Sakuga-42M Dataset: Scaling Up Cartoon Research
2405.07425
84
0

Abstract
Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and generating natural video by scaling large models with extensive datasets, they are not as effective for cartoons. Through our empirical experiments, we argue that this ineffectiveness stems from a notable bias in hand-drawn cartoons that diverges from the distribution of natural videos. Can we harness the success of the scaling paradigm to benefit cartoon research? Unfortunately, until now, there has not been a sizable cartoon dataset available for exploration. In this research, we propose the Sakuga-42M Dataset, the first large-scale cartoon animation dataset. Sakuga-42M comprises 42 million keyframes covering various artistic styles, regions, and years, with comprehensive semantic annotations including video-text description pairs, anime tags, content taxonomies, etc. We pioneer the benefits of such a large-scale cartoon dataset on comprehension and generation tasks by finetuning contemporary foundation models like Video CLIP, Video Mamba, and SVD, achieving outstanding performance on cartoon-related tasks. Our motivation is to introduce large-scaling to cartoon research and foster generalization and robustness in future cartoon applications. Dataset, Code, and Pretrained Models will be publicly available.
Create account to get full access
Overview
- The Sakuga-42M dataset is a large-scale dataset of cartoon animation frames that aims to advance research in this domain.
- It contains 42 million frames from over 1,200 animated series, making it one of the largest datasets of its kind.
- The dataset provides a wealth of data for training and evaluating machine learning models for tasks like cartoon frame classification, video summarization, text generation from skeleton data, and text-to-video animation.
Plain English Explanation
The Sakuga-42M dataset is a massive collection of frames from cartoon animations. It has over 42 million frames from more than 1,200 different animated series. This dataset is designed to help researchers and developers who are working on various tasks related to cartoon and animation content, such as automatically classifying the style of animation, summarizing the key moments in an animated video, generating descriptions of animated characters and scenes, or even creating new animations from text descriptions.
Having access to such a large and diverse dataset of cartoon frames can be really useful for training powerful machine learning models that can understand and generate cartoon-like content. Researchers can use this dataset to develop more accurate cartoon frame classifiers, build better video summarization systems that can identify the key moments in an animated video, create text generation models that can describe cartoon scenes in detail, or even generate new cartoon-style animations from text descriptions. The large scale and diversity of the Sakuga-42M dataset make it a valuable resource for advancing the state-of-the-art in these and other areas of cartoon and animation research.
Technical Explanation
The Sakuga-42M dataset is a large-scale collection of cartoon animation frames that aims to accelerate research in this domain. It contains over 42 million frames from more than 1,200 animated series, making it one of the largest datasets of its kind.
The dataset was constructed by crawling and curating animation frames from various online sources, with a focus on diverse and high-quality cartoon content. The frames span a wide range of animation styles, genres, and production values, providing a rich source of data for training and evaluating machine learning models.
Some of the key use cases for the Sakuga-42M dataset include:
- Cartoon frame classification: Developing models that can accurately identify the style, genre, or production characteristics of individual animation frames.
- Video summarization: Training systems that can automatically identify and highlight the most important or visually striking moments in an animated video.
- Text generation from skeleton data: Generating detailed textual descriptions of cartoon characters, scenes, and actions based on the underlying skeletal animation data.
- Text-to-video animation: Developing models that can create new cartoon-style animations directly from text descriptions.
The large scale and diversity of the Sakuga-42M dataset enable researchers to train more robust and generalizable models for these and other cartoon-related tasks. By providing a consistent and high-quality source of cartoon data, the dataset aims to drive progress in the field of cartoon and animation research.
Critical Analysis
The Sakuga-42M dataset represents a significant advancement in the availability of large-scale cartoon data for research purposes. By curating a diverse collection of over 42 million frames from a wide range of animated series, the dataset provides researchers with a wealth of data to work with.
One potential limitation of the dataset is the lack of additional metadata or annotations beyond the raw frame data. While the diversity of the content is a strength, the absence of detailed labels or contextual information about the scenes, characters, or artistic styles represented in the dataset may limit its usefulness for certain types of research. Incorporating additional metadata or annotations could enhance the dataset's value for tasks like character recognition, scene understanding, or style analysis.
Another area for potential improvement is the dataset's geographical and cultural diversity. While the creators have made efforts to include a range of animation styles and genres, the dataset may still be skewed towards certain regional or cultural traditions, particularly those from Japan and other Asian countries that dominate the global animation industry. Expanding the dataset to include a more representative sample of cartoon content from diverse global sources could broaden its applicability and help address potential biases.
Despite these potential limitations, the Sakuga-42M dataset represents a significant step forward in enabling large-scale research on cartoon and animation content. By providing researchers with access to this extensive collection of high-quality cartoon frames, the dataset has the potential to drive innovative developments in areas like racial classification, video summarization, text generation, and animation synthesis. As the field of cartoon and animation research continues to evolve, the Sakuga-42M dataset will likely play an increasingly important role in advancing the state of the art.
