Many-Shot In-Context Learning in Multimodal Foundation Models
2405.09798
0
0
Abstract
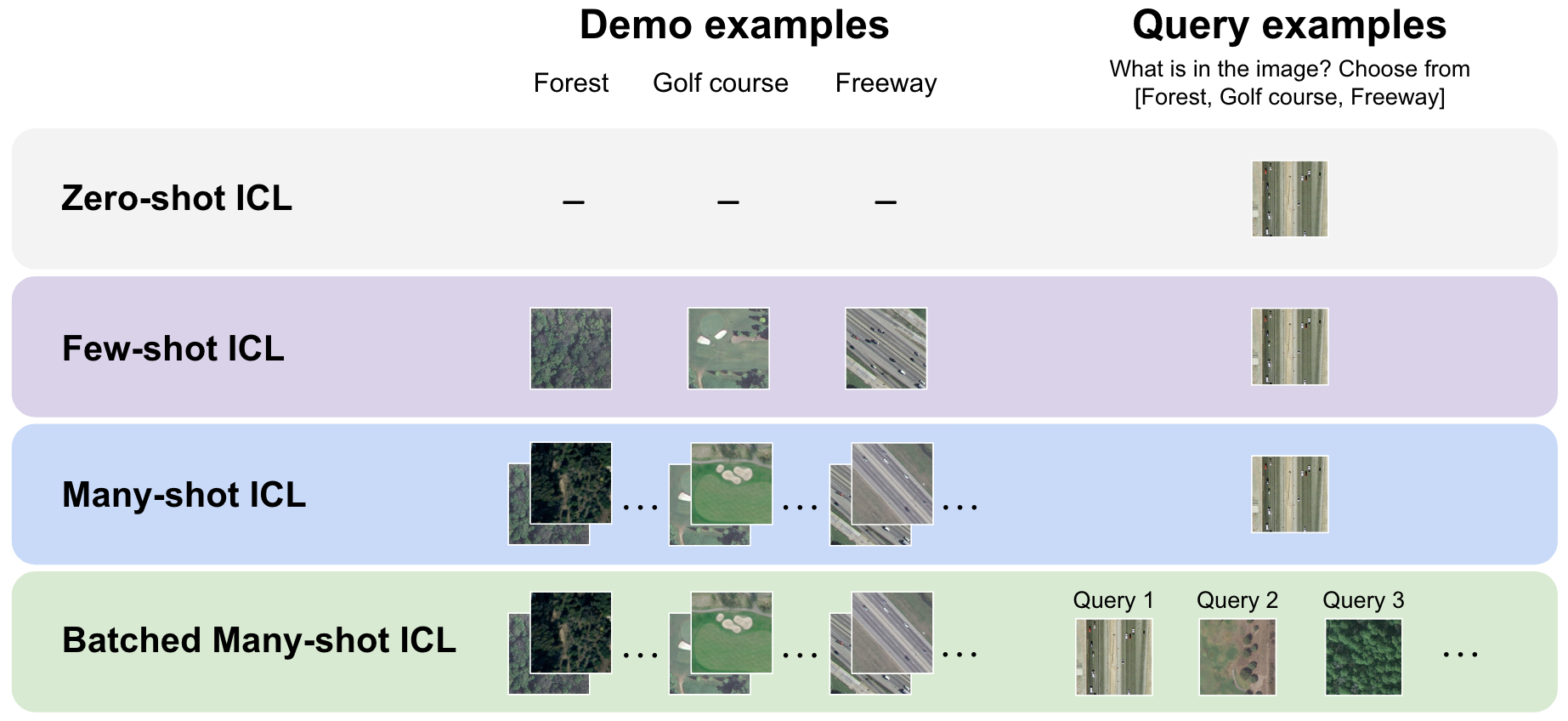
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many-shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL .
Create account to get full access
Overview
- This paper explores "many-shot" in-context learning, where a language model is provided with a large number of examples to inform its response to a new task.
- The researchers investigate how multimodal foundation models, which can process both text and images, can utilize this type of in-context learning approach.
- The paper presents a new benchmark called MILEBench to evaluate the performance of multimodal language models on long-context tasks.
Plain English Explanation
The paper looks at a technique called "many-shot in-context learning" where an AI model is given a lot of example inputs and outputs to help it understand a new task. The researchers wanted to see how this works for AI models that can process both text and images, called "multimodal" models.
They created a new way to test these multimodal models, called MILEBench, which gives the models longer contexts to work with. This helps see how well they can use all the example information to solve new problems.
