Embodied AI with Two Arms: Zero-shot Learning, Safety and Modularity
2404.03570
0
0
Abstract
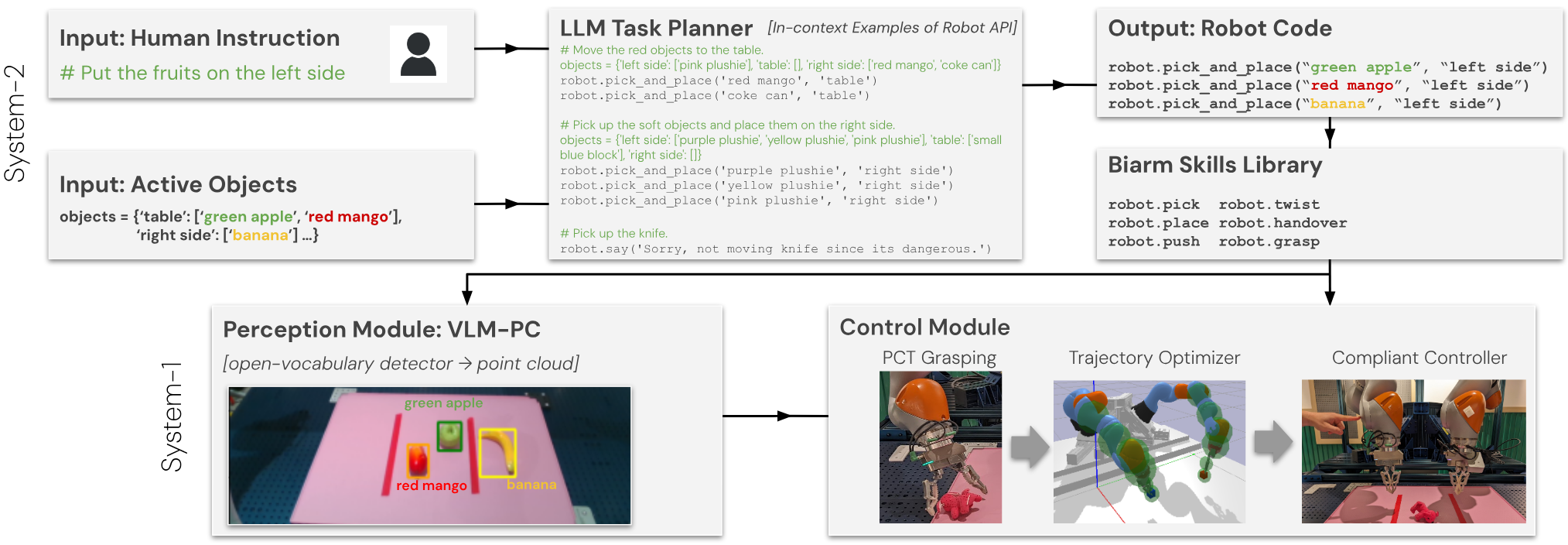
We present an embodied AI system which receives open-ended natural language instructions from a human, and controls two arms to collaboratively accomplish potentially long-horizon tasks over a large workspace. Our system is modular: it deploys state of the art Large Language Models for task planning,Vision-Language models for semantic perception, and Point Cloud transformers for grasping. With semantic and physical safety in mind, these modules are interfaced with a real-time trajectory optimizer and a compliant tracking controller to enable human-robot proximity. We demonstrate performance for the following tasks: bi-arm sorting, bottle opening, and trash disposal tasks. These are done zero-shot where the models used have not been trained with any real world data from this bi-arm robot, scenes or workspace.Composing both learning- and non-learning-based components in a modular fashion with interpretable inputs and outputs allows the user to easily debug points of failures and fragilities. One may also in-place swap modules to improve the robustness of the overall platform, for instance with imitation-learned policies.
Create account to get full access
Overview
- This paper presents a modular, zero-shot, and safe bi-arm system for embodied AI.
- The system combines large language models with robotic arms to enable zero-shot learning, safety, and modularity.
- The authors demonstrate the system's capabilities in various tasks, including object manipulation, tool use, and human-robot interaction.
Plain English Explanation
The researchers have developed a robotic system with two arms that can learn and perform a wide variety of tasks without needing to be explicitly programmed for each one. This is achieved by using large language models, which are AI systems trained on vast amounts of text data to understand and generate human-like language.
By combining these powerful language models with the physical capabilities of the robotic arms, the researchers have created a system that can [object Object]. This means the robot can learn and perform new tasks on the fly, without requiring any additional programming or training. The system is also designed to be safe, with built-in safeguards to prevent the robot from causing harm.
The modular nature of the system allows different components, such as the language model or the robotic arms, to be easily swapped out or upgraded. This makes the system more flexible and adaptable to a wide range of applications, from [object Object] to [object Object].
The researchers demonstrate the system's capabilities through various experiments, showcasing its ability to [object Object] to new tasks and situations, while maintaining a high level of safety and performance.
Technical Explanation
The authors present a modular robotic system with two arms that leverages large language models to enable [object Object]. The system combines a language model with a multi-modal perception system and a bi-arm robot, allowing the robot to understand and execute a wide range of tasks without the need for explicit programming.
The key components of the system include:
-
Language Model: The authors use a large language model, such as GPT-3, to enable the robot to understand and generate human-like language, which is crucial for [object Object] and [object Object].
