MarkLLM: An Open-Source Toolkit for LLM Watermarking
2405.10051
2
0

Abstract
LLM watermarking, which embeds imperceptible yet algorithmically detectable signals in model outputs to identify LLM-generated text, has become crucial in mitigating the potential misuse of large language models. However, the abundance of LLM watermarking algorithms, their intricate mechanisms, and the complex evaluation procedures and perspectives pose challenges for researchers and the community to easily experiment with, understand, and assess the latest advancements. To address these issues, we introduce MarkLLM, an open-source toolkit for LLM watermarking. MarkLLM offers a unified and extensible framework for implementing LLM watermarking algorithms, while providing user-friendly interfaces to ensure ease of access. Furthermore, it enhances understanding by supporting automatic visualization of the underlying mechanisms of these algorithms. For evaluation, MarkLLM offers a comprehensive suite of 12 tools spanning three perspectives, along with two types of automated evaluation pipelines. Through MarkLLM, we aim to support researchers while improving the comprehension and involvement of the general public in LLM watermarking technology, fostering consensus and driving further advancements in research and application. Our code is available at https://github.com/THU-BPM/MarkLLM.
Create account to get full access
Overview
- This paper introduces MarkLLM, an open-source toolkit for watermarking large language models (LLMs)
- Watermarking helps identify the origin and provenance of LLM-generated content, which is important for tracking model misuse and ensuring accountability
- MarkLLM provides a flexible and customizable framework for embedding watermarks in LLM outputs, along with tools for detecting and extracting those watermarks
Plain English Explanation
MarkLLM: An Open-Source Toolkit for LLM Watermarking is a research project that tackles the challenge of identifying the source of text generated by large language models (LLMs). These powerful AI systems can be used to produce human-like text on a wide range of topics, but there's a risk that the generated content could be misused or shared without proper attribution.
To address this, the researchers developed MarkLLM, a toolkit that allows LLM developers to embed invisible "watermarks" into the text generated by their models. These watermarks act like digital signatures, making it possible to trace the origin of the text back to the specific model that produced it.
The watermarks are designed to be robust and difficult to remove, so even if someone tries to pass off the generated text as their own, the watermark can be detected. This helps ensure accountability and transparency around the use of LLMs, which is important as these technologies become more widely adopted.
MarkLLM provides a flexible framework that LLM developers can use to customize the watermarking process to their specific needs. It includes tools for embedding the watermarks, as well as for detecting and extracting them from the generated text. This makes it easier for researchers, companies, and other stakeholders to monitor and track the use of LLM-generated content.
Technical Explanation
MarkLLM: An Open-Source Toolkit for LLM Watermarking presents a comprehensive framework for watermarking the outputs of large language models (LLMs). Watermarking is a technique that allows the origin and provenance of generated text to be identified, which is crucial for ensuring accountability and traceability in the use of these powerful AI systems.
The paper introduces a set of techniques for embedding watermarks into the language model's outputs in a robust and efficient manner. These watermarks are designed to be invisible to human readers but can be reliably detected and extracted, even if the generated text has been modified or manipulated. The watermarking process is also customizable, allowing LLM developers to tailor the watermarks to their specific needs and use cases.
The researchers evaluate the effectiveness of their watermarking approach through a series of experiments, testing the robustness of the watermarks against common attacks such as text editing, paraphrasing, and translation. They also demonstrate the efficiency of the watermarking process, showing that it can be applied to LLM outputs without significantly impacting the model's performance or the quality of the generated text.
In addition to the technical details of the watermarking framework, the paper also discusses the broader implications of this work, including the importance of transparency and accountability in the use of large language models, and the potential for watermarking to be used as a tool for tracing and mitigating model misuse.
Critical Analysis
The MarkLLM paper presents a robust and flexible framework for watermarking the outputs of large language models, which is an important step towards ensuring the responsible and accountable use of these powerful AI systems.
One potential limitation of the research is that it focuses primarily on evaluating the technical performance of the watermarking approach, without delving deeply into the broader social and ethical implications of this technology. While the paper acknowledges the importance of transparency and accountability, it doesn't fully explore the potential risks or unintended consequences of widespread watermarking of LLM outputs.
For example, the researchers don't discuss how watermarking might impact user privacy, or how it could be used to suppress or censor certain types of content. There's also a question of how watermarking might influence the behavior of LLM users, and whether it could lead to a chilling effect on creative expression or open discourse.
Additionally, the paper doesn't address the potential for watermarking to be used as a tool for surveillance or control, or how it might interact with other emerging technologies like content moderation and deepfake detection.
