Zero-Shot Character Identification and Speaker Prediction in Comics via Iterative Multimodal Fusion
2404.13993
0
3
Abstract
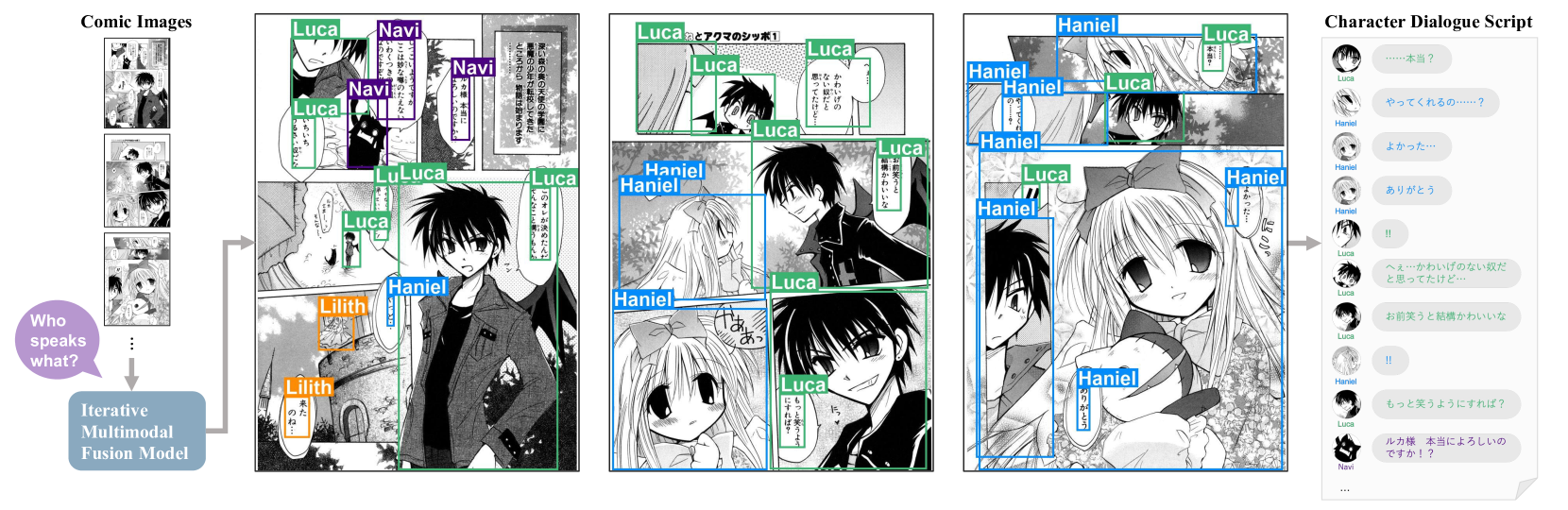
Recognizing characters and predicting speakers of dialogue are critical for comic processing tasks, such as voice generation or translation. However, because characters vary by comic title, supervised learning approaches like training character classifiers which require specific annotations for each comic title are infeasible. This motivates us to propose a novel zero-shot approach, allowing machines to identify characters and predict speaker names based solely on unannotated comic images. In spite of their importance in real-world applications, these task have largely remained unexplored due to challenges in story comprehension and multimodal integration. Recent large language models (LLMs) have shown great capability for text understanding and reasoning, while their application to multimodal content analysis is still an open problem. To address this problem, we propose an iterative multimodal framework, the first to employ multimodal information for both character identification and speaker prediction tasks. Our experiments demonstrate the effectiveness of the proposed framework, establishing a robust baseline for these tasks. Furthermore, since our method requires no training data or annotations, it can be used as-is on any comic series.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach for zero-shot character identification and speaker prediction in comics using iterative multimodal fusion.
- The method aims to leverage both visual and textual information to accurately identify characters and predict speakers in comic panels, even for characters that have not been seen during training.
- The research explores the challenges of comics understanding and demonstrates how combining different modalities can improve performance on these tasks.
Plain English Explanation
The researchers have developed a system that can identify characters and predict who is speaking in comic book panels, even for characters that the system has never seen before. This is a challenging problem because comics contain both visual and textual information that needs to be understood.
The key insight is that by combining the visual information (like the character's appearance) and the textual information (like the dialogue), the system can make more accurate predictions about the characters and who is speaking. The system goes through an iterative process, using the information from both modalities to refine its understanding.
