How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
2404.16821
0
0
💬
Abstract
In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces InternVL 1.5, an open-source multimodal large language model (MLLM) that aims to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding.
- The model includes three key improvements: a stronger vision encoder, dynamic high-resolution support, and a high-quality bilingual dataset.
- InternVL 1.5 is evaluated on a series of benchmarks, outperforming both open-source and proprietary models in 8 out of 18 tasks.
Plain English Explanation
The researchers have developed a new open-source multimodal language model called InternVL 1.5 that can understand and process both text and images. This model aims to provide capabilities similar to expensive commercial models, but in an open-source format that is freely available.
To improve the model's performance, the researchers made three key changes:
- Stronger Vision Encoder: They enhanced the model's ability to understand visual information by improving the underlying vision-based machine learning component.
- Dynamic High-Resolution: The model can now handle high-quality, high-resolution images, up to 4K resolution, by intelligently dividing the images into smaller tiles.
- High-Quality Bilingual Dataset: The researchers created a new multilingual dataset with English and Chinese question-answer pairs, covering common scenes and document images. This helps the model perform better on tasks involving text in multiple languages, such as optical character recognition (OCR) and Chinese-related tasks.
When evaluated on a range of benchmark tests, InternVL 1.5 showed competitive performance compared to both open-source and proprietary models, achieving the best results in 8 out of 18 tasks.
Technical Explanation
The researchers introduced three key improvements to the InternVL model:
- Strong Vision Encoder: They explored a continuous learning strategy for the large-scale vision foundation model, InternViT-6B, to boost its visual understanding capabilities. This makes the vision encoder more transferable and reusable in different large language models (LLMs).
- Dynamic High-Resolution: The model can divide images into tiles ranging from 1 to 40 of 448x448 pixels, depending on the aspect ratio and resolution of the input images. This supports up to 4K resolution input, enabling the model to handle high-quality visual data.
- High-Quality Bilingual Dataset: The researchers carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs. This significantly enhances the model's performance on OCR- and Chinese-related tasks.
The researchers evaluated InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 showed competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks.
Critical Analysis
While the improvements made to InternVL 1.5 are significant, the paper does not address some potential limitations or areas for further research:
- The performance comparison with proprietary models is limited, as the paper only provides high-level results without detailed analysis. More in-depth comparisons could help better understand the model's strengths and weaknesses.
- The scope of the bilingual dataset is not clearly defined, and it is unclear how representative it is of real-world multimodal data. Expanding the dataset's diversity and complexity could further enhance the model's capabilities.
- The specific use cases where InternVL 1.5 excels or falls short are not discussed in detail. Contextual analysis of the model's performance on different types of tasks or domains would provide more insights.
Overall, the research presents promising advancements in open-source multimodal language models, but further investigation and transparency could strengthen the conclusions and implications of this work.
Conclusion
The researchers have introduced InternVL 1.5, an open-source multimodal language model that aims to bridge the capability gap between open-source and proprietary commercial models. By incorporating a stronger vision encoder, dynamic high-resolution support, and a high-quality bilingual dataset, the model has achieved competitive performance on a range of benchmarks, outperforming both open-source and proprietary models in several tasks.
This research represents a significant step forward in the development of accessible and capable multimodal language models, which can have far-reaching implications for various applications, such as natural language processing, video understanding, and multimodal fusion. By expanding the capabilities of open-source models, the researchers are contributing to the democratization of advanced AI technologies and paving the way for more inclusive and accessible multimodal AI applications.