Conclusion
The Sakuga-42M dataset is a groundbreaking collection of over 42 million cartoon animation frames that aims to accelerate research in this domain. By providing researchers with access to a large and diverse dataset of high-quality cartoon content, the Sakuga-42M dataset has the potential to drive significant advancements in areas like cartoon frame classification, video summarization, text-to-animation generation, and beyond.
While the dataset may have some room for improvement, such as the incorporation of additional metadata or a broader global representation, it represents a significant step forward in making cartoon and animation research more accessible and scalable. As the field continues to evolve, the Sakuga-42M dataset will likely play a crucial role in enabling researchers to develop more sophisticated and capable models for understanding, generating, and interacting with cartoon content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
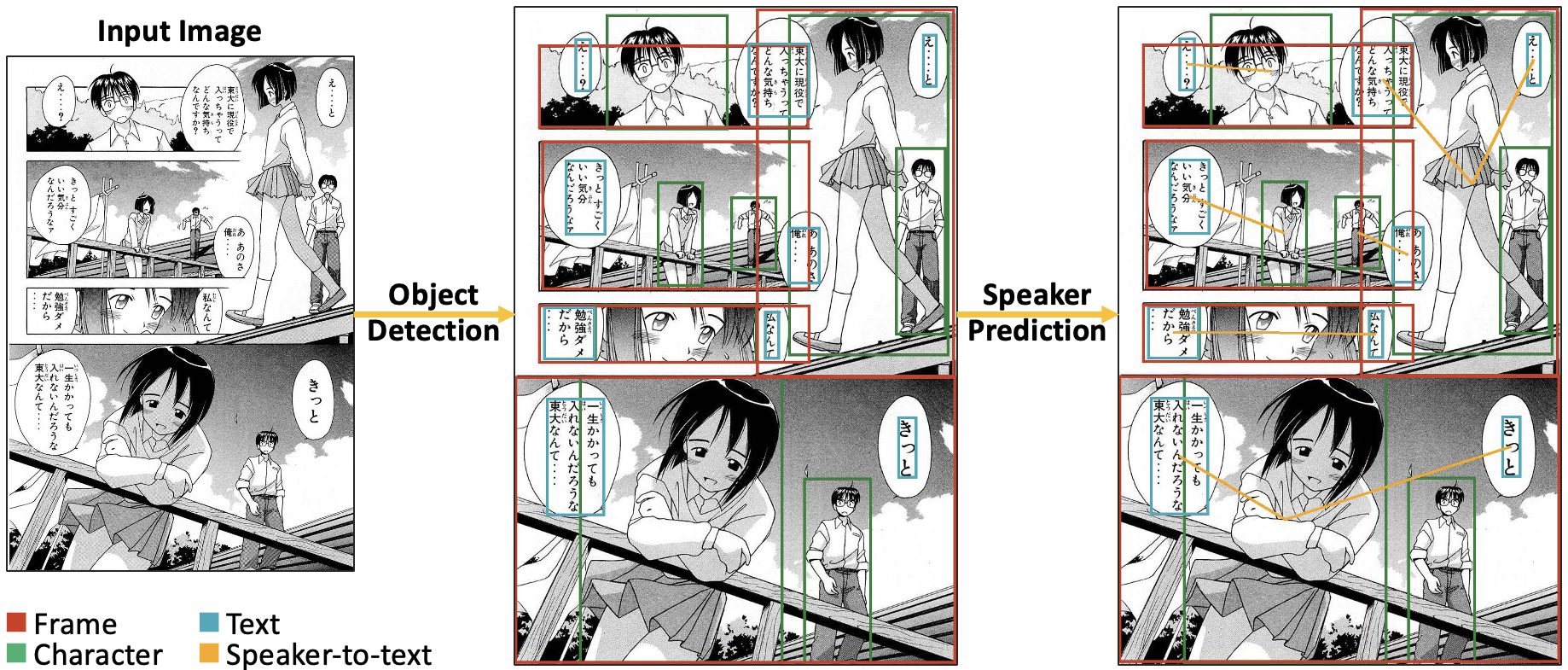
Manga109Dialog: A Large-scale Dialogue Dataset for Comics Speaker Detection
Yingxuan Li, Kiyoharu Aizawa, Yusuke Matsui
0
0
The expanding market for e-comics has spurred interest in the development of automated methods to analyze comics. For further understanding of comics, an automated approach is needed to link text in comics to characters speaking the words. Comics speaker detection research has practical applications, such as automatic character assignment for audiobooks, automatic translation according to characters' personalities, and inference of character relationships and stories. To deal with the problem of insufficient speaker-to-text annotations, we created a new annotation dataset Manga109Dialog based on Manga109. Manga109Dialog is the world's largest comics speaker annotation dataset, containing 132,692 speaker-to-text pairs. We further divided our dataset into different levels by prediction difficulties to evaluate speaker detection methods more appropriately. Unlike existing methods mainly based on distances, we propose a deep learning-based method using scene graph generation models. Due to the unique features of comics, we enhance the performance of our proposed model by considering the frame reading order. We conducted experiments using Manga109Dialog and other datasets. Experimental results demonstrate that our scene-graph-based approach outperforms existing methods, achieving a prediction accuracy of over 75%.
