REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models
2310.12362
0
0
💬
Abstract
We present REMARK-LLM, a novel efficient, and robust watermarking framework designed for texts generated by large language models (LLMs). Synthesizing human-like content using LLMs necessitates vast computational resources and extensive datasets, encapsulating critical intellectual property (IP). However, the generated content is prone to malicious exploitation, including spamming and plagiarism. To address the challenges, REMARK-LLM proposes three new components: (i) a learning-based message encoding module to infuse binary signatures into LLM-generated texts; (ii) a reparameterization module to transform the dense distributions from the message encoding to the sparse distribution of the watermarked textual tokens; (iii) a decoding module dedicated for signature extraction; Furthermore, we introduce an optimized beam search algorithm to guarantee the coherence and consistency of the generated content. REMARK-LLM is rigorously trained to encourage the preservation of semantic integrity in watermarked content, while ensuring effective watermark retrieval. Extensive evaluations on multiple unseen datasets highlight REMARK-LLM proficiency and transferability in inserting 2 times more signature bits into the same texts when compared to prior art, all while maintaining semantic integrity. Furthermore, REMARK-LLM exhibits better resilience against a spectrum of watermark detection and removal attacks.
Create account to get full access
Overview
- Presents a new framework called REMARK-LLM for watermarking text generated by large language models (LLMs)
- Aims to address challenges of malicious exploitation of LLM-generated content, such as spamming and plagiarism
- Introduces three key components: a message encoding module, a reparameterization module, and a decoding module
- Includes an optimized beam search algorithm to maintain coherence and consistency of watermarked content
- Rigorous evaluation shows REMARK-LLM can insert more signature bits while preserving semantic integrity, and is more resilient to detection and removal attacks
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text content. However, the vast computational resources and datasets required to develop these models mean the generated content encapsulates critical intellectual property (IP) that needs to be protected. The text produced by LLMs is also prone to misuse, such as spamming and plagiarism.
To address these challenges, the researchers present REMARK-LLM, a new framework for watermarking LLM-generated text. Watermarking is a technique that embeds a hidden signature or identifier into the content, allowing the origin to be traced.
REMARK-LLM has three key components:
- A "message encoding" module that infuses binary signatures into the LLM-generated text.
- A "reparameterization" module that transforms the encoded message into a format that can be reliably embedded in the text.
- A "decoding" module that can extract the watermark from the text.
The framework also includes an optimized "beam search" algorithm to ensure the watermarked text remains coherent and consistent.
The researchers rigorously tested REMARK-LLM and found it can insert up to 2 times more signature bits into the same text compared to prior methods, while still preserving the meaning and quality of the content. It also exhibits stronger resilience against attempts to detect or remove the watermark.
Technical Explanation
REMARK-LLM is a novel watermarking framework designed to protect the intellectual property (IP) encapsulated in text generated by large language models (LLMs). LLMs can synthesize highly human-like content, but this content is vulnerable to malicious exploitation, such as spamming and plagiarism.
The REMARK-LLM framework consists of three key components:
-
Message Encoding Module: This module uses a learning-based approach to infuse binary signatures into the LLM-generated text. The goal is to insert as much watermark information as possible while preserving the semantic integrity of the content.
-
Reparameterization Module: The dense distributions produced by the message encoding module are transformed into a sparse distribution of watermarked textual tokens. This reparameterization step is critical for ensuring the watermark can be reliably extracted.
-
Decoding Module: This module is specifically designed for extracting the embedded watermark signatures from the text.
In addition, the researchers introduce an optimized beam search algorithm to generate watermarked text that maintains coherence and consistency.
REMARK-LLM is trained to strike a balance between preserving semantic integrity and enabling effective watermark retrieval. Extensive evaluations on multiple unseen datasets show that REMARK-LLM can insert up to 2 times more signature bits compared to prior art, while also exhibiting better resilience against detection and removal attacks.
Critical Analysis
The researchers acknowledge that REMARK-LLM has some limitations. For example, the framework currently only supports binary watermark encoding, and further research is needed to extend it to multi-bit watermarks. Additionally, the impact of the watermarking process on the downstream performance of the LLM, such as personalized recommendation, is not explored in depth.
Another potential concern is the robustness of the watermark against more advanced detection and removal attacks. While the paper demonstrates REMARK-LLM's resilience, it's possible that more sophisticated techniques could be developed to circumvent the watermarking system.
