Map-based Modular Approach for Zero-shot Embodied Question Answering
2405.16559
0
0
🧠
Abstract
Building robots capable of interacting with humans through natural language in the visual world presents a significant challenge in the field of robotics. To overcome this challenge, Embodied Question Answering (EQA) has been proposed as a benchmark task to measure the ability to identify an object navigating through a previously unseen environment in response to human-posed questions. Although some methods have been proposed, their evaluations have been limited to simulations, without experiments in real-world scenarios. Furthermore, all of these methods are constrained by a limited vocabulary for question-and-answer interactions, making them unsuitable for practical applications. In this work, we propose a map-based modular EQA method that enables real robots to navigate unknown environments through frontier-based map creation and address unknown QA pairs using foundation models that support open vocabulary. Unlike the questions of the previous EQA dataset on Matterport 3D (MP3D), questions in our real-world experiments contain various question formats and vocabularies not included in the training data. We conduct comprehensive experiments on virtual environments (MP3D-EQA) and two real-world house environments and demonstrate that our method can perform EQA even in the real world.
Create account to get full access
Overview
- This paper proposes a "map-based modular approach" for zero-shot embodied question answering (EQA) tasks.
- The approach involves breaking down the EQA problem into smaller, modular sub-tasks that can be solved independently.
- The system uses a spatial map of the environment to reason about the locations and relationships of objects, which helps it answer questions without needing prior experience in the environment.
Plain English Explanation
The researchers have developed a new way for AI agents to answer questions about their surroundings, even if they've never been in that environment before. Instead of trying to learn everything about a new environment all at once, their system breaks the problem down into smaller, more manageable pieces.
The key idea is to create a "map" of the environment that shows where different objects are located and how they are related to each other. The agent can then use this map to reason about the answers to questions, without needing prior experience. For example, if asked "What is on the table?", the agent can consult its map to determine the objects located on the table, and provide the answer.
This modular, map-based approach allows the agent to tackle complex, situational questions about its surroundings, rather than just simple lookup tasks. It also enables the agent to explore and describe the environment more effectively, which can be useful for visual question answering and video understanding tasks.
Technical Explanation
The paper's key innovation is the "map-based modular approach" for zero-shot embodied question answering (EQA). The system breaks down the EQA task into several sub-tasks, each of which can be solved independently:
- Spatial Mapping: The agent constructs a spatial map of the environment, representing the locations and relationships of objects.
- Object Detection: The agent identifies and classifies the objects present in the environment.
- Question Answering: The agent uses the spatial map and object information to reason about and answer questions about the environment.
The spatial map is a crucial component, as it allows the agent to reason about the environment without needing prior experience. The map represents the locations of objects and their spatial relationships, enabling the agent to answer questions by consulting the map rather than relying on memorized knowledge.
The authors evaluate their approach on the EQA-v1 dataset, where the agent is placed in a new environment and must answer questions about it. The results show that the map-based modular approach outperforms previous state-of-the-art methods, particularly on questions that require reasoning about object locations and relationships.
Critical Analysis
The paper presents a novel and promising approach to the challenging problem of zero-shot embodied question answering. The modular, map-based design is a clever way to break down a complex task into more manageable sub-problems, which can help improve the agent's reasoning capabilities.
However, the authors acknowledge some limitations of their approach. For example, the spatial mapping module may not be able to accurately represent more complex or dynamic environments, which could impact the agent's performance. Additionally, the reliance on object detection could be a potential bottleneck if the agent's object recognition capabilities are not sufficiently robust.
Furthermore, the experiments in the paper were conducted in relatively simple, static environments. It would be interesting to see how the map-based modular approach performs in more realistic, cluttered, and changing environments, which may require additional capabilities like scene understanding and temporal reasoning.
Overall, the map-based modular approach is a promising step towards more capable and flexible embodied AI systems, but further research is needed to address the potential limitations and expand the approach to more complex real-world scenarios.
Conclusion
This paper presents a novel "map-based modular approach" for zero-shot embodied question answering, which breaks down the problem into smaller, more manageable sub-tasks. The key idea is to construct a spatial map of the environment that represents the locations and relationships of objects, enabling the agent to reason about the answers to questions without needing prior experience in the environment.