Related Papers
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, Lichao Sun
0
0
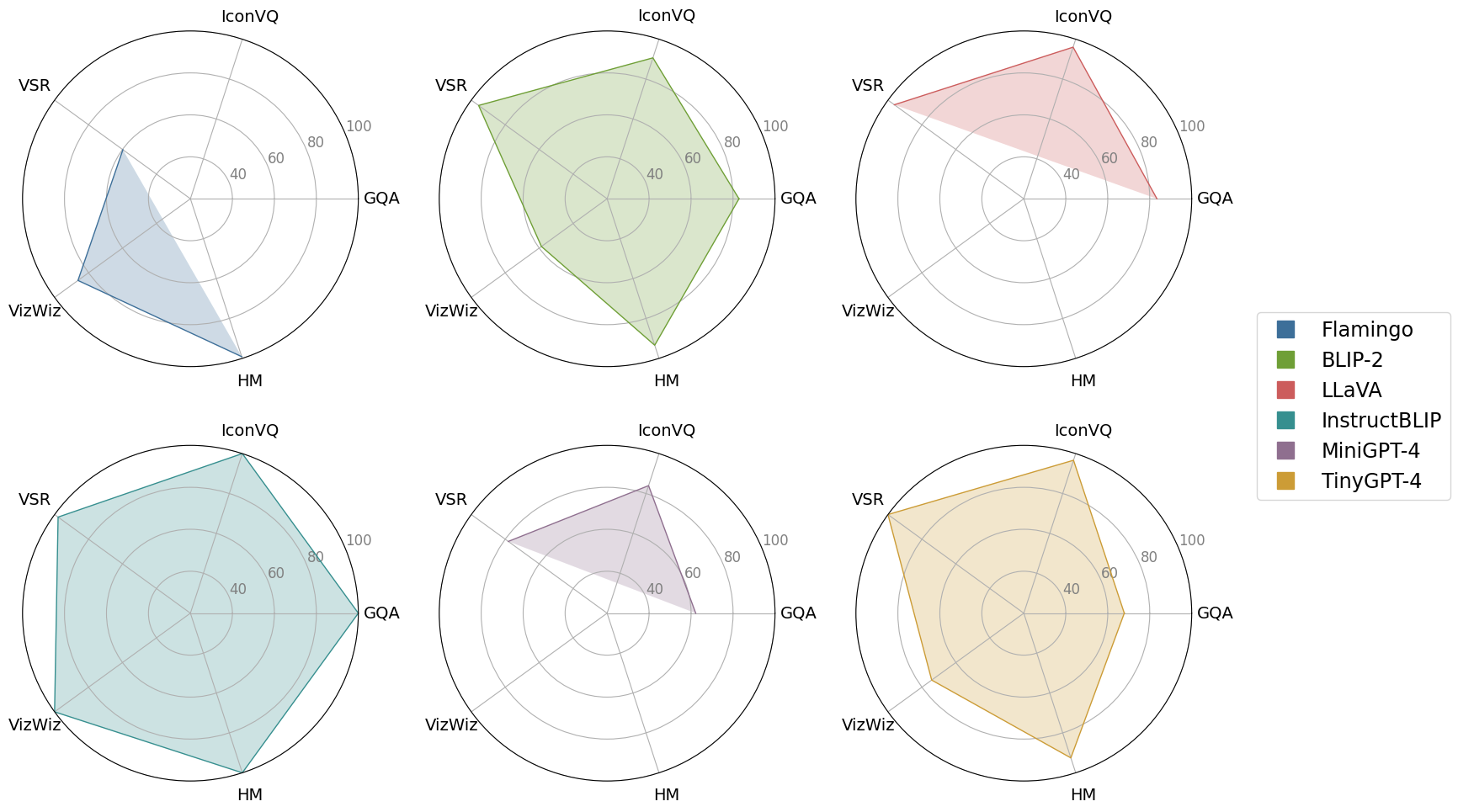
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in url{https://github.com/DLYuanGod/TinyGPT-V}.
4/8/2024

InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Songyang Zhang, Haodong Duan, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Zhe Chen, Xinyue Zhang, Wei Li, Jingwen Li, Wenhai Wang, Kai Chen, Conghui He, Xingcheng Zhang, Jifeng Dai, Yu Qiao, Dahua Lin, Jiaqi Wang
0
0
The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
4/10/2024
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
0
0
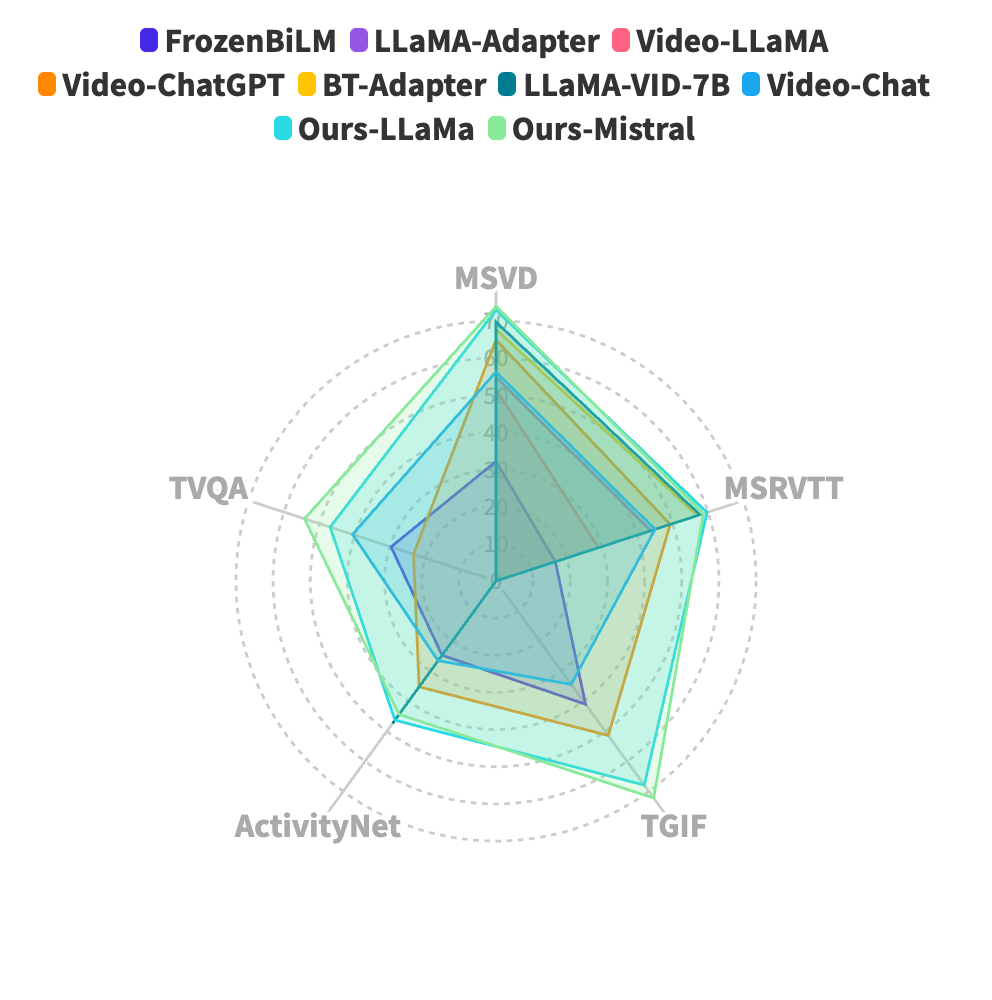
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
4/5/2024
OmniFusion Technical Report
Elizaveta Goncharova, Anton Razzhigaev, Matvey Mikhalchuk, Maxim Kurkin, Irina Abdullaeva, Matvey Skripkin, Ivan Oseledets, Denis Dimitrov, Andrey Kuznetsov
0
0
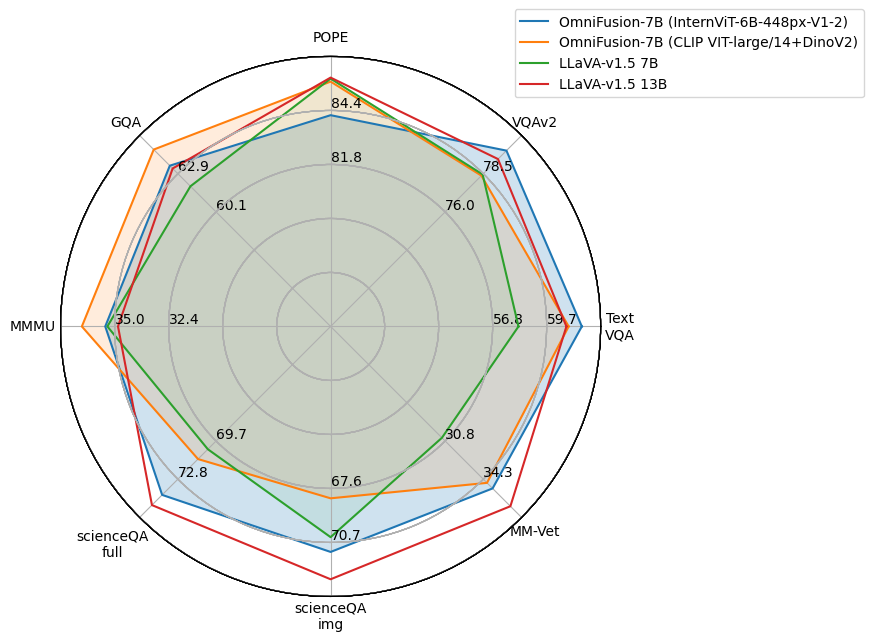
Last year, multimodal architectures served up a revolution in AI-based approaches and solutions, extending the capabilities of large language models (LLM). We propose an textit{OmniFusion} model based on a pretrained LLM and adapters for visual modality. We evaluated and compared several architecture design principles for better text and visual data coupling: MLP and transformer adapters, various CLIP ViT-based encoders (SigLIP, InternVIT, etc.), and their fusing approach, image encoding method (whole image or tiles encoding) and two 7B LLMs (the proprietary one and open-source Mistral). Experiments on 8 visual-language benchmarks show the top score for the best OmniFusion setup in terms of different VQA tasks in comparison with open-source LLaVA-like solutions: VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU. We also propose a variety of situations, where OmniFusion provides highly-detailed answers in different domains: housekeeping, sightseeing, culture, medicine, handwritten and scanned equations recognition, etc. Mistral-based OmniFusion model is an open-source solution with weights, training and inference scripts available at https://github.com/AIRI-Institute/OmniFusion.
4/10/2024