Overall, REMARK-LLM represents a promising step towards addressing the IP and misuse challenges associated with LLM-generated content. However, further research and real-world deployments are needed to fully evaluate the framework's effectiveness and practical implications.
Conclusion
REMARK-LLM is a novel and efficient watermarking framework designed to protect the intellectual property (IP) embedded in text generated by large language models (LLMs). By introducing a learning-based message encoding module, a reparameterization module, and a decoding module, REMARK-LLM can insert significantly more watermark information into LLM-generated content while preserving semantic integrity.
The researchers' rigorous evaluations demonstrate REMARK-LLM's superior performance in terms of watermark capacity and resilience against detection and removal attacks, highlighting its potential to address the growing challenges of malicious exploitation of LLM-generated content. As LLMs continue to advance and become more widely adopted, frameworks like REMARK-LLM will play a crucial role in safeguarding the IP and ensuring the responsible development and deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MarkLLM: An Open-Source Toolkit for LLM Watermarking
Leyi Pan, Aiwei Liu, Zhiwei He, Zitian Gao, Xuandong Zhao, Yijian Lu, Binglin Zhou, Shuliang Liu, Xuming Hu, Lijie Wen, Irwin King
0
0
LLM watermarking, which embeds imperceptible yet algorithmically detectable signals in model outputs to identify LLM-generated text, has become crucial in mitigating the potential misuse of large language models. However, the abundance of LLM watermarking algorithms, their intricate mechanisms, and the complex evaluation procedures and perspectives pose challenges for researchers and the community to easily experiment with, understand, and assess the latest advancements. To address these issues, we introduce MarkLLM, an open-source toolkit for LLM watermarking. MarkLLM offers a unified and extensible framework for implementing LLM watermarking algorithms, while providing user-friendly interfaces to ensure ease of access. Furthermore, it enhances understanding by supporting automatic visualization of the underlying mechanisms of these algorithms. For evaluation, MarkLLM offers a comprehensive suite of 12 tools spanning three perspectives, along with two types of automated evaluation pipelines. Through MarkLLM, we aim to support researchers while improving the comprehension and involvement of the general public in LLM watermarking technology, fostering consensus and driving further advancements in research and application. Our code is available at https://github.com/THU-BPM/MarkLLM.
5/27/2024

A Semantic Invariant Robust Watermark for Large Language Models
Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, Lijie Wen
0
0
Watermark algorithms for large language models (LLMs) have achieved extremely high accuracy in detecting text generated by LLMs. Such algorithms typically involve adding extra watermark logits to the LLM's logits at each generation step. However, prior algorithms face a trade-off between attack robustness and security robustness. This is because the watermark logits for a token are determined by a certain number of preceding tokens; a small number leads to low security robustness, while a large number results in insufficient attack robustness. In this work, we propose a semantic invariant watermarking method for LLMs that provides both attack robustness and security robustness. The watermark logits in our work are determined by the semantics of all preceding tokens. Specifically, we utilize another embedding LLM to generate semantic embeddings for all preceding tokens, and then these semantic embeddings are transformed into the watermark logits through our trained watermark model. Subsequent analyses and experiments demonstrated the attack robustness of our method in semantically invariant settings: synonym substitution and text paraphrasing settings. Finally, we also show that our watermark possesses adequate security robustness. Our code and data are available at href{https://github.com/THU-BPM/Robust_Watermark}{https://github.com/THU-BPM/Robust_Watermark}. Additionally, our algorithm could also be accessed through MarkLLM citep{pan2024markllm} footnote{https://github.com/THU-BPM/MarkLLM}.
5/21/2024
💬
On the Reliability of Watermarks for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, Tom Goldstein
0
0
As LLMs become commonplace, machine-generated text has the potential to flood the internet with spam, social media bots, and valueless content. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text may be modified to suit a user's needs, or entirely rewritten to avoid detection. We study the robustness of watermarked text after it is re-written by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document. We find that watermarks remain detectable even after human and machine paraphrasing. While these attacks dilute the strength of the watermark, paraphrases are statistically likely to leak n-grams or even longer fragments of the original text, resulting in high-confidence detections when enough tokens are observed. For example, after strong human paraphrasing the watermark is detectable after observing 800 tokens on average, when setting a 1e-5 false positive rate. We also consider a range of new detection schemes that are sensitive to short spans of watermarked text embedded inside a large document, and we compare the robustness of watermarking to other kinds of detectors.