The key idea is that by providing the model with many relevant examples, it can learn to understand the task more deeply and apply that knowledge to new situations. This could be useful for applications where the model needs to adapt quickly to new information or tasks.
Technical Explanation
The paper focuses on exploring "many-shot in-context learning" in multimodal foundation models. In this approach, the model is presented with a large number of relevant examples (the "many-shot") within the input context, which it can use to inform its response to a new task or query.
The researchers developed a new benchmark called MILEBench to evaluate how well multimodal language models can leverage long input contexts for tasks like question answering and image-text retrieval. This builds on prior work on few-shot learning and multimodal context learning.
The paper presents experiments analyzing how factors like the number of in-context examples, the diversity of examples, and the semantic coherence of the context impact model performance on the MILEBench tasks. The results provide insights into the capabilities and limitations of current multimodal foundation models when it comes to learning from rich contextual information.
Critical Analysis
The paper makes a valuable contribution by introducing the MILEBench dataset and using it to systematically study many-shot in-context learning in multimodal models. However, the experiments are limited to a specific set of tasks and model architectures.
As noted by the authors, the findings may not generalize to other types of tasks or model designs. There are also open questions about the scalability of this approach - at what point do diminishing returns set in as the number of in-context examples grows very large?
Additionally, the paper does not delve into potential societal implications or ethical considerations around the use of such powerful multimodal language models. Deploying these models in real-world applications would require careful monitoring for biases, safety issues, and unintended consequences.
Further research could explore a wider range of tasks, investigate the performance of other multimodal model architectures, and examine the long-term practical impacts of advancing in-context learning capabilities.
Conclusion
This paper takes an important step forward in understanding how multimodal foundation models can leverage large amounts of contextual information to quickly adapt to new tasks through "many-shot" in-context learning. The introduction of the MILEBench dataset provides a valuable new benchmark for evaluating these capabilities.
The findings suggest that multimodal models can indeed benefit from rich contextual cues, but also highlight some of the challenges and limitations of this approach. As AI systems become increasingly adept at learning from context, it will be crucial to carefully study the implications and work to ensure these powerful technologies are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
0
0
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
5/24/2024
Can Many-Shot In-Context Learning Help Long-Context LLM Judges? See More, Judge Better!
Mingyang Song, Mao Zheng, Xuan Luo
0
0
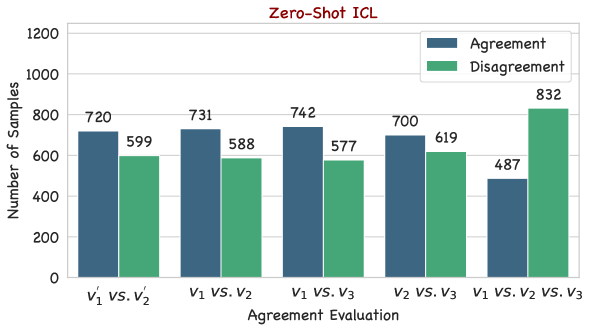
Leveraging Large Language Models (LLMs) as judges for evaluating the performance of LLMs has recently garnered attention. Nonetheless, this type of approach concurrently introduces potential biases from LLMs, raising concerns about the reliability of the evaluation results. To mitigate this issue, we propose and study two versions of many-shot in-context prompts, Reinforced and Unsupervised ICL, for helping GPT-4o-as-a-Judge in single answer grading. The former uses in-context examples with model-generated rationales, and the latter without. Based on the designed prompts, we investigate the impact of scaling the number of in-context examples on the agreement and quality of the evaluation. Furthermore, we first reveal the symbol bias in GPT-4o-as-a-Judge for pairwise comparison and then propose a simple yet effective approach to mitigate it. Experimental results show that advanced long-context LLMs, such as GPT-4o, perform better in the many-shot regime than in the zero-shot regime. Meanwhile, the experimental results further verify the effectiveness of the symbol bias mitigation approach.
6/26/2024
🤯
Multimodal CLIP Inference for Meta-Few-Shot Image Classification
Constance Ferragu, Philomene Chagniot, Vincent Coyette
0
0
In recent literature, few-shot classification has predominantly been defined by the N-way k-shot meta-learning problem. Models designed for this purpose are usually trained to excel on standard benchmarks following a restricted setup, excluding the use of external data. Given the recent advancements in large language and vision models, a question naturally arises: can these models directly perform well on meta-few-shot learning benchmarks? Multimodal foundation models like CLIP, which learn a joint (image, text) embedding, are of particular interest. Indeed, multimodal training has proven to enhance model robustness, especially regarding ambiguities, a limitation frequently observed in the few-shot setup. This study demonstrates that combining modalities from CLIP's text and image encoders outperforms state-of-the-art meta-few-shot learners on widely adopted benchmarks, all without additional training. Our results confirm the potential and robustness of multimodal foundation models like CLIP and serve as a baseline for existing and future approaches leveraging such models.
