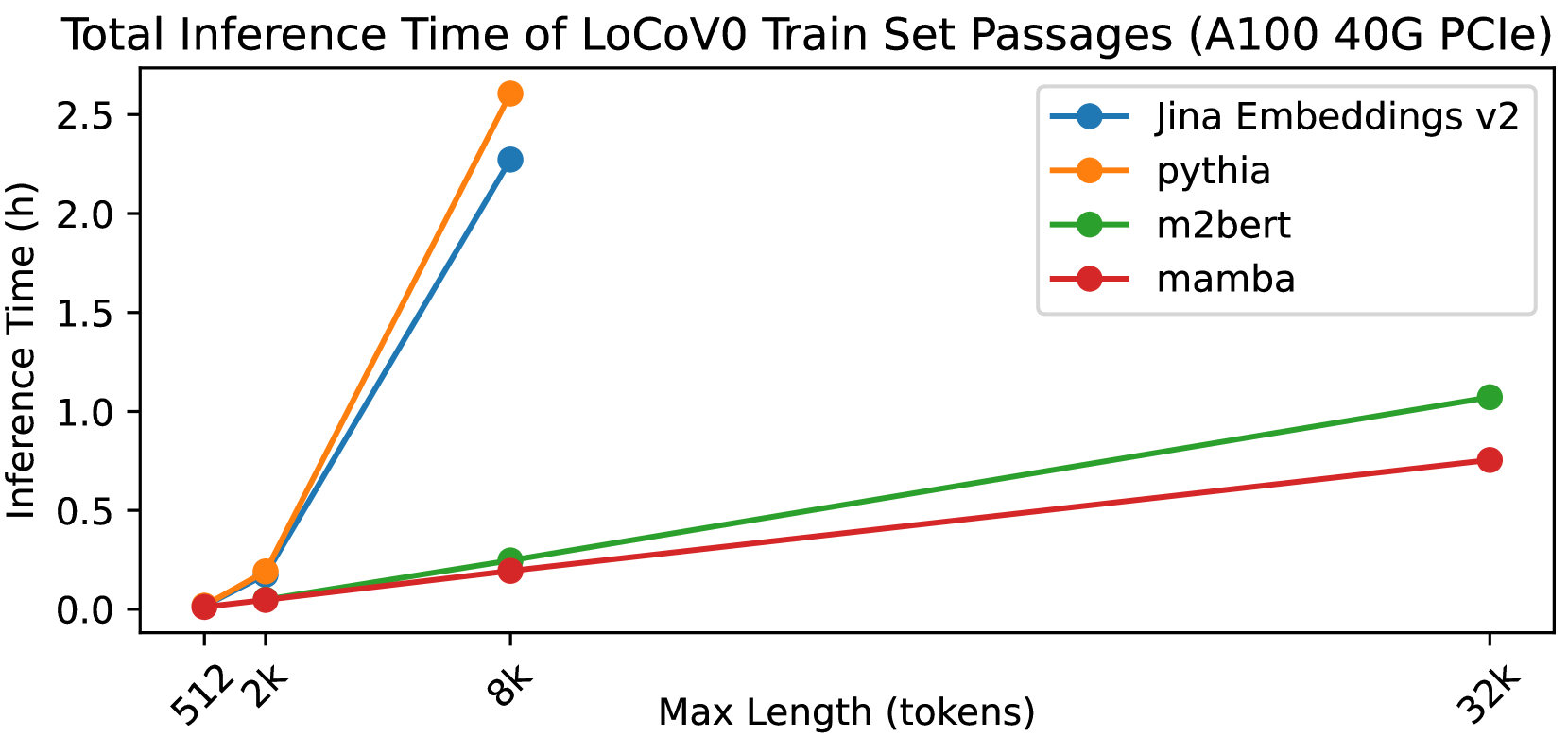
0
Mamba Retriever: Utilizing Mamba for Effective and Efficient Dense Retrieval
Hanqi Zhang, Chong Chen, Lang Mei, Qi Liu, Jiaxin Mao
In the information retrieval (IR) area, dense retrieval (DR) models use deep learning techniques to encode queries and passages into embedding space to compute their semantic relations. It is important for DR models to balance both efficiency and effectiveness. Pre-trained language models (PLMs), especially Transformer-based PLMs, have been proven to be effective encoders of DR models. However, the self-attention component in Transformer-based PLM results in a computational complexity that grows quadratically with sequence length, and thus exhibits a slow inference speed for long-text retrieval. Some recently proposed non-Transformer PLMs, especially the Mamba architecture PLMs, have demonstrated not only comparable effectiveness to Transformer-based PLMs on generative language tasks but also better efficiency due to linear time scaling in sequence length. This paper implements the Mamba Retriever to explore whether Mamba can serve as an effective and efficient encoder of DR model for IR tasks. We fine-tune the Mamba Retriever on the classic short-text MS MARCO passage ranking dataset and the long-text LoCoV0 dataset. Experimental results show that (1) on the MS MARCO passage ranking dataset and BEIR, the Mamba Retriever achieves comparable or better effectiveness compared to Transformer-based retrieval models, and the effectiveness grows with the size of the Mamba model; (2) on the long-text LoCoV0 dataset, the Mamba Retriever can extend to longer text length than its pre-trained length after fine-tuning on retrieval task, and it has comparable or better effectiveness compared to other long-text retrieval models; (3) the Mamba Retriever has superior inference speed for long-text retrieval. In conclusion, Mamba Retriever is both effective and efficient, making it a practical model, especially for long-text retrieval.
Read more8/23/2024

0
MSVM-UNet: Multi-Scale Vision Mamba UNet for Medical Image Segmentation
Chaowei Chen, Li Yu, Shiquan Min, Shunfang Wang
State Space Models (SSMs), especially Mamba, have shown great promise in medical image segmentation due to their ability to model long-range dependencies with linear computational complexity. However, accurate medical image segmentation requires the effective learning of both multi-scale detailed feature representations and global contextual dependencies. Although existing works have attempted to address this issue by integrating CNNs and SSMs to leverage their respective strengths, they have not designed specialized modules to effectively capture multi-scale feature representations, nor have they adequately addressed the directional sensitivity problem when applying Mamba to 2D image data. To overcome these limitations, we propose a Multi-Scale Vision Mamba UNet model for medical image segmentation, termed MSVM-UNet. Specifically, by introducing multi-scale convolutions in the VSS blocks, we can more effectively capture and aggregate multi-scale feature representations from the hierarchical features of the VMamba encoder and better handle 2D visual data. Additionally, the large kernel patch expanding (LKPE) layers achieve more efficient upsampling of feature maps by simultaneously integrating spatial and channel information. Extensive experiments on the Synapse and ACDC datasets demonstrate that our approach is more effective than some state-of-the-art methods in capturing and aggregating multi-scale feature representations and modeling long-range dependencies between pixels.
Read more8/27/2024