4/23/2024
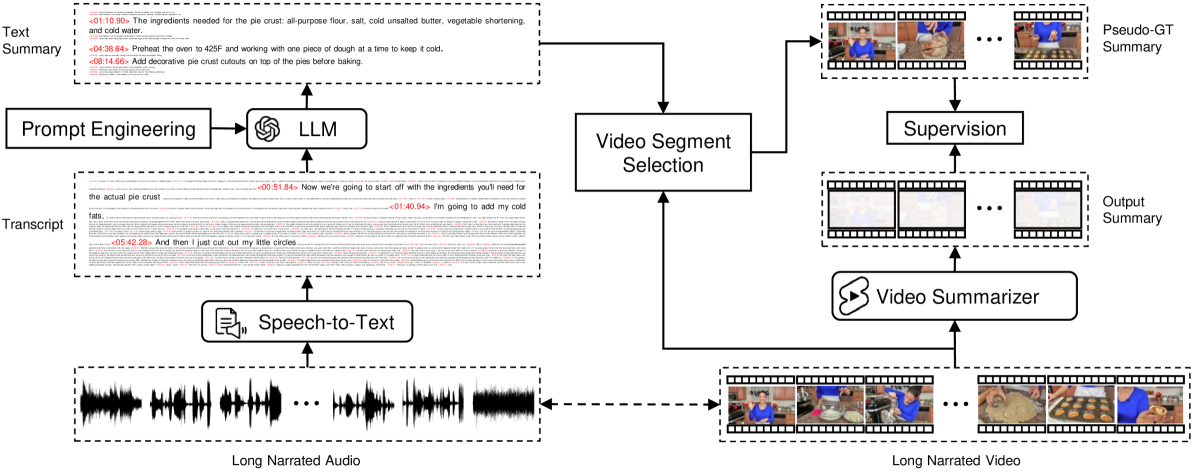
Scaling Up Video Summarization Pretraining with Large Language Models
Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
0
0
Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
4/5/2024

Short Film Dataset (SFD): A Benchmark for Story-Level Video Understanding
Ridouane Ghermi, Xi Wang, Vicky Kalogeiton, Ivan Laptev
0
0
Recent advances in vision-language models have significantly propelled video understanding. Existing datasets and tasks, however, have notable limitations. Most datasets are confined to short videos with limited events and narrow narratives. For example, datasets with instructional and egocentric videos often document the activities of one person in a single scene. Although some movie datasets offer richer content, they are often limited to short-term tasks, lack publicly available videos and frequently encounter data leakage given the use of movie forums and other resources in LLM training. To address the above limitations, we propose the Short Film Dataset (SFD) with 1,078 publicly available amateur movies, a wide variety of genres and minimal data leakage issues. SFD offers long-term story-oriented video tasks in the form of multiple-choice and open-ended question answering. Our extensive experiments emphasize the need for long-term reasoning to solve SFD tasks. Notably, we find strong signals in movie transcripts leading to the on-par performance of people and LLMs. We also show significantly lower performance of current models compared to people when using vision data alone.
6/17/2024

SkelCap: Automated Generation of Descriptive Text from Skeleton Keypoint Sequences
Ali Emre Keskin, Hacer Yalim Keles
0
0
Numerous sign language datasets exist, yet they typically cover only a limited selection of the thousands of signs used globally. Moreover, creating diverse sign language datasets is an expensive and challenging task due to the costs associated with gathering a varied group of signers. Motivated by these challenges, we aimed to develop a solution that addresses these limitations. In this context, we focused on textually describing body movements from skeleton keypoint sequences, leading to the creation of a new dataset. We structured this dataset around AUTSL, a comprehensive isolated Turkish sign language dataset. We also developed a baseline model, SkelCap, which can generate textual descriptions of body movements. This model processes the skeleton keypoints data as a vector, applies a fully connected layer for embedding, and utilizes a transformer neural network for sequence-to-sequence modeling. We conducted extensive evaluations of our model, including signer-agnostic and sign-agnostic assessments. The model achieved promising results, with a ROUGE-L score of 0.98 and a BLEU-4 score of 0.94 in the signer-agnostic evaluation. The dataset we have prepared, namely the AUTSL-SkelCap, will be made publicly available soon.
5/7/2024