Manga109Dialog: A Large-scale Dialogue Dataset for Comics Speaker Detection
2306.17469
0
0
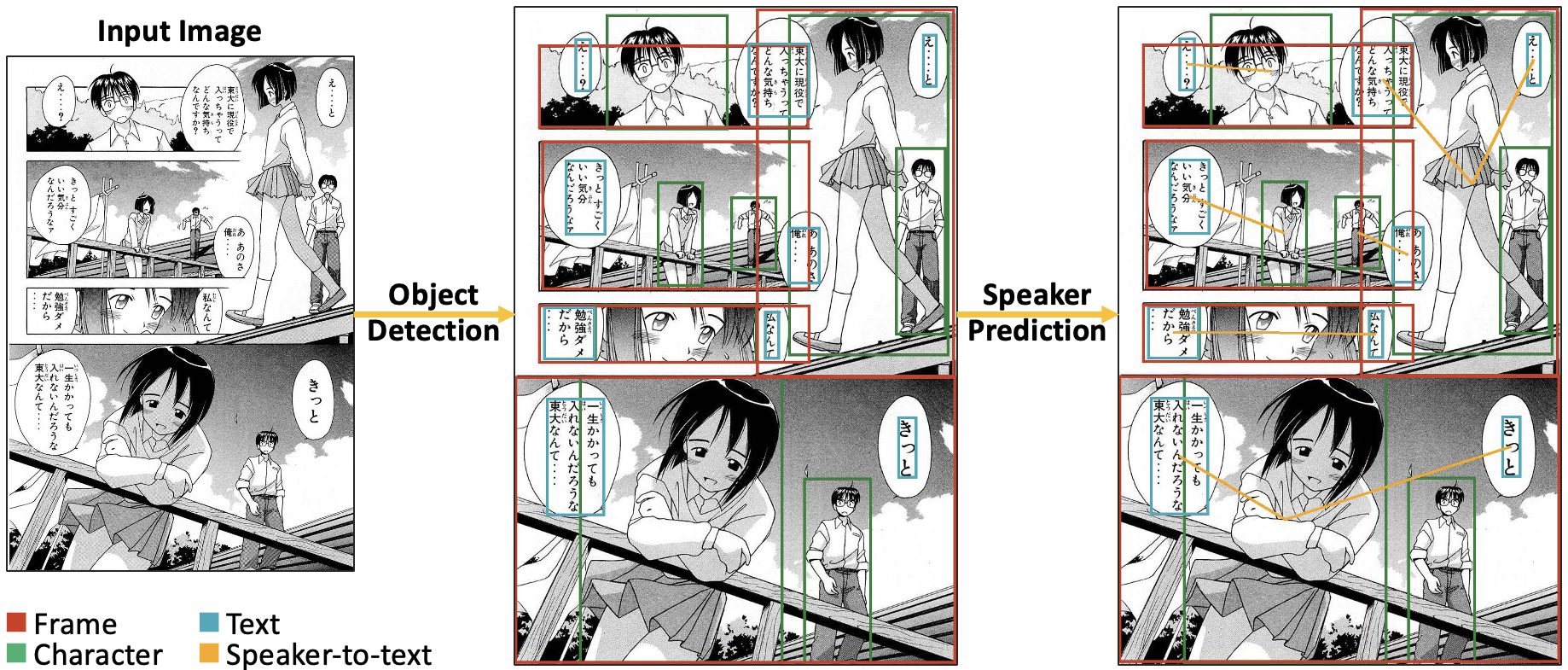
Abstract
The expanding market for e-comics has spurred interest in the development of automated methods to analyze comics. For further understanding of comics, an automated approach is needed to link text in comics to characters speaking the words. Comics speaker detection research has practical applications, such as automatic character assignment for audiobooks, automatic translation according to characters' personalities, and inference of character relationships and stories. To deal with the problem of insufficient speaker-to-text annotations, we created a new annotation dataset Manga109Dialog based on Manga109. Manga109Dialog is the world's largest comics speaker annotation dataset, containing 132,692 speaker-to-text pairs. We further divided our dataset into different levels by prediction difficulties to evaluate speaker detection methods more appropriately. Unlike existing methods mainly based on distances, we propose a deep learning-based method using scene graph generation models. Due to the unique features of comics, we enhance the performance of our proposed model by considering the frame reading order. We conducted experiments using Manga109Dialog and other datasets. Experimental results demonstrate that our scene-graph-based approach outperforms existing methods, achieving a prediction accuracy of over 75%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces Manga109Dialog, a large-scale dialogue dataset for comics speaker detection.
- The dataset is derived from the popular Manga109 dataset, which consists of Japanese manga (comic) pages with annotations.