The modular design and the use of a spatial map are innovative approaches that allow the agent to tackle complex, situational questions and explore and describe the environment more effectively, which can be useful for visual question answering and video understanding tasks.
While the paper presents promising results, there are still some limitations that need to be addressed, such as the ability to handle more complex and dynamic environments. Further research in this direction could lead to more capable and flexible embodied AI agents that can better navigate and understand the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Explore until Confident: Efficient Exploration for Embodied Question Answering
Allen Z. Ren, Jaden Clark, Anushri Dixit, Masha Itkina, Anirudha Majumdar, Dorsa Sadigh
0
0
We consider the problem of Embodied Question Answering (EQA), which refers to settings where an embodied agent such as a robot needs to actively explore an environment to gather information until it is confident about the answer to a question. In this work, we leverage the strong semantic reasoning capabilities of large vision-language models (VLMs) to efficiently explore and answer such questions. However, there are two main challenges when using VLMs in EQA: they do not have an internal memory for mapping the scene to be able to plan how to explore over time, and their confidence can be miscalibrated and can cause the robot to prematurely stop exploration or over-explore. We propose a method that first builds a semantic map of the scene based on depth information and via visual prompting of a VLM - leveraging its vast knowledge of relevant regions of the scene for exploration. Next, we use conformal prediction to calibrate the VLM's question answering confidence, allowing the robot to know when to stop exploration - leading to a more calibrated and efficient exploration strategy. To test our framework in simulation, we also contribute a new EQA dataset with diverse, realistic human-robot scenarios and scenes built upon the Habitat-Matterport 3D Research Dataset (HM3D). Both simulated and real robot experiments show our proposed approach improves the performance and efficiency over baselines that do no leverage VLM for exploration or do not calibrate its confidence. Webpage with experiment videos and code: https://explore-eqa.github.io/
5/28/2024

Embodied Question Answering via Multi-LLM Systems
Bhrij Patel, Vishnu Sashank Dorbala, Dinesh Manocha, Amrit Singh Bedi
0
0
Embodied Question Answering (EQA) is an important problem, which involves an agent exploring the environment to answer user queries. In the existing literature, EQA has exclusively been studied in single-agent scenarios, where exploration can be time-consuming and costly. In this work, we consider EQA in a multi-agent framework involving multiple large language models (LLM) based agents independently answering queries about a household environment. To generate one answer for each query, we use the individual responses to train a Central Answer Model (CAM) that aggregates responses for a robust answer. Using CAM, we observe a $50%$ higher EQA accuracy when compared against aggregation methods for ensemble LLM, such as voting schemes and debates. CAM does not require any form of agent communication, alleviating it from the associated costs. We ablate CAM with various nonlinear (neural network, random forest, decision tree, XGBoost) and linear (logistic regression classifier, SVM) algorithms. Finally, we present a feature importance analysis for CAM via permutation feature importance (PFI), quantifying CAMs reliance on each independent agent and query context.
6/19/2024
🏅
S-EQA: Tackling Situational Queries in Embodied Question Answering
Vishnu Sashank Dorbala, Prasoon Goyal, Robinson Piramuthu, Michael Johnston, Dinesh Manocha, Reza Ghanadhan
0
0
We present and tackle the problem of Embodied Question Answering (EQA) with Situational Queries (S-EQA) in a household environment. Unlike prior EQA work tackling simple queries that directly reference target objects and quantifiable properties pertaining them, EQA with situational queries (such as Is the bathroom clean and dry?) is more challenging, as the agent needs to figure out not just what the target objects pertaining to the query are, but also requires a consensus on their states to be answerable. Towards this objective, we first introduce a novel Prompt-Generate-Evaluate (PGE) scheme that wraps around an LLM's output to create a dataset of unique situational queries, corresponding consensus object information, and predicted answers. PGE maintains uniqueness among the generated queries, using multiple forms of semantic similarity. We validate the generated dataset via a large scale user-study conducted on M-Turk, and introduce it as S-EQA, the first dataset tackling EQA with situational queries. Our user study establishes the authenticity of S-EQA with a high 97.26% of the generated queries being deemed answerable, given the consensus object data. Conversely, we observe a low correlation of 46.2% on the LLM-predicted answers to human-evaluated ones; indicating the LLM's poor capability in directly answering situational queries, while establishing S-EQA's usability in providing a human-validated consensus for an indirect solution. We evaluate S-EQA via Visual Question Answering (VQA) on VirtualHome, which unlike other simulators, contains several objects with modifiable states that also visually appear different upon modification -- enabling us to set a quantitative benchmark for S-EQA. To the best of our knowledge, this is the first work to introduce EQA with situational queries, and also the first to use a generative approach for query creation.
