Publicly-Detectable Watermarking for Language Models
2310.18491
0
0
💬
Abstract
We present a highly detectable, trustless watermarking scheme for LLMs: the detection algorithm contains no secret information, and it is executable by anyone. We embed a publicly-verifiable cryptographic signature into LLM output using rejection sampling. We prove that our scheme is cryptographically correct, sound, and distortion-free. We make novel uses of error-correction techniques to overcome periods of low entropy, a barrier for all prior watermarking schemes. We implement our scheme and make empirical measurements over open models in the 2.7B to 70B parameter range. Our experiments suggest that our formal claims are met in practice.
Create account to get full access
Overview
- Presents a watermarking scheme for large language models (LLMs) that is highly detectable and trustless
- The detection algorithm contains no secret information and can be executed by anyone
- Embeds a publicly-verifiable cryptographic signature into LLM output using rejection sampling
- Proves the scheme is cryptographically correct, sound, and distortion-free
- Makes novel uses of error-correction techniques to overcome periods of low entropy, a barrier for prior watermarking schemes
- Implements the scheme and measures its performance on open models ranging from 2.7B to 70B parameters
Plain English Explanation
This paper describes a new way to watermark the outputs of large language models (LLMs) like GPT-3 or DALL-E. Watermarking is a technique to embed hidden information in the output of an AI system, allowing the origin of the output to be traced.
The key innovation of this watermarking scheme is that it is highly detectable and trustless. This means that anyone can check whether the output of an LLM contains the watermark, without needing any secret information. The watermark is a cryptographic signature that is embedded into the model's output using a technique called rejection sampling.
The researchers prove that this watermarking scheme is cryptographically secure, meaning it cannot be forged or removed without detection. They also show that it doesn't degrade the quality or distort the output of the LLM.
A major challenge in watermarking LLMs is that they can sometimes produce outputs with low entropy (unpredictability), making it hard to reliably embed a watermark. The researchers overcome this by using novel error-correction techniques.
The researchers implement their watermarking scheme and test it on a range of open-source LLMs, from 2.7 billion to 70 billion parameters. Their experiments confirm that the formal claims about the scheme's properties hold true in practice.
Technical Explanation
The paper presents a trustless watermarking scheme for large language models (LLMs) that embeds a publicly-verifiable cryptographic signature into the model's output. The detection algorithm for this watermark contains no secret information, allowing anyone to verify the watermark.
The core of the scheme is a rejection sampling process that selects model outputs containing the desired watermark. The researchers prove that this process is cryptographically correct, meaning the watermark cannot be forged or removed without detection, and sound, meaning the watermark is reliably detectable.
A key challenge in watermarking LLMs is that their outputs can sometimes have low entropy (unpredictability), making it difficult to reliably embed a watermark. The researchers address this by making novel use of error-correction techniques, overcoming a barrier that has plagued prior watermarking schemes.
The researchers implement their watermarking scheme and empirically evaluate it on open-source LLMs ranging from 2.7 billion to 70 billion parameters. Their experiments confirm that the formal claims about the scheme's cryptographic correctness, soundness, and distortion-freedom hold true in practice.
Critical Analysis
The paper presents a thoughtful and well-executed approach to the challenging problem of watermarking large language models. The researchers' use of error-correction techniques to overcome periods of low entropy is a particularly novel and valuable contribution.
That said, the paper does not address some potential limitations or edge cases. For example, the watermarking scheme may be vulnerable to attacks that exploit the statistical patterns introduced by the rejection sampling process. Additionally, the scheme's reliance on cryptographic signatures raises questions about the long-term viability as quantum computing advances.
Further research is needed to explore the learnability and semantic robustness of this watermarking approach, as well as its applicability to a broader range of AI systems beyond just language models.
Overall, this paper represents an important step forward in the development of trustless and robust watermarking techniques for large, powerful AI models. However, continued scrutiny and further innovations will be necessary to address the evolving challenges in this space.
Conclusion
This paper presents a highly detectable and trustless watermarking scheme for large language models (LLMs). The scheme embeds a publicly-verifiable cryptographic signature into the model's output, allowing anyone to detect the watermark without any secret information.
The researchers prove the scheme's cryptographic correctness, soundness, and distortion-freedom, and demonstrate its practical viability through empirical evaluation on open-source LLMs. Their novel use of error-correction techniques to overcome periods of low entropy is a key contribution that addresses a longstanding challenge in LLM watermarking.