This is an important advancement because it allows systems to understand comics more deeply, which could have applications in areas like digital content moderation, assistive technology for the visually impaired, and even creative tools for comic book authors. Being able to accurately identify characters and predict speakers, even for new characters, is a significant step forward in making computers better at understanding and interpreting visual-textual media.
Technical Explanation
The paper presents a novel approach for zero-shot character identification and speaker prediction in comics using an iterative multimodal fusion framework. The method aims to leverage both visual and textual information to accurately identify characters and predict speakers in comic panels, even for characters that have not been seen during training.
The core of the approach is a multimodal fusion module that iteratively combines visual and textual features to refine the predictions. The visual features are extracted from the character appearances in the panels, while the textual features are derived from the dialogue text. These features are then fused and used to make character identification and speaker prediction decisions.
The researchers evaluate their approach on the Manga109 Dialog dataset, which provides ground truth annotations for character identities and speakers. The results demonstrate that the iterative multimodal fusion approach outperforms unimodal baselines and single-stage multimodal methods, highlighting the benefits of the proposed technique.
Critical Analysis
The paper presents a well-designed and thorough investigation into the challenges of zero-shot character identification and speaker prediction in comics. The iterative multimodal fusion approach is a novel contribution that effectively leverages both visual and textual information to make accurate predictions, even for unseen characters.
One potential limitation of the work is the reliance on the Manga109 Dialog dataset, which may not capture the full diversity of comic book styles and genres. It would be valuable to evaluate the approach on a more comprehensive dataset to assess its generalizability.
Additionally, the paper does not deeply explore the interpretability of the model's decision-making process. Providing more insights into how the visual and textual features are combined and weighted could help users understand the system's reasoning and build trust in its predictions.
Further research could also investigate the application of diffusion-based models for zero-shot medical image-to-image translation or explore data alignment techniques for zero-shot concept generation in dermatology, which could provide additional insights into the challenges of zero-shot learning in visual-textual domains.
Conclusion
This paper presents a novel approach for zero-shot character identification and speaker prediction in comics using iterative multimodal fusion. By combining visual and textual information, the system can accurately identify characters and predict speakers, even for characters not seen during training.