5/9/2024
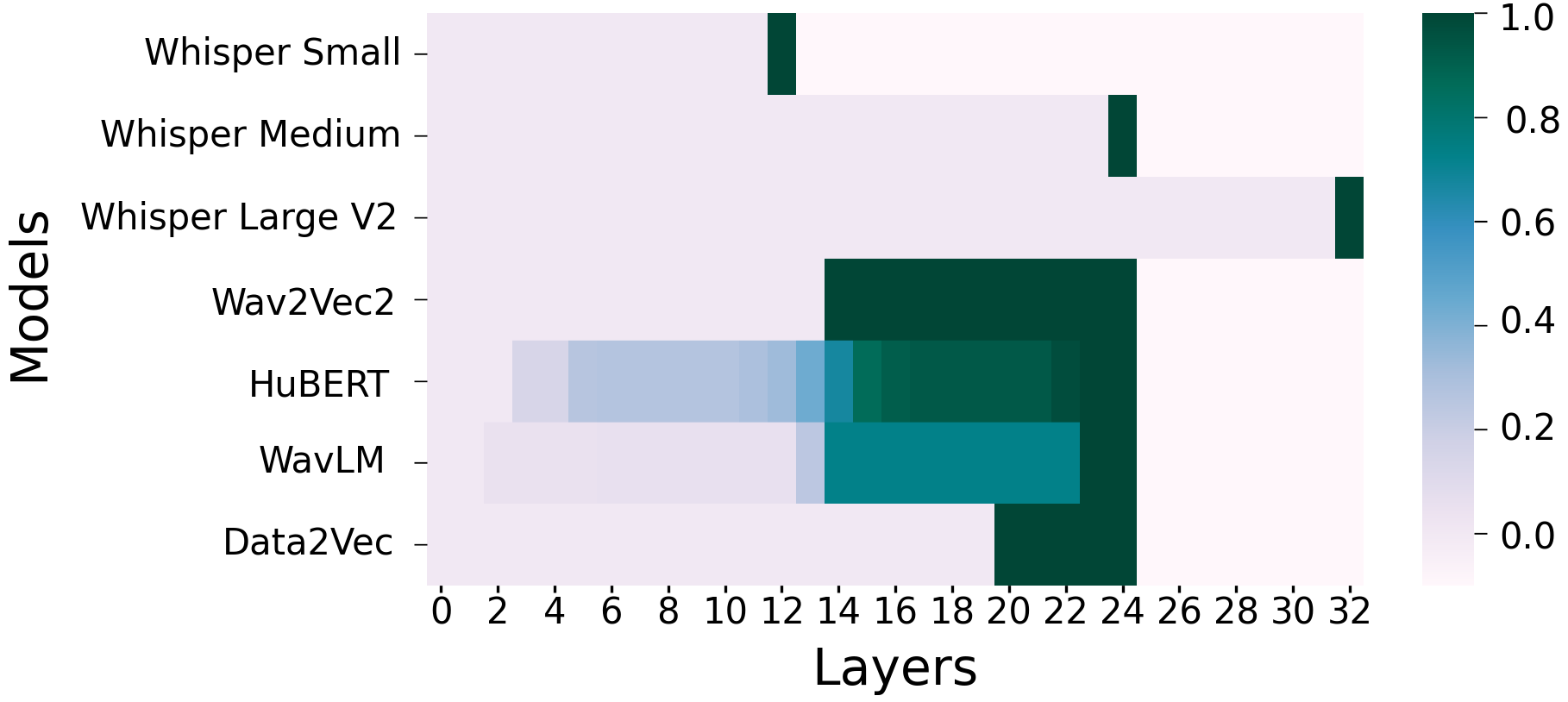
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Yanis Labrak, Adel Moumen, Richard Dufour, Mickael Rouvier
0
0
In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
6/11/2024