MARS: Multimodal Active Robotic Sensing for Articulated Characterization

0
Sign in to get full access
Overview
- Describes a system called MARS (Multimodal Active Robotic Sensing) for characterizing articulated objects
- Uses a combination of sensing modalities (vision, force/torque, and proprioception) and active robotic manipulation to build detailed models of complex 3D objects
- Aims to enable robots to better understand and interact with a wide range of articulated objects in unstructured environments
Plain English Explanation
The MARS system is designed to help robots better understand and interact with 3D objects that have movable parts, such as tools, appliances, and machinery. Rather than just looking at an object from a single viewpoint, MARS uses a variety of sensors - including cameras, force/torque sensors, and joint position feedback - to actively manipulate and observe the object from multiple angles.
By combining these different sensing modalities, MARS can build a detailed 3D model of the object and learn how its parts are connected and move. This understanding allows the robot to anticipate how the object will respond to different interactions, which is crucial for tasks like grasping, inserting, or assembling the object.
The active robotic manipulation employed by MARS is also key - rather than just passively observing the object, the robot purposefully moves and interacts with it to gather the most informative data. This active sensing approach helps the robot quickly build an accurate model of even complex, articulated objects.
Technical Explanation
