MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
2405.19327
0
0
Abstract
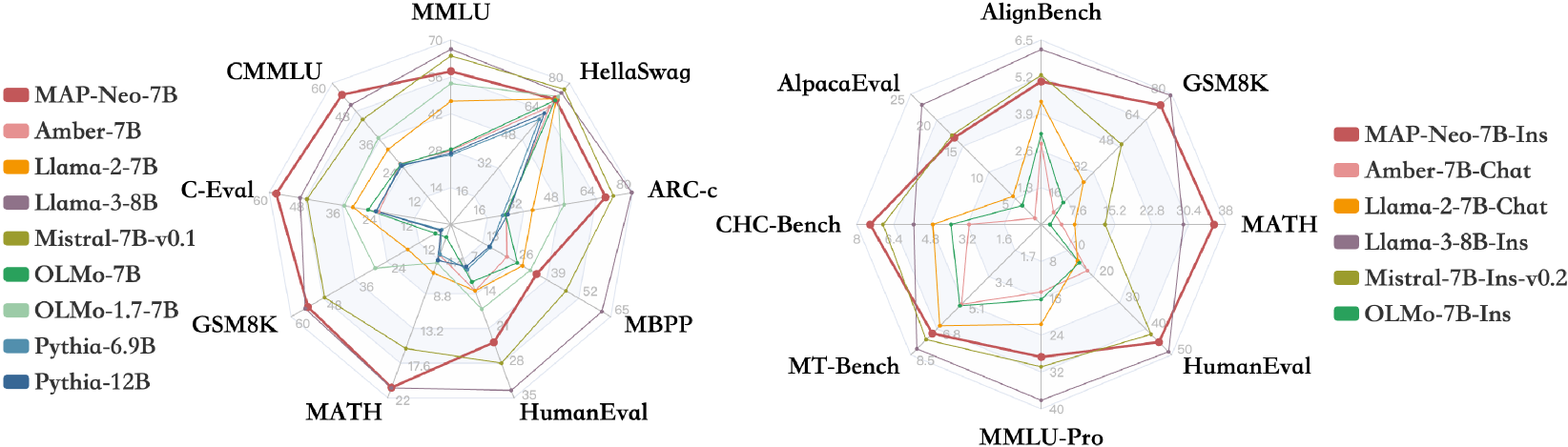
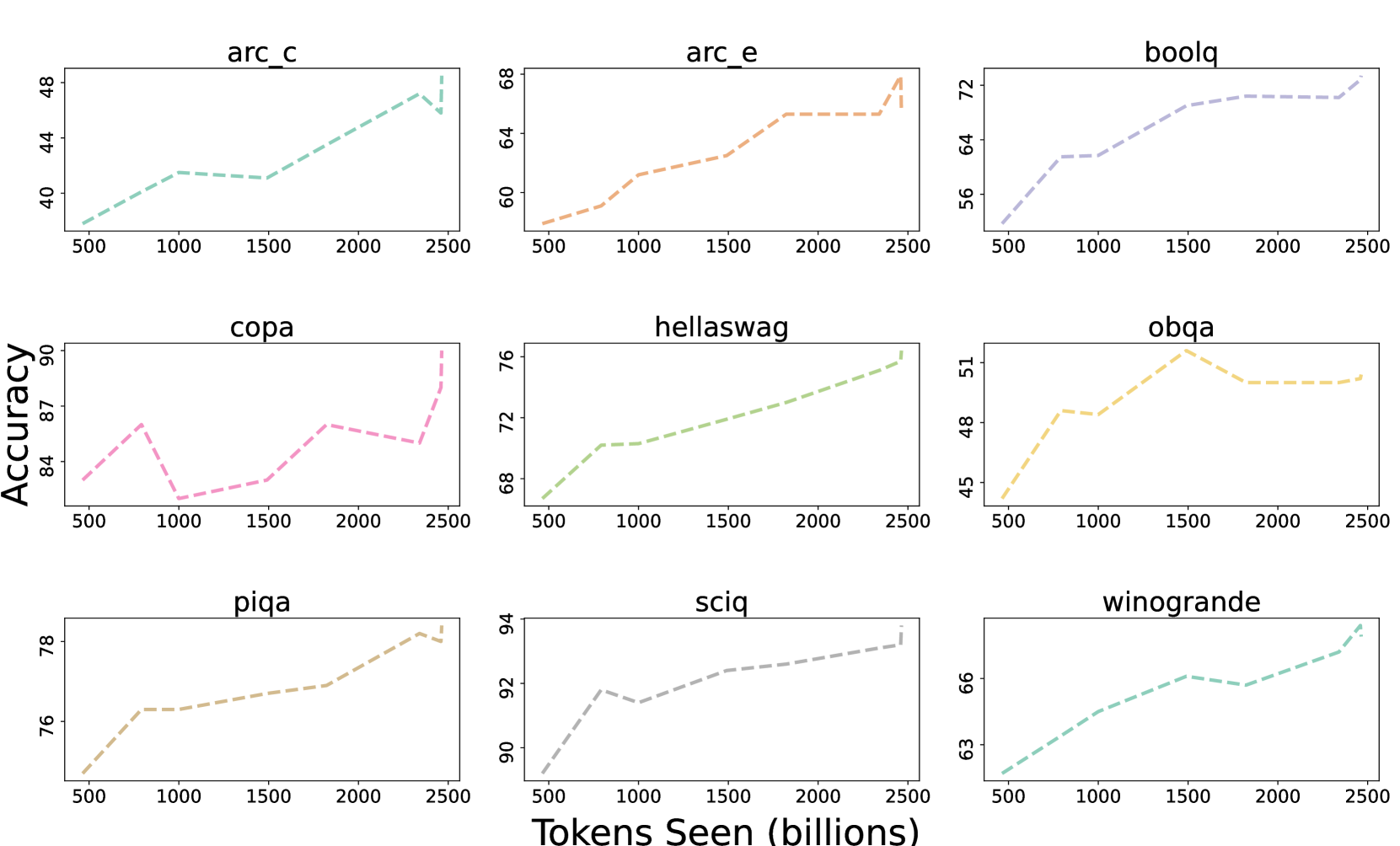
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
Create account to get full access
Overview
- Introduces a new series of highly capable and transparent bilingual large language models called MAP-Neo
- Focuses on improving the performance and interpretability of these models across multiple languages
- Includes a technical explanation of the model architecture, training process, and key insights from the research
Plain English Explanation
The MAP-Neo series is a new set of large language models that can understand and generate text in multiple languages, like English and Mandarin Chinese. These models are designed to be highly capable, meaning they can perform a wide range of tasks very well, and also transparent, meaning it's easier to understand how they work and make decisions.
One of the main goals of this research is to improve the performance and interpretability of these bilingual models, making them more useful and trustworthy for real-world applications. The researchers explore different model architectures and training techniques to achieve this, drawing on insights from related work in the field of natural language processing.
The paper provides a detailed technical explanation of the MAP-Neo models, including how they are structured and how they are trained. It also highlights some of the key insights and findings from the researchers' experiments, which focus on areas like multilingual understanding, generation, and knowledge transfer.
Overall, the MAP-Neo series represents an important step forward in the development of large language models that can operate effectively in multiple languages, with a focus on improving both their capabilities and their transparency.
Technical Explanation
The MAP-Neo models are built using a novel architecture that combines elements of transformer-based language models, such as BERT and GPT, with specialized modules for multilingual processing.
The core of the model is a shared encoder-decoder structure that can handle input and output in multiple languages. This is combined with language-specific adapters that allow the model to better capture the unique characteristics of each language. The researchers also explore different techniques for initializing and fine-tuning the models to further improve their multilingual capabilities.
In terms of the training process, the MAP-Neo models are pre-trained on large corpora of text data in multiple languages, including both monolingual and bilingual sources. This allows the models to develop a strong foundation of linguistic knowledge that can be leveraged for a variety of downstream tasks.