- Manga109Dialog provides annotations for speaker detection, allowing researchers to develop and evaluate algorithms that can identify who is speaking in comic dialogue.
- The dataset contains over 200,000 dialogue instances across 109 manga series, making it one of the largest resources of its kind.
Plain English Explanation
The paper presents a new dataset called Manga109Dialog that can be used to train and test AI models for detecting who is speaking in comic book dialogues. Comic books, or manga as they are known in Japan, often have complex conversations between multiple characters in each panel. [https://aimodels.fyi/papers/arxiv/zero-shot-character-identification-speaker-prediction-comics] Being able to automatically identify which character is saying each line of dialogue is a valuable capability for applications like [https://aimodels.fyi/papers/arxiv/audio-dialogues-dialogues-dataset-audio-music-understanding]understanding the narrative and [https://aimodels.fyi/papers/arxiv/movie101v2-improved-movie-narration-benchmark]generating audio for animated adaptations.
The Manga109Dialog dataset is built upon the popular Manga109 dataset, which contains a large collection of Japanese manga pages with various annotations. The researchers added new annotations to this existing dataset that mark which character is speaking in each dialogue bubble. This resulted in over 200,000 annotated dialogue instances across 109 different manga series, making it one of the biggest resources of its kind.
The availability of this sizable, high-quality dataset should enable researchers to develop more accurate and robust [https://aimodels.fyi/papers/arxiv/librisqa-novel-dataset-framework-spoken-question-answering]speaker detection models for comics. These models could then be applied to tasks like [https://aimodels.fyi/papers/arxiv/large-language-model-based-situational-dialogues-second]generating realistic dialogues for animated adaptations of comic books.
Technical Explanation
The researchers created the Manga109Dialog dataset by adding speaker annotations to the existing Manga109 dataset, which contains over 109 Japanese manga series with page-level annotations. To do this, they developed a custom annotation tool that allowed workers to label which character was speaking in each dialogue bubble.
The resulting dataset contains 201,873 dialogue instances across the 109 manga series, with each dialogue bubble annotated with the speaking character's identity. The dataset is split into training, validation, and test sets to support the development and evaluation of speaker detection models.
The researchers benchmark the dataset using several state-of-the-art speaker detection models, including ones based on transformer language models and multi-modal approaches that leverage both text and visual information. Their results show that the dataset presents significant challenges, with the best-performing models achieving only around 75% accuracy on the test set.
The large scale and diversity of the Manga109Dialog dataset make it a valuable resource for advancing research in comics-based speaker detection. The dataset covers a wide range of manga genres, art styles, and dialogue patterns, providing a more realistic and challenging test bed compared to previous, smaller-scale datasets.
Critical Analysis
The Manga109Dialog dataset represents an important advance in the field of comics understanding, providing a large-scale benchmark for speaker detection that can drive progress in areas like [https://aimodels.fyi/papers/arxiv/large-language-model-based-situational-dialogues-second]narrative generation and [https://aimodels.fyi/papers/arxiv/audio-dialogues-dialogues-dataset-audio-music-understanding]audio adaptation.
However, the paper also acknowledges several limitations of the dataset. First, the annotations were created by crowdsourced workers, which could introduce inconsistencies or errors. The researchers note that further validation of the annotations would be valuable.
Additionally, the dataset is limited to Japanese manga, which have unique visual and linguistic characteristics compared to Western comics. Expanding the dataset to include a broader range of comic styles and languages would make the speaker detection task more generally applicable.
The authors also point out that the dataset focuses solely on speaker detection, without annotations for other important elements like character identification, emotion, or the overall narrative structure. Incorporating these additional annotations could enable more holistic understanding of comics.
Despite these limitations, Manga109Dialog represents a significant step forward for the field of comics AI. The dataset will undoubtedly spur the development of more advanced speaker detection models, paving the way for a new generation of tools and applications for comics analysis and adaptation.
Conclusion
The Manga109Dialog dataset introduced in this paper is a valuable resource for advancing research in comics-based speaker detection. By providing a large-scale, high-quality dataset of annotated dialogue, the researchers have enabled the development of more accurate and robust speaker identification models.
These models can then be applied to a variety of applications, such as [https://aimodels.fyi/papers/arxiv/audio-dialogues-dialogues-dataset-audio-music-understanding]generating audio for animated manga adaptations or [https://aimodels.fyi/papers/arxiv/large-language-model-based-situational-dialogues-second]creating interactive narrative experiences. The dataset's diversity and scale also make it a suitable testbed for exploring more general techniques for understanding the complex interplay of text, characters, and visual storytelling in comics.
