Evaluation of Few-Shot Learning for Classification Tasks in the Polish Language
2404.17832
0
0
🏷️
Abstract
We introduce a few-shot benchmark consisting of 7 different classification tasks native to the Polish language. We conducted an empirical comparison with 0 and 16 shots between fine-tuning, linear probing, SetFit, and in-context learning (ICL) using various pre-trained commercial and open-source models. Our findings reveal that ICL achieves the best performance, with commercial models like GPT-3.5 and GPT-4 attaining the best performance. However, there remains a significant 14 percentage points gap between our best few-shot learning score and the performance of HerBERT-large fine-tuned on the entire training dataset. Among the techniques, SetFit emerges as the second-best approach, closely followed by linear probing. We observed the worst and most unstable performance with non-linear head fine-tuning. Results for ICL indicate that continual pre-training of models like Mistral-7b or Llama-2-13b on Polish corpora is beneficial. This is confirmed by the improved performances of Bielik-7b and Trurl-13b, respectively. To further support experiments in few-shot learning for Polish, we are releasing handcrafted templates for the ICL.
Create account to get full access
Overview
- The researchers introduce a new few-shot learning benchmark for the Polish language, consisting of 7 different classification tasks.
- They compare the performance of fine-tuning, linear probing, SetFit, and in-context learning (ICL) using various pre-trained commercial and open-source models.
- The findings show that ICL achieves the best performance, with commercial models like GPT-3.5 and GPT-4 attaining the highest scores.
- However, there is still a significant gap between the best few-shot learning score and the performance of a fine-tuned HerBERT-large model on the entire training dataset.
- SetFit emerges as the second-best approach, closely followed by linear probing, while non-linear head fine-tuning performs the worst and most unstably.
- The results for ICL suggest that continual pre-training of models like Mistral-7b or Llama-2-13b on Polish corpora is beneficial, as evidenced by the improved performances of Bielik-7b and Trurl-13b.
- To further support few-shot learning experiments for Polish, the researchers are releasing handcrafted templates for ICL.
Plain English Explanation
The researchers have created a new benchmark for testing how well different machine learning models can perform on a variety of tasks in the Polish language, using only a small amount of training data (a few examples). They compared several different techniques, including fine-tuning, linear probing, SetFit, and in-context learning (ICL), using both commercial and open-source pre-trained models.
The best performance was achieved by ICL, with commercial models like GPT-3.5 and GPT-4 doing the best. However, even the best few-shot model was still significantly worse than a model that was fully trained on all the data. Among the other techniques, SetFit was the second-best, followed by linear probing, while non-linear fine-tuning performed the worst and was the most unpredictable.
The results for ICL suggest that continuing to train models like Mistral-7b or Llama-2-13b on more Polish text data could be helpful, as models like Bielik-7b and Trurl-13b showed improved performance. To make it easier for others to experiment with few-shot learning for Polish, the researchers are also releasing some custom templates for ICL.
Technical Explanation
The researchers conducted an empirical comparison of several few-shot learning techniques on a new benchmark consisting of 7 different classification tasks in the Polish language. The techniques they evaluated include:
- Fine-tuning: Updating the parameters of a pre-trained model on the task-specific data.
- Linear probing: Freezing the pre-trained model and only training a linear classifier on top of the frozen features.
- SetFit: A few-shot learning approach that learns task-specific representations.
- In-context learning (ICL): Prompting the pre-trained model to perform the task directly, without any fine-tuning.
They tested these techniques using various commercial and open-source pre-trained language models, including GPT-3.5, GPT-4, HerBERT-large, Mistral-7b, Llama-2-13b, Bielik-7b, and Trurl-13b.
The results show that ICL achieves the best overall performance, with commercial models like GPT-3.5 and GPT-4 attaining the highest scores. However, there remains a significant 14 percentage point gap between the best few-shot learning score and the performance of the HerBERT-large model fine-tuned on the entire training dataset.
Among the other techniques, SetFit emerges as the second-best approach, closely followed by linear probing. The researchers observed the worst and most unstable performance with non-linear head fine-tuning.