The researchers conduct extensive experiments to evaluate the performance of the MAP-Neo models on a range of benchmarks, including tasks like machine translation, natural language inference, and named entity recognition. The results demonstrate significant improvements over previous multilingual language models, particularly in terms of cross-lingual transfer and interpretability.
Critical Analysis
The MAP-Neo paper presents a comprehensive and well-designed approach to developing highly capable and transparent bilingual language models. The researchers have clearly put a lot of thought into the model architecture and training process, and their experimental results are impressive.
That said, the paper does acknowledge some limitations and areas for further research. For example, the models are currently limited to just two languages (English and Mandarin Chinese), and it's unclear how well the approach would scale to larger numbers of languages. The researchers also note that the models' interpretability could be further improved, particularly when it comes to understanding the reasoning behind their decisions.
Additionally, while the paper discusses the potential benefits of the MAP-Neo models in terms of real-world applications, it doesn't go into much detail on potential societal impacts or ethical considerations. As these models become more advanced and widely deployed, it will be important to carefully consider issues like bias, fairness, and privacy.
Overall, the MAP-Neo research represents an important contribution to the field of multilingual natural language processing. However, there is still work to be done to fully realize the potential of these models and address the challenges that come with deploying them in the real world.
Conclusion
The MAP-Neo series of bilingual large language models represents a significant step forward in the development of highly capable and transparent natural language processing systems. By combining advanced model architectures with specialized techniques for multilingual processing, the researchers have demonstrated impressive performance on a range of benchmarks, particularly in terms of cross-lingual transfer and interpretability.
As these models continue to be refined and scaled, they have the potential to enable a wide range of practical applications, from improved machine translation and multilingual content generation to more advanced language-based AI assistants. However, it will be important to carefully consider the ethical and societal implications of these technologies as they become more widely adopted.
Overall, the MAP-Neo research represents an important contribution to the field of natural language processing, and a promising direction for the continued development of powerful and transparent language models that can operate effectively across multiple languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GEB-1.3B: Open Lightweight Large Language Model
Jie Wu, Yufeng Zhu, Lei Shen, Xuqing Lu
0
0
Recently developed large language models (LLMs) such as ChatGPT, Claude, and Llama have demonstrated impressive abilities, and even surpass human-level performance in several tasks. Despite their success, the resource-intensive demands of these models, requiring significant computational power for both training and inference, limit their deployment to high-performance servers. Additionally, the extensive calculation requirements of the models often lead to increased latency in response times. With the increasing need for LLMs to operate efficiently on CPUs, research about lightweight models that are optimized for CPU inference has emerged. In this work, we introduce GEB-1.3B, a lightweight LLM trained on 550 billion tokens in both Chinese and English languages. We employ novel training techniques, including ROPE, Group-Query-Attention, and FlashAttention-2, to accelerate training while maintaining model performance. Additionally, we fine-tune the model using 10 million samples of instruction data to enhance alignment. GEB-1.3B exhibits outstanding performance on general benchmarks such as MMLU, C-Eval, and CMMLU, outperforming comparative models such as MindLLM-1.3B and TinyLLaMA-1.1B. Notably, the FP32 version of GEB-1.3B achieves commendable inference times on CPUs, with ongoing efforts to further enhance speed through advanced quantization techniques. The release of GEB-1.3B as an open-source model marks a significant contribution to the development of lightweight LLMs, promising to foster further research and innovation in the field.
6/17/2024

GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024
OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi
0
0
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, we have built OLMo, a competitive, truly Open Language Model, to enable the scientific study of language models. Unlike most prior efforts that have only released model weights and inference code, we release OLMo alongside open training data and training and evaluation code. We hope this release will empower the open research community and inspire a new wave of innovation.
6/11/2024
🐍
Tele-FLM Technical Report
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, Tiejun Huang
0
0
Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
4/26/2024