While the paper identifies some limitations of the dataset, such as the need for further annotation validation and expansion to non-Japanese comics, Manga109Dialog nonetheless represents a significant step forward for the field of comics AI. The availability of this resource will undoubtedly inspire new research directions and facilitate advancements in our ability to comprehend and utilize the rich medium of comics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
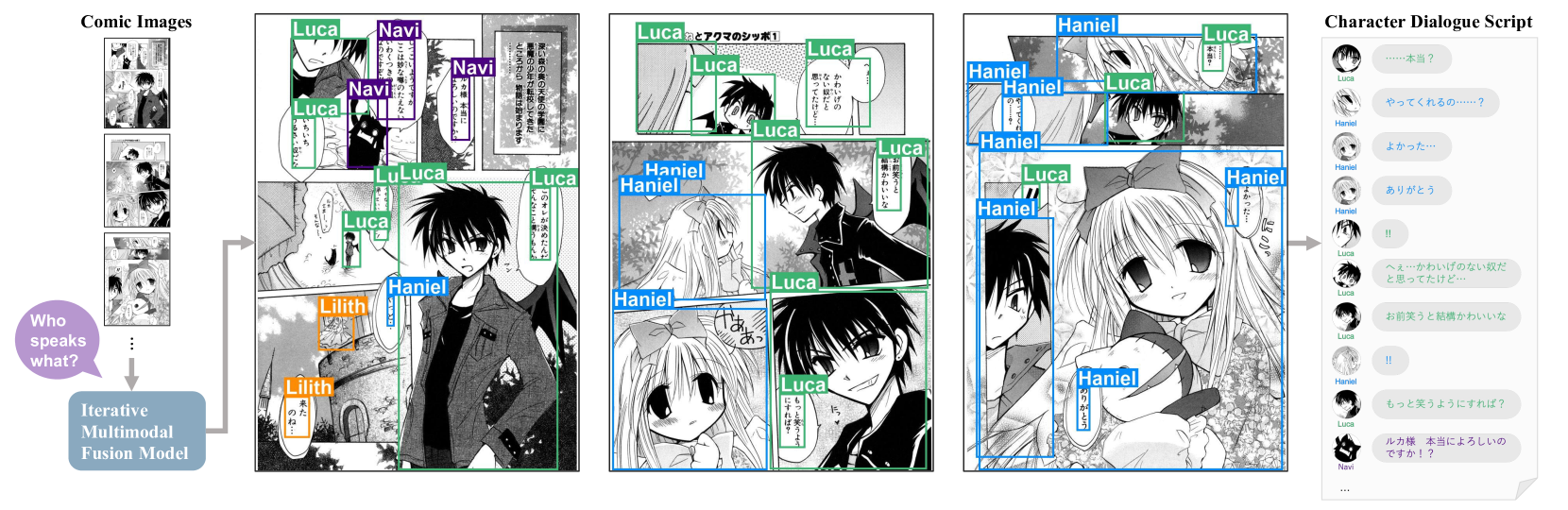
Zero-Shot Character Identification and Speaker Prediction in Comics via Iterative Multimodal Fusion
Yingxuan Li, Ryota Hinami, Kiyoharu Aizawa, Yusuke Matsui
0
0
Recognizing characters and predicting speakers of dialogue are critical for comic processing tasks, such as voice generation or translation. However, because characters vary by comic title, supervised learning approaches like training character classifiers which require specific annotations for each comic title are infeasible. This motivates us to propose a novel zero-shot approach, allowing machines to identify characters and predict speaker names based solely on unannotated comic images. In spite of their importance in real-world applications, these task have largely remained unexplored due to challenges in story comprehension and multimodal integration. Recent large language models (LLMs) have shown great capability for text understanding and reasoning, while their application to multimodal content analysis is still an open problem. To address this problem, we propose an iterative multimodal framework, the first to employ multimodal information for both character identification and speaker prediction tasks. Our experiments demonstrate the effectiveness of the proposed framework, establishing a robust baseline for these tasks. Furthermore, since our method requires no training data or annotations, it can be used as-is on any comic series.