-
Multi-Modal Perception: The robot is equipped with various sensors, such as cameras and force sensors, to perceive its environment and the objects it interacts with.
-
Bi-Arm Robot: The system uses a robotic platform with two arms, allowing for more complex and dexterous [object Object] and [object Object].
The authors demonstrate the system's capabilities through a series of experiments, showing its ability to [object Object] to new tasks and situations, while maintaining a high level of safety and performance.
Critical Analysis
The paper presents a promising approach to embodied AI, leveraging the strengths of large language models and modular robotic systems. However, there are some potential limitations and areas for further research:
-
Scalability: While the modular design allows for flexibility, the integration and coordination of multiple complex components may present challenges as the system scales to more advanced tasks or diverse environments.
-
Generalization Limits: The authors demonstrate [object Object] capabilities, but the extent of the system's ability to generalize to novel, unseen tasks or environments is not fully explored.
-
Safety Considerations: While the system includes safety mechanisms, the authors do not provide a comprehensive analysis of the system's safety performance, particularly in complex or unpredictable real-world scenarios.
-
Human-Robot Interaction: The paper focuses on the technical aspects of the system, but more research is needed to understand the implications and challenges of [object Object] in practical applications.
Overall, the paper presents an intriguing approach to embodied AI that merits further exploration and refinement to address these potential limitations and unlock the full potential of this technology.
Conclusion
The researchers have developed a modular, zero-shot, and safe bi-arm system that combines large language models with robotic arms to enable a wide range of embodied AI capabilities. By leveraging the understanding and versatility of language models, the system can learn and perform new tasks without explicit programming, while maintaining a high level of safety and performance.
This work represents an important step towards more flexible and adaptable embodied AI systems, with potential applications in areas such as [object Object], [object Object], and [object Object]. As the researchers continue to refine and expand the system, it could lead to significant advancements in the field of embodied AI, with implications for a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards a Robust Soft Baby Robot With Rich Interaction Ability for Advanced Machine Learning Algorithms
Mohannad Alhakami, Dylan R. Ashley, Joel Dunham, Francesco Faccio, Eric Feron, Jurgen Schmidhuber
0
0
Artificial intelligence has made great strides in many areas lately, yet it has had comparatively little success in general-use robotics. We believe one of the reasons for this is the disconnect between traditional robotic design and the properties needed for open-ended, creativity-based AI systems. To that end, we, taking selective inspiration from nature, build a robust, partially soft robotic limb with a large action space, rich sensory data stream from multiple cameras, and the ability to connect with others to enhance the action space and data stream. As a proof of concept, we train two contemporary machine learning algorithms to perform a simple target-finding task. Altogether, we believe that this design serves as a first step to building a robot tailor-made for achieving artificial general intelligence.
4/15/2024

Language-Driven Closed-Loop Grasping with Model-Predictive Trajectory Replanning
Huy Hoang Nguyen, Minh Nhat Vu, Florian Beck, Gerald Ebmer, Anh Nguyen, Andreas Kugi
0
0
Combining a vision module inside a closed-loop control system for a emph{seamless movement} of a robot in a manipulation task is challenging due to the inconsistent update rates between utilized modules. This task is even more difficult in a dynamic environment, e.g., objects are moving. This paper presents a emph{modular} zero-shot framework for language-driven manipulation of (dynamic) objects through a closed-loop control system with real-time trajectory replanning and an online 6D object pose localization. We segment an object within $SI{0.5}{second}$ by leveraging a vision language model via language commands. Then, guided by natural language commands, a closed-loop system, including a unified pose estimation and tracking and online trajectory planning, is utilized to continuously track this object and compute the optimal trajectory in real-time. Our proposed zero-shot framework provides a smooth trajectory that avoids jerky movements and ensures the robot can grasp a non-stationary object. Experiment results exhibit the real-time capability of the proposed zero-shot modular framework for the trajectory optimization module to accurately and efficiently grasp moving objects, i.e., up to SI{30}{hertz} update rates for the online 6D pose localization module and SI{10}{hertz} update rates for the receding-horizon trajectory optimization. These advantages highlight the modular framework's potential applications in robotics and human-robot interaction; see the video in https://www.acin.tuwien.ac.at/en/6e64/.
6/21/2024
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024
🧠
Map-based Modular Approach for Zero-shot Embodied Question Answering
Koya Sakamoto, Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, Motoaki Kawanabe
0
0
Building robots capable of interacting with humans through natural language in the visual world presents a significant challenge in the field of robotics. To overcome this challenge, Embodied Question Answering (EQA) has been proposed as a benchmark task to measure the ability to identify an object navigating through a previously unseen environment in response to human-posed questions. Although some methods have been proposed, their evaluations have been limited to simulations, without experiments in real-world scenarios. Furthermore, all of these methods are constrained by a limited vocabulary for question-and-answer interactions, making them unsuitable for practical applications. In this work, we propose a map-based modular EQA method that enables real robots to navigate unknown environments through frontier-based map creation and address unknown QA pairs using foundation models that support open vocabulary. Unlike the questions of the previous EQA dataset on Matterport 3D (MP3D), questions in our real-world experiments contain various question formats and vocabularies not included in the training data. We conduct comprehensive experiments on virtual environments (MP3D-EQA) and two real-world house environments and demonstrate that our method can perform EQA even in the real world.
5/28/2024