Overall, while the MarkLLM research represents an important technical contribution, there's a need for a more holistic examination of the societal implications of this technology. As LLMs become more widely adopted, it will be crucial to consider not just the technical capabilities of watermarking, but also its potential impacts on individual rights, democratic processes, and the broader ecosystem of AI-powered communication and information sharing.
Conclusion
MarkLLM: An Open-Source Toolkit for LLM Watermarking introduces a robust and flexible framework for embedding watermarks into the outputs of large language models. These watermarks allow the origin and provenance of LLM-generated content to be reliably identified, which is crucial for ensuring accountability and transparency in the use of these powerful AI systems.
The researchers have developed a range of techniques for embedding watermarks in a way that is both efficient and resistant to common attacks, such as text editing and paraphrasing. They have also provided an open-source toolkit that LLM developers can use to customize and implement the watermarking process to suit their specific needs.
While the technical innovations presented in this paper are significant, it's important to also consider the broader societal implications of watermarking technology. As MarkLLM and similar approaches become more widely adopted, there will be a need to carefully examine how they might impact user privacy, creative expression, and the overall ecosystem of AI-powered communication and information sharing.
Overall, the MarkLLM research represents an important step forward in the quest to ensure the responsible and accountable use of large language models. As these technologies continue to evolve, it will be crucial for the research community, policymakers, and the public to engage in an ongoing dialogue about the ethical and social implications of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models
Ruisi Zhang, Shehzeen Samarah Hussain, Paarth Neekhara, Farinaz Koushanfar
0
0
We present REMARK-LLM, a novel efficient, and robust watermarking framework designed for texts generated by large language models (LLMs). Synthesizing human-like content using LLMs necessitates vast computational resources and extensive datasets, encapsulating critical intellectual property (IP). However, the generated content is prone to malicious exploitation, including spamming and plagiarism. To address the challenges, REMARK-LLM proposes three new components: (i) a learning-based message encoding module to infuse binary signatures into LLM-generated texts; (ii) a reparameterization module to transform the dense distributions from the message encoding to the sparse distribution of the watermarked textual tokens; (iii) a decoding module dedicated for signature extraction; Furthermore, we introduce an optimized beam search algorithm to guarantee the coherence and consistency of the generated content. REMARK-LLM is rigorously trained to encourage the preservation of semantic integrity in watermarked content, while ensuring effective watermark retrieval. Extensive evaluations on multiple unseen datasets highlight REMARK-LLM proficiency and transferability in inserting 2 times more signature bits into the same texts when compared to prior art, all while maintaining semantic integrity. Furthermore, REMARK-LLM exhibits better resilience against a spectrum of watermark detection and removal attacks.
4/9/2024
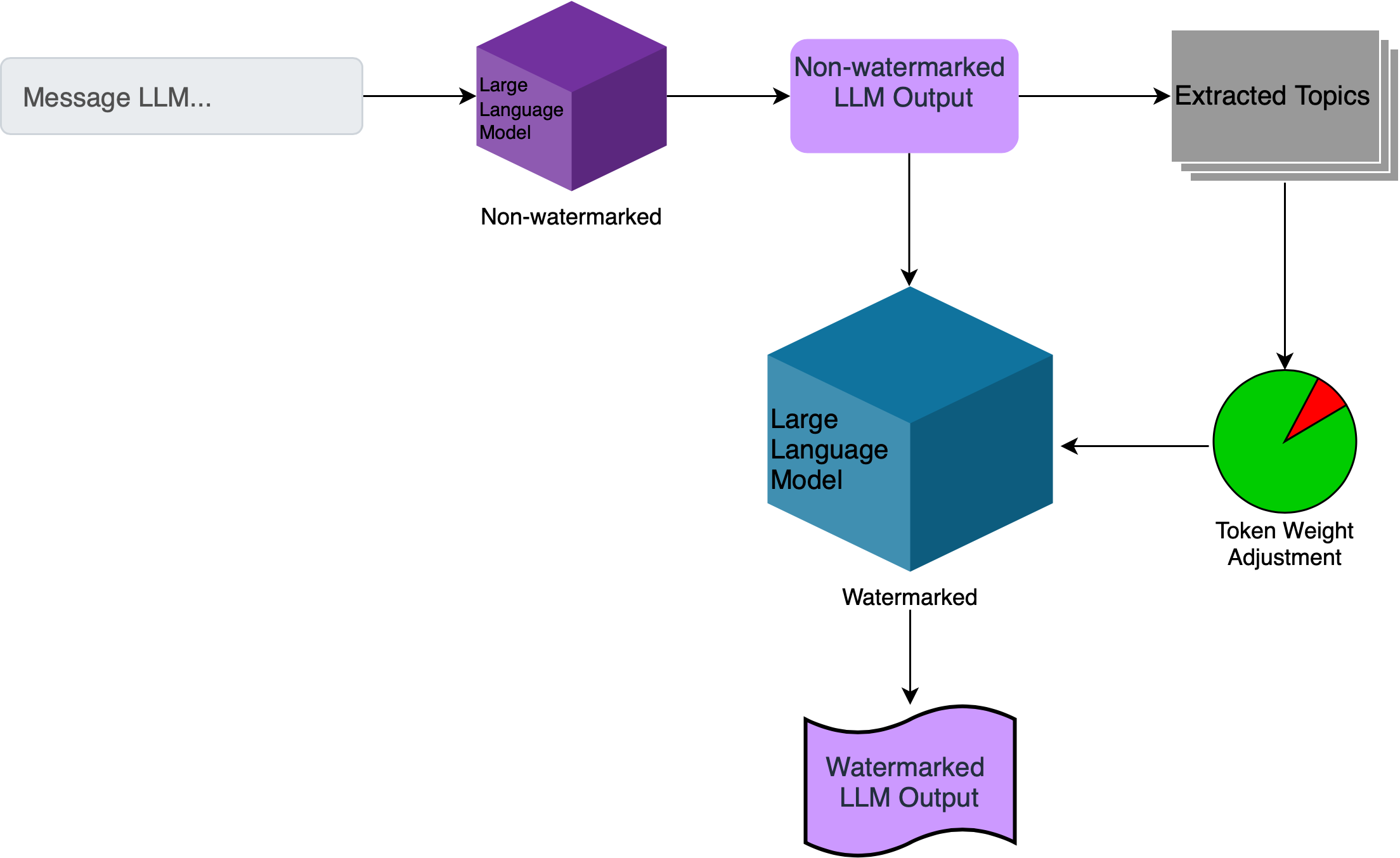
Topic-based Watermarks for LLM-Generated Text
Alexander Nemecek, Yuzhou Jiang, Erman Ayday
0
0
Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a topic-based watermarking algorithm for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.
4/17/2024
💬
Publicly-Detectable Watermarking for Language Models
Jaiden Fairoze, Sanjam Garg, Somesh Jha, Saeed Mahloujifar, Mohammad Mahmoody, Mingyuan Wang
0
0
We present a highly detectable, trustless watermarking scheme for LLMs: the detection algorithm contains no secret information, and it is executable by anyone. We embed a publicly-verifiable cryptographic signature into LLM output using rejection sampling. We prove that our scheme is cryptographically correct, sound, and distortion-free. We make novel uses of error-correction techniques to overcome periods of low entropy, a barrier for all prior watermarking schemes. We implement our scheme and make empirical measurements over open models in the 2.7B to 70B parameter range. Our experiments suggest that our formal claims are met in practice.
5/29/2024
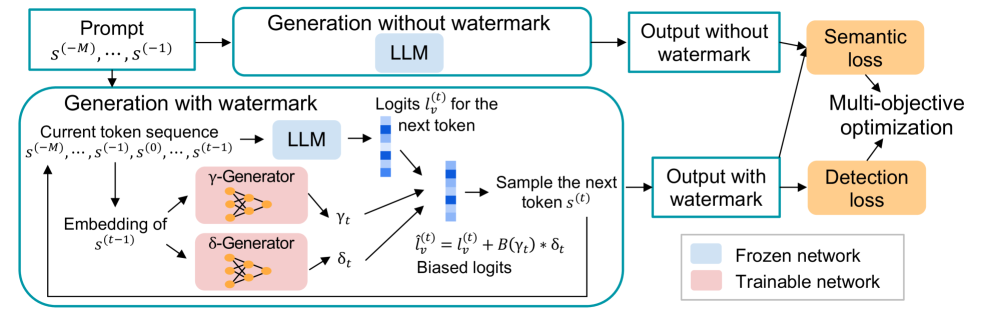
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mingjia Huo, Sai Ashish Somayajula, Youwei Liang, Ruisi Zhang, Farinaz Koushanfar, Pengtao Xie
0
0
Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Achieving both the detectability of inserted watermarks and the semantic quality of generated texts is challenging. While current watermarking algorithms have made promising progress in this direction, there remains significant scope for improvement. To address these challenges, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
6/7/2024