The findings for ICL indicate that continual pre-training of models like Mistral-7b or Llama-2-13b on Polish corpora is beneficial, as evidenced by the improved performances of Bielik-7b and Trurl-13b, respectively.
Critical Analysis
The researchers acknowledge that there is still a significant gap between the best few-shot learning performance and the fully supervised fine-tuning approach, suggesting that more research is needed to further improve few-shot learning for the Polish language.
While the results for ICL are promising, the researchers do not provide details on the specific templates or prompting techniques used, which could limit the reproducibility and extensibility of their findings. Additionally, the paper does not discuss potential biases or limitations in the benchmark tasks themselves, which could affect the generalizability of the results.
Furthermore, the paper does not explore the potential trade-offs between performance and computational efficiency, which could be an important consideration for real-world deployment of these techniques. It would be valuable to see an analysis of the runtime and resource requirements of the different approaches.
Overall, the research presents a valuable contribution to the field of few-shot learning for under-resourced languages like Polish. However, further work is needed to address the limitations and build upon the insights gained from this study.
Conclusion
This research introduces a new few-shot learning benchmark for the Polish language and provides an empirical comparison of several techniques, including fine-tuning, linear probing, SetFit, and in-context learning. The key findings indicate that in-context learning (ICL) achieves the best performance, with commercial models like GPT-3.5 and GPT-4 outperforming other approaches.
However, a significant gap remains between the best few-shot learning score and the performance of a fully supervised model. The researchers also observe that continual pre-training of models on Polish corpora can improve few-shot learning capabilities, as evidenced by the enhanced performances of Bielik-7b and Trurl-13b.
This research highlights the potential of few-shot learning techniques for under-resourced languages and provides a valuable benchmark for further advancements in this area. The release of handcrafted templates for ICL will also help support future experiments and progress in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