The research demonstrates the potential of multimodal techniques to overcome the challenges of comics understanding and opens up new possibilities for applications in digital content moderation, assistive technology, and creative tools. The work represents an important step forward in developing more robust and versatile systems for interpreting and understanding visual-textual media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Manga109Dialog: A Large-scale Dialogue Dataset for Comics Speaker Detection
Yingxuan Li, Kiyoharu Aizawa, Yusuke Matsui
0
0
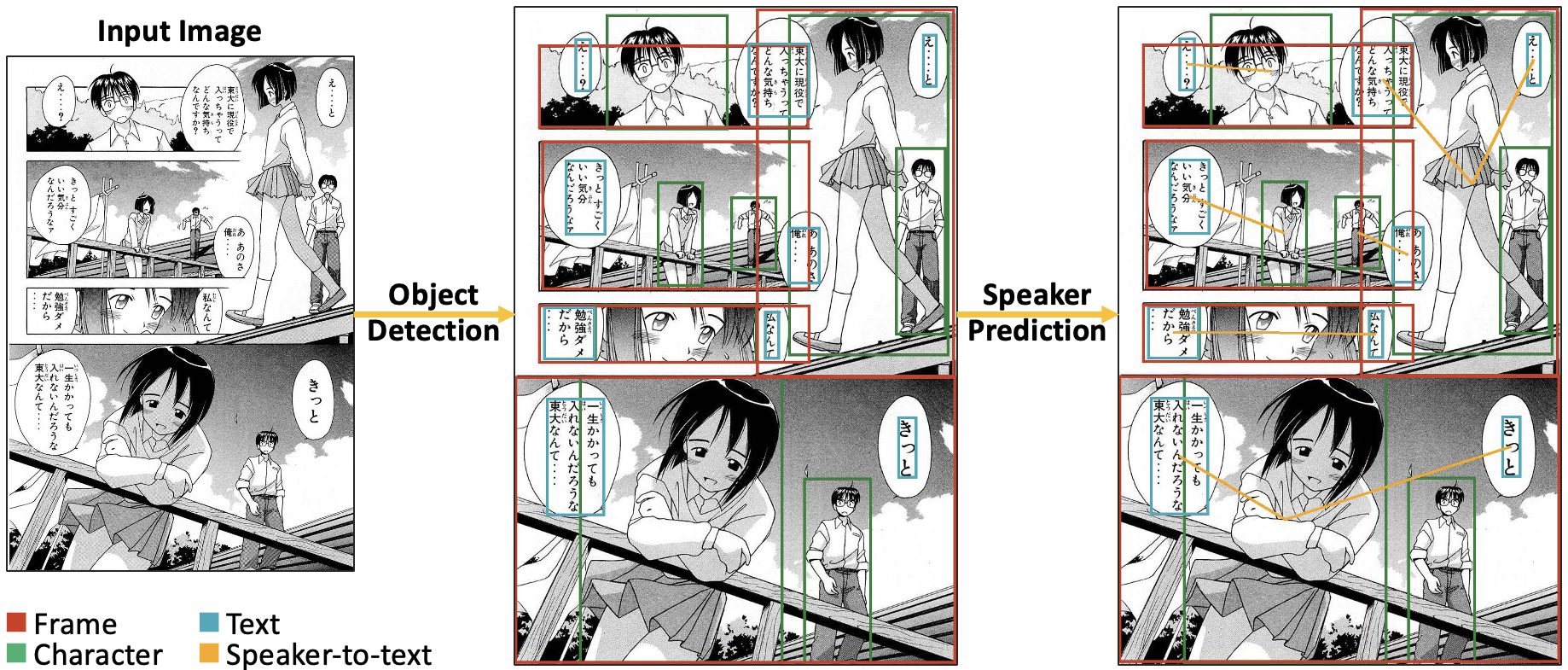
The expanding market for e-comics has spurred interest in the development of automated methods to analyze comics. For further understanding of comics, an automated approach is needed to link text in comics to characters speaking the words. Comics speaker detection research has practical applications, such as automatic character assignment for audiobooks, automatic translation according to characters' personalities, and inference of character relationships and stories. To deal with the problem of insufficient speaker-to-text annotations, we created a new annotation dataset Manga109Dialog based on Manga109. Manga109Dialog is the world's largest comics speaker annotation dataset, containing 132,692 speaker-to-text pairs. We further divided our dataset into different levels by prediction difficulties to evaluate speaker detection methods more appropriately. Unlike existing methods mainly based on distances, we propose a deep learning-based method using scene graph generation models. Due to the unique features of comics, we enhance the performance of our proposed model by considering the frame reading order. We conducted experiments using Manga109Dialog and other datasets. Experimental results demonstrate that our scene-graph-based approach outperforms existing methods, achieving a prediction accuracy of over 75%.
4/23/2024

Zero-Shot Relational Learning for Multimodal Knowledge Graphs
Rui Cai, Shichao Pei, Xiangliang Zhang
0
0
Relational learning is an essential task in the domain of knowledge representation, particularly in knowledge graph completion (KGC).While relational learning in traditional single-modal settings has been extensively studied, exploring it within a multimodal KGC context presents distinct challenges and opportunities. One of the major challenges is inference on newly discovered relations without any associated training data. This zero-shot relational learning scenario poses unique requirements for multimodal KGC, i.e., utilizing multimodality to facilitate relational learning. However, existing works fail to support the leverage of multimodal information and leave the problem unexplored. In this paper, we propose a novel end-to-end framework, consisting of three components, i.e., multimodal learner, structure consolidator, and relation embedding generator, to integrate diverse multimodal information and knowledge graph structures to facilitate the zero-shot relational learning. Evaluation results on two multimodal knowledge graphs demonstrate the superior performance of our proposed method.