5/21/2024
What Makes Multimodal In-Context Learning Work?
Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, Benjamin Piwowarski
0
0
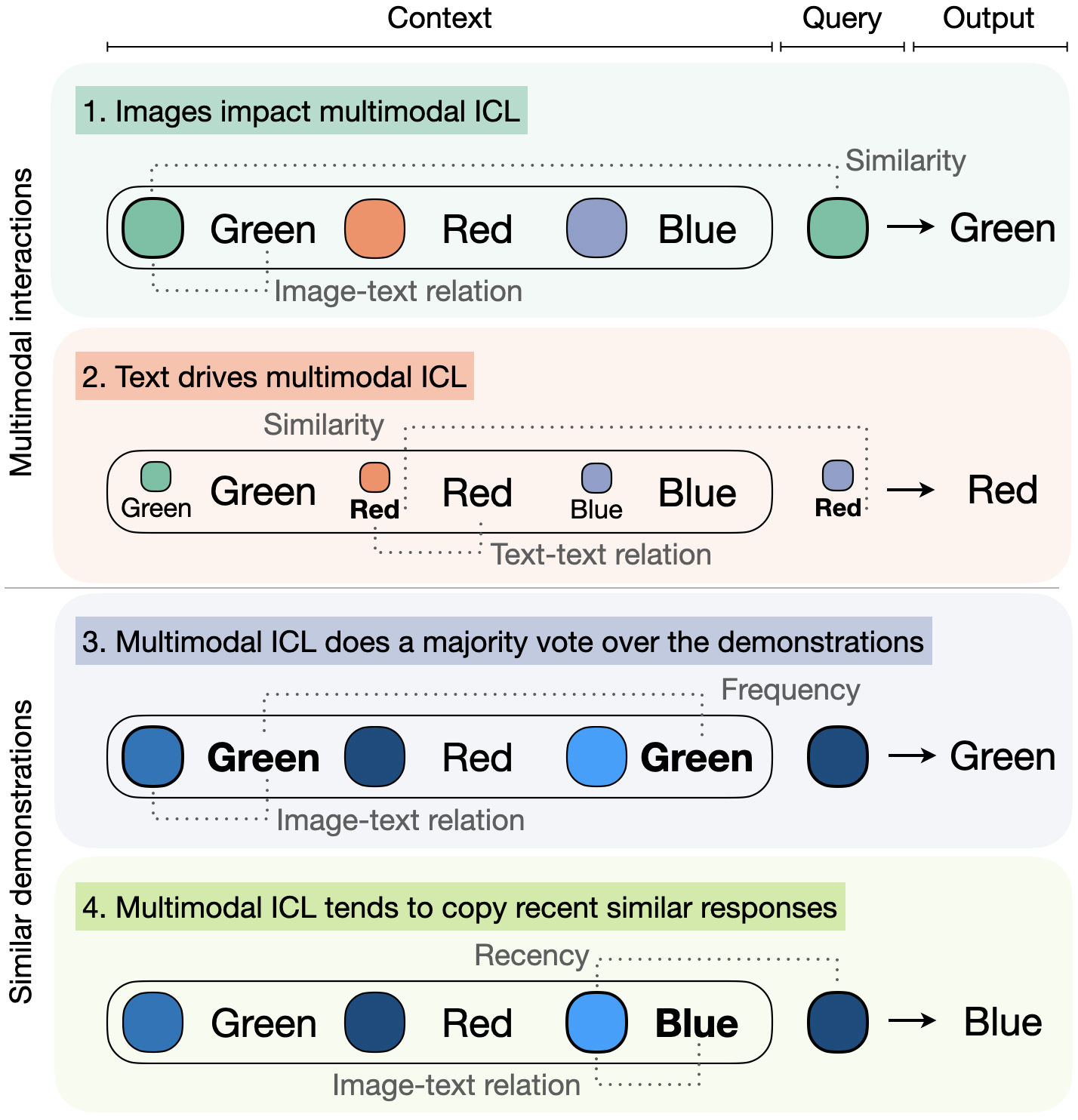
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment. Code available at https://gitlab.com/folbaeni/multimodal-icl
4/26/2024