0
0
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
5/24/2024
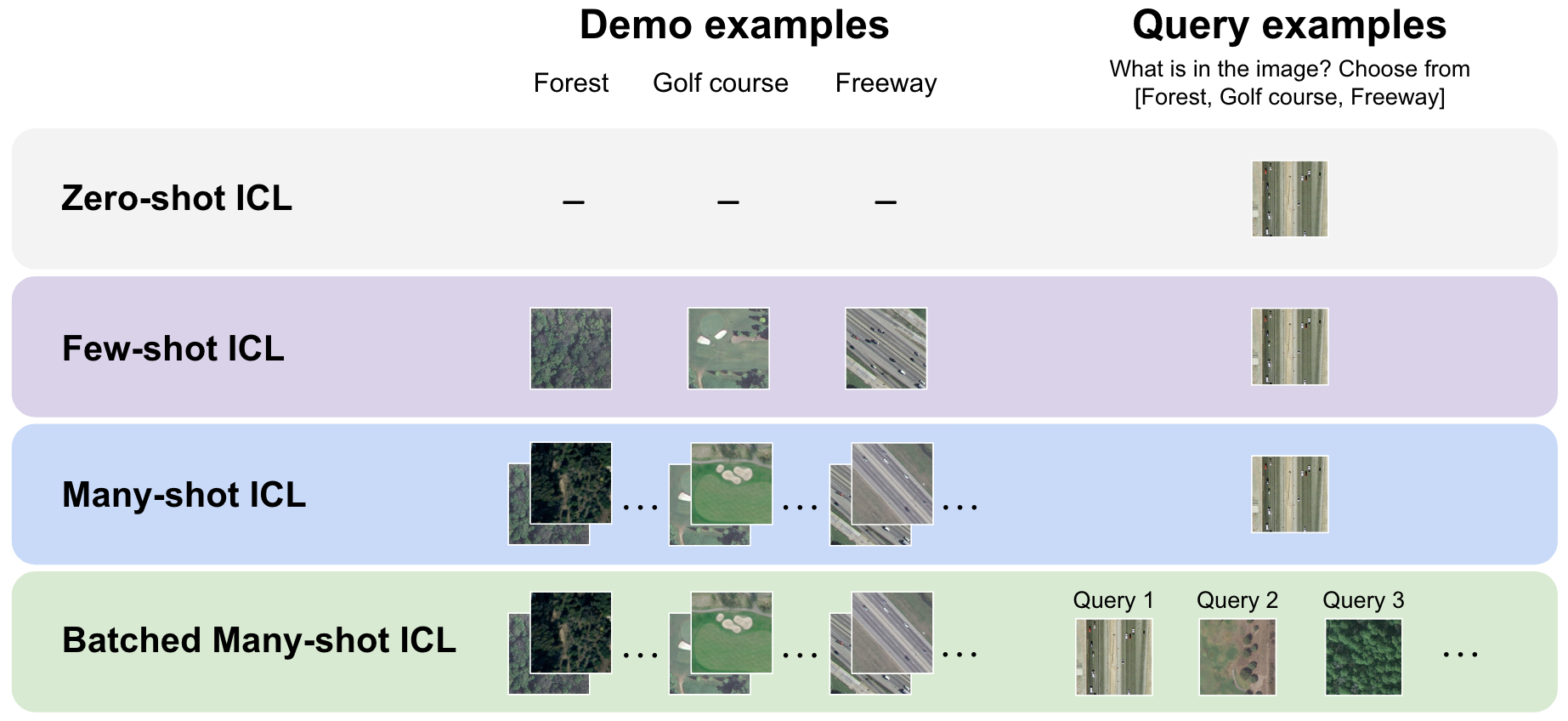
Many-Shot In-Context Learning in Multimodal Foundation Models
Yixing Jiang, Jeremy Irvin, Ji Hun Wang, Muhammad Ahmed Chaudhry, Jonathan H. Chen, Andrew Y. Ng
0
0
Large language models are well-known to be effective at few-shot in-context learning (ICL). Recent advancements in multimodal foundation models have enabled unprecedentedly long context windows, presenting an opportunity to explore their capability to perform ICL with many more demonstrating examples. In this work, we evaluate the performance of multimodal foundation models scaling from few-shot to many-shot ICL. We benchmark GPT-4o and Gemini 1.5 Pro across 10 datasets spanning multiple domains (natural imagery, medical imagery, remote sensing, and molecular imagery) and tasks (multi-class, multi-label, and fine-grained classification). We observe that many-shot ICL, including up to almost 2,000 multimodal demonstrating examples, leads to substantial improvements compared to few-shot (<100 examples) ICL across all of the datasets. Further, Gemini 1.5 Pro performance continues to improve log-linearly up to the maximum number of tested examples on many datasets. Given the high inference costs associated with the long prompts required for many-shot ICL, we also explore the impact of batching multiple queries in a single API call. We show that batching up to 50 queries can lead to performance improvements under zero-shot and many-shot ICL, with substantial gains in the zero-shot setting on multiple datasets, while drastically reducing per-query cost and latency. Finally, we measure ICL data efficiency of the models, or the rate at which the models learn from more demonstrating examples. We find that while GPT-4o and Gemini 1.5 Pro achieve similar zero-shot performance across the datasets, Gemini 1.5 Pro exhibits higher ICL data efficiency than GPT-4o on most datasets. Our results suggest that many-shot ICL could enable users to efficiently adapt multimodal foundation models to new applications and domains. Our codebase is publicly available at https://github.com/stanfordmlgroup/ManyICL .