4/10/2024
👁️
Retrieval Enhanced Zero-Shot Video Captioning
Yunchuan Ma, Laiyun Qing, Guorong Li, Yuankai Qi, Quan Z. Sheng, Qingming Huang
0
0
Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
5/14/2024
New!Distilling Implicit Multimodal Knowledge into LLMs for Zero-Resource Dialogue Generation
Bo Zhang, Hui Ma, Jian Ding, Jian Wang, Bo Xu, Hongfei Lin
0
0
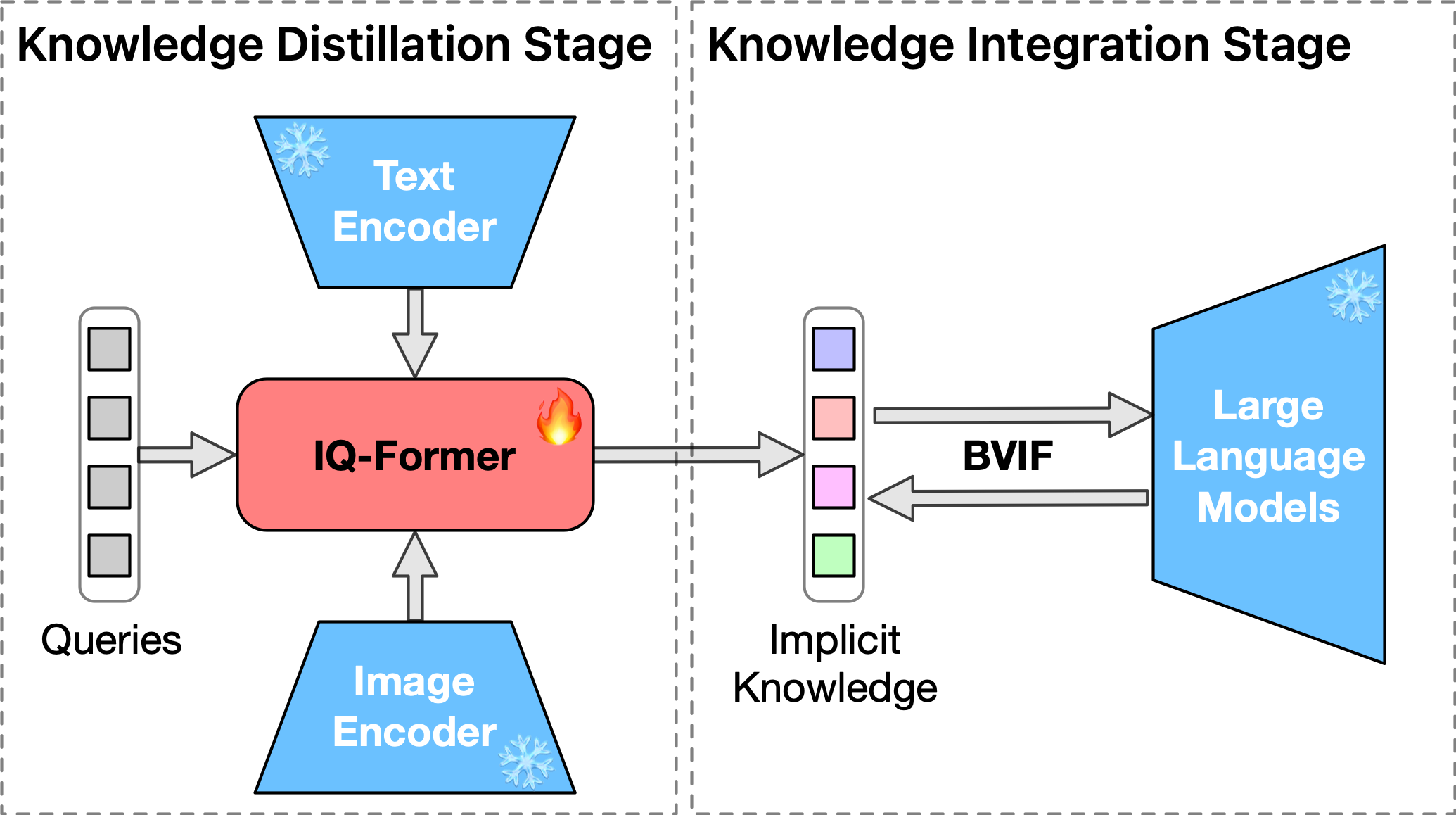
Integrating multimodal knowledge into large language models (LLMs) represents a significant advancement in dialogue generation capabilities. However, the effective incorporation of such knowledge in zero-resource scenarios remains a substantial challenge due to the scarcity of diverse, high-quality dialogue datasets. To address this, we propose the Visual Implicit Knowledge Distillation Framework (VIKDF), an innovative approach aimed at enhancing LLMs for enriched dialogue generation in zero-resource contexts by leveraging implicit multimodal knowledge. VIKDF comprises two main stages: knowledge distillation, using an Implicit Query Transformer to extract and encode visual implicit knowledge from image-text pairs into knowledge vectors; and knowledge integration, employing a novel Bidirectional Variational Information Fusion technique to seamlessly integrate these distilled vectors into LLMs. This enables the LLMs to generate dialogues that are not only coherent and engaging but also exhibit a deep understanding of the context through implicit multimodal cues, effectively overcoming the limitations of zero-resource scenarios. Our extensive experimentation across two dialogue datasets shows that VIKDF outperforms existing state-of-the-art models in generating high-quality dialogues. The code will be publicly available following acceptance.
5/17/2024