4/23/2024

Sakuga-42M Dataset: Scaling Up Cartoon Research
Zhenglin Pan, Yu Zhu, Yuxuan Mu
0
0
Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and generating natural video by scaling large models with extensive datasets, they are not as effective for cartoons. Through our empirical experiments, we argue that this ineffectiveness stems from a notable bias in hand-drawn cartoons that diverges from the distribution of natural videos. Can we harness the success of the scaling paradigm to benefit cartoon research? Unfortunately, until now, there has not been a sizable cartoon dataset available for exploration. In this research, we propose the Sakuga-42M Dataset, the first large-scale cartoon animation dataset. Sakuga-42M comprises 42 million keyframes covering various artistic styles, regions, and years, with comprehensive semantic annotations including video-text description pairs, anime tags, content taxonomies, etc. We pioneer the benefits of such a large-scale cartoon dataset on comprehension and generation tasks by finetuning contemporary foundation models like Video CLIP, Video Mamba, and SVD, achieving outstanding performance on cartoon-related tasks. Our motivation is to introduce large-scaling to cartoon research and foster generalization and robustness in future cartoon applications. Dataset, Code, and Pretrained Models will be publicly available.
5/14/2024
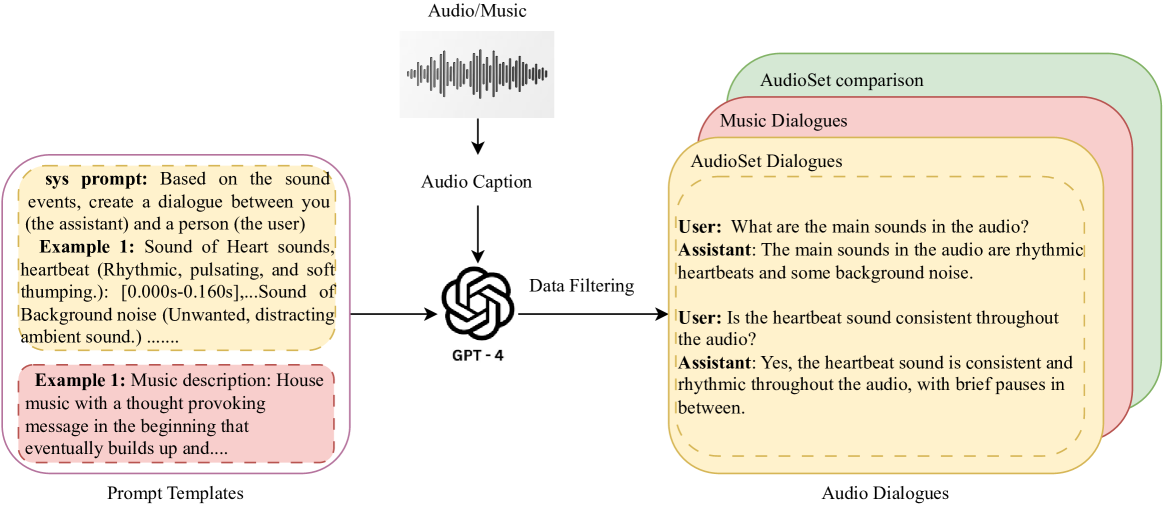
Audio Dialogues: Dialogues dataset for audio and music understanding
Arushi Goel, Zhifeng Kong, Rafael Valle, Bryan Catanzaro
0
0
Existing datasets for audio understanding primarily focus on single-turn interactions (i.e. audio captioning, audio question answering) for describing audio in natural language, thus limiting understanding audio via interactive dialogue. To address this gap, we introduce Audio Dialogues: a multi-turn dialogue dataset containing 163.8k samples for general audio sounds and music. In addition to dialogues, Audio Dialogues also has question-answer pairs to understand and compare multiple input audios together. Audio Dialogues leverages a prompting-based approach and caption annotations from existing datasets to generate multi-turn dialogues using a Large Language Model (LLM). We evaluate existing audio-augmented large language models on our proposed dataset to demonstrate the complexity and applicability of Audio Dialogues. Our code for generating the dataset will be made publicly available. Detailed prompts and generated dialogues can be found on the demo website https://audiodialogues.github.io/.
4/12/2024

Movie101v2: Improved Movie Narration Benchmark
Zihao Yue, Yepeng Zhang, Ziheng Wang, Qin Jin
0
0
Automatic movie narration targets at creating video-aligned plot descriptions to assist visually impaired audiences. It differs from standard video captioning in that it requires not only describing key visual details but also inferring the plots developed across multiple movie shots, thus posing unique and ongoing challenges. To advance the development of automatic movie narrating systems, we first revisit the limitations of existing datasets and develop a large-scale, bilingual movie narration dataset, Movie101v2. Second, taking into account the essential difficulties in achieving applicable movie narration, we break the long-term goal into three progressive stages and tentatively focus on the initial stages featuring understanding within individual clips. We also introduce a new narration assessment to align with our staged task goals. Third, using our new dataset, we baseline several leading large vision-language models, including GPT-4V, and conduct in-depth investigations into the challenges current models face for movie narration generation. Our findings reveal that achieving applicable movie narration generation is a fascinating goal that requires thorough research.
4/23/2024