5/17/2024
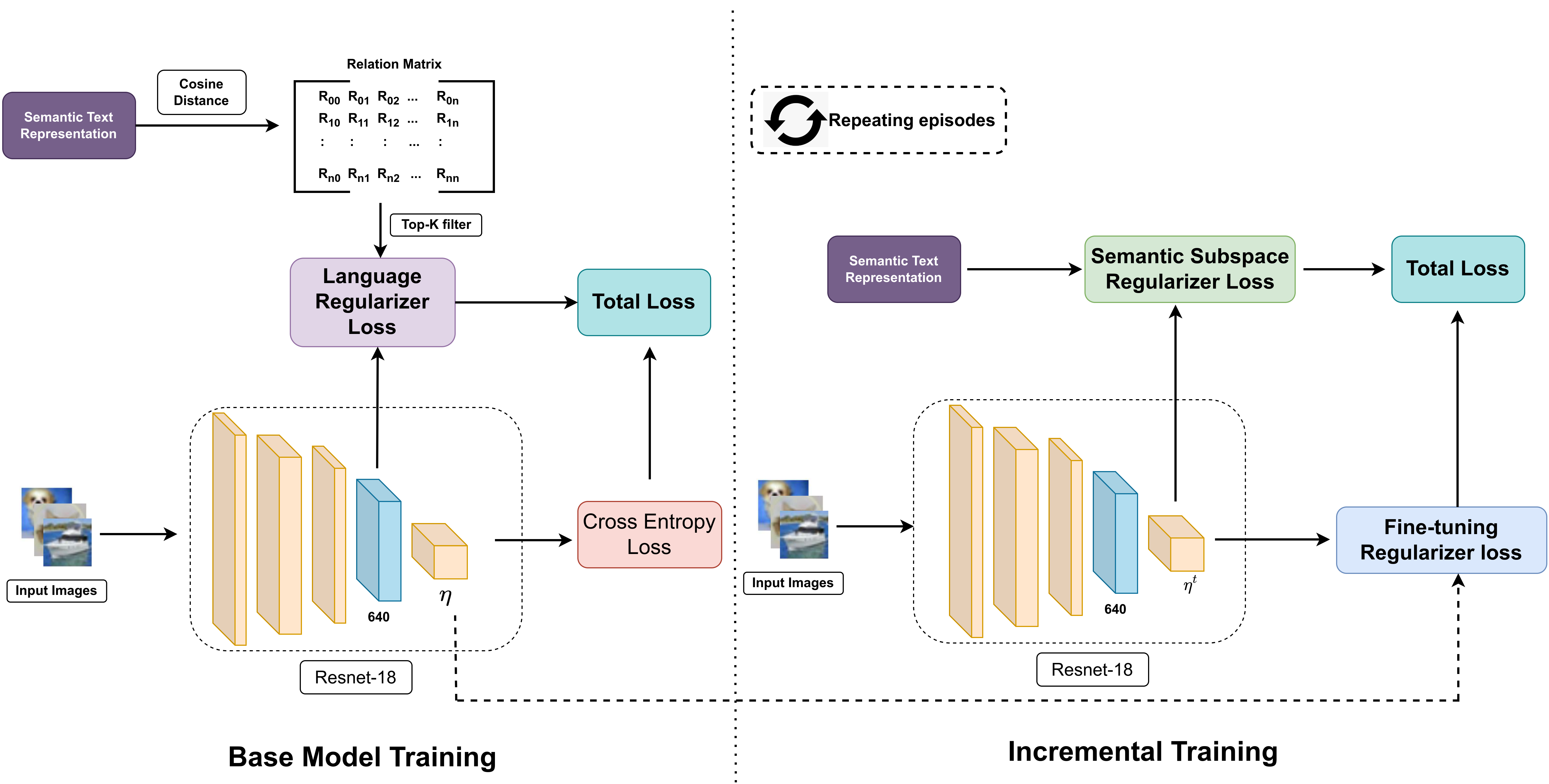
Few Shot Class Incremental Learning using Vision-Language models
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
0
0
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
5/3/2024
💬
A Zero-shot and Few-shot Study of Instruction-Finetuned Large Language Models Applied to Clinical and Biomedical Tasks
Yanis Labrak, Mickael Rouvier, Richard Dufour
0
0
We evaluate four state-of-the-art instruction-tuned large language models (LLMs) -- ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca -- on a set of 13 real-world clinical and biomedical natural language processing (NLP) tasks in English, such as named-entity recognition (NER), question-answering (QA), relation extraction (RE), etc. Our overall results demonstrate that the evaluated LLMs begin to approach performance of state-of-the-art models in zero- and few-shot scenarios for most tasks, and particularly well for the QA task, even though they have never seen examples from these tasks before. However, we observed that the classification and RE tasks perform below what can be achieved with a specifically trained model for the medical field, such as PubMedBERT. Finally, we noted that no LLM outperforms all the others on all the studied tasks, with some models being better suited for certain tasks than others.
6/11/2024