While the paper does not address all potential limitations, it represents an important advancement in the development of trustworthy and robust watermarking for powerful AI systems. As the field of AI continues to evolve, ongoing research and innovation in this area will be crucial to ensuring the responsible and accountable development of transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Black-Box Detection of Language Model Watermarks
Gloaguen Thibaud, Jovanovi'c Nikola, Staab Robin, Vechev Martin
0
0
Watermarking has emerged as a promising way to detect LLM-generated text. To apply a watermark an LLM provider, given a secret key, augments generations with a signal that is later detectable by any party with the same key. Recent work has proposed three main families of watermarking schemes, two of which focus on the property of preserving the LLM distribution. This is motivated by it being a tractable proxy for maintaining LLM capabilities, but also by the idea that concealing a watermark deployment makes it harder for malicious actors to hide misuse by avoiding a certain LLM or attacking its watermark. Yet, despite much discourse around detectability, no prior work has investigated if any of these scheme families are detectable in a realistic black-box setting. We tackle this for the first time, developing rigorous statistical tests to detect the presence of all three most popular watermarking scheme families using only a limited number of black-box queries. We experimentally confirm the effectiveness of our methods on a range of schemes and a diverse set of open-source models. Our findings indicate that current watermarking schemes are more detectable than previously believed, and that obscuring the fact that a watermark was deployed may not be a viable way for providers to protect against adversaries. We further apply our methods to test for watermark presence behind the most popular public APIs: GPT4, Claude 3, Gemini 1.0 Pro, finding no strong evidence of a watermark at this point in time.
6/3/2024
💬
Robust Distortion-free Watermarks for Language Models
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, Percy Liang
0
0
We propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain maximum generation budget. We generate watermarked text by mapping a sequence of random numbers -- which we compute using a randomized watermark key -- to a sample from the language model. To detect watermarked text, any party who knows the key can align the text to the random number sequence. We instantiate our watermark methodology with two sampling schemes: inverse transform sampling and exponential minimum sampling. We apply these watermarks to three language models -- OPT-1.3B, LLaMA-7B and Alpaca-7B -- to experimentally validate their statistical power and robustness to various paraphrasing attacks. Notably, for both the OPT-1.3B and LLaMA-7B models, we find we can reliably detect watermarked text ($p leq 0.01$) from $35$ tokens even after corrupting between $40$-$50%$ of the tokens via random edits (i.e., substitutions, insertions or deletions). For the Alpaca-7B model, we conduct a case study on the feasibility of watermarking responses to typical user instructions. Due to the lower entropy of the responses, detection is more difficult: around $25%$ of the responses -- whose median length is around $100$ tokens -- are detectable with $p leq 0.01$, and the watermark is also less robust to certain automated paraphrasing attacks we implement.
6/7/2024
💬
A Watermark for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein
0
0
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of green tokens before a word is generated, and then softly promoting use of green tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
5/3/2024
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mingjia Huo, Sai Ashish Somayajula, Youwei Liang, Ruisi Zhang, Farinaz Koushanfar, Pengtao Xie
0
0
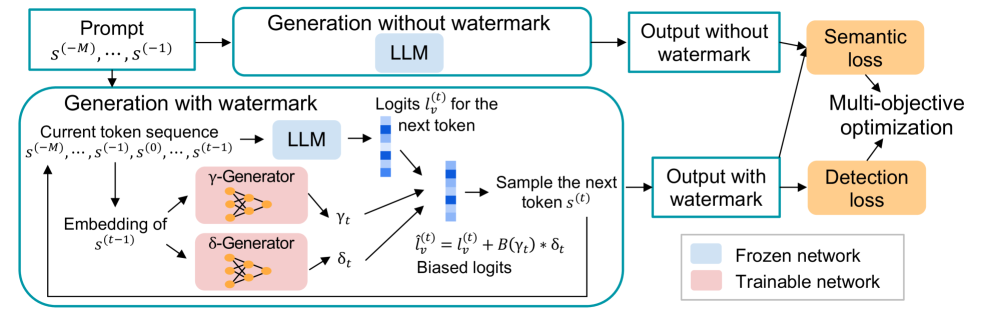
Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Achieving both the detectability of inserted watermarks and the semantic quality of generated texts is challenging. While current watermarking algorithms have made promising progress in this direction, there remains significant scope for improvement. To address these challenges, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
6/7/2024