5/3/2024
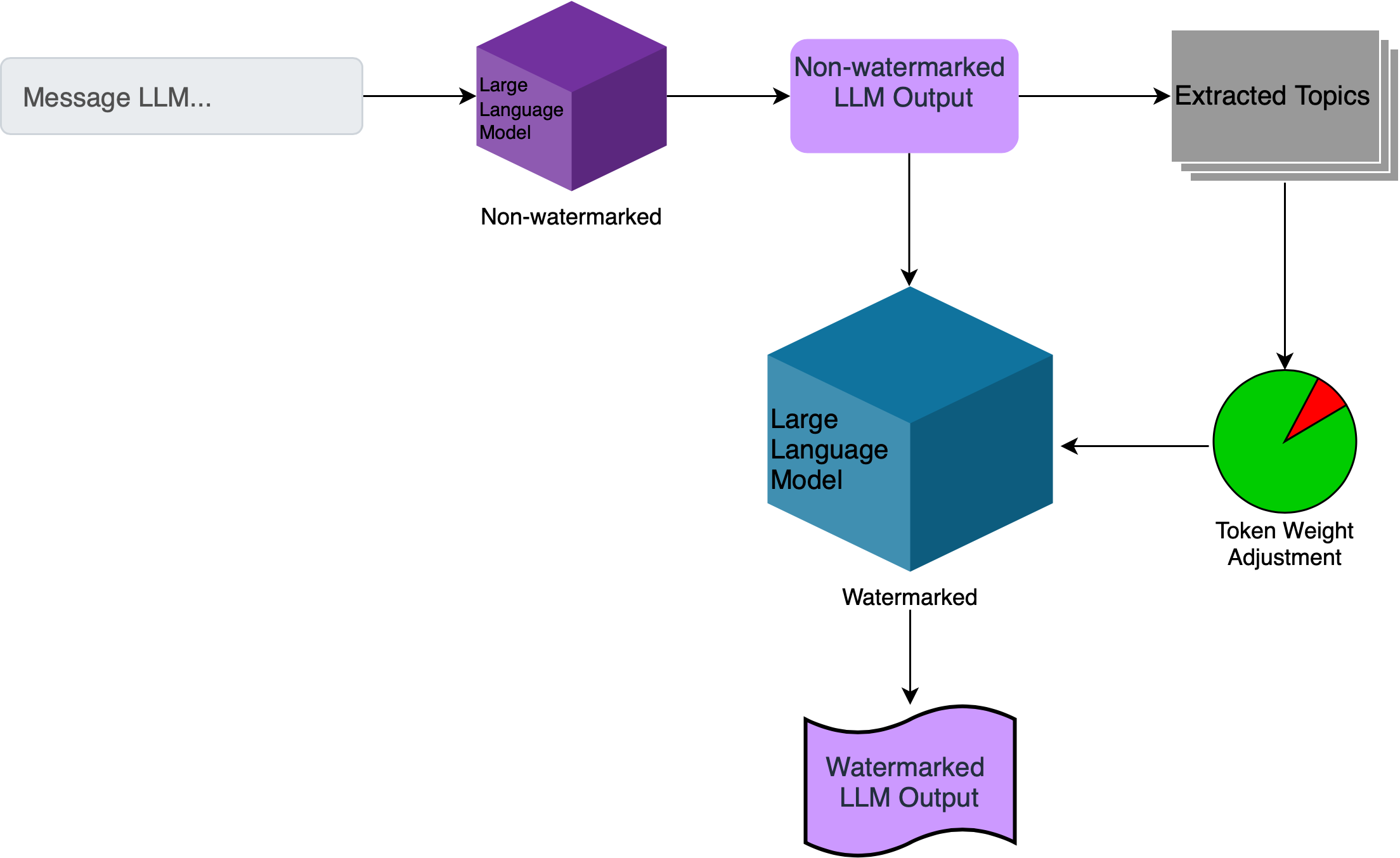
Topic-based Watermarks for LLM-Generated Text
Alexander Nemecek, Yuzhou Jiang, Erman Ayday
0
0
Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a topic-based watermarking algorithm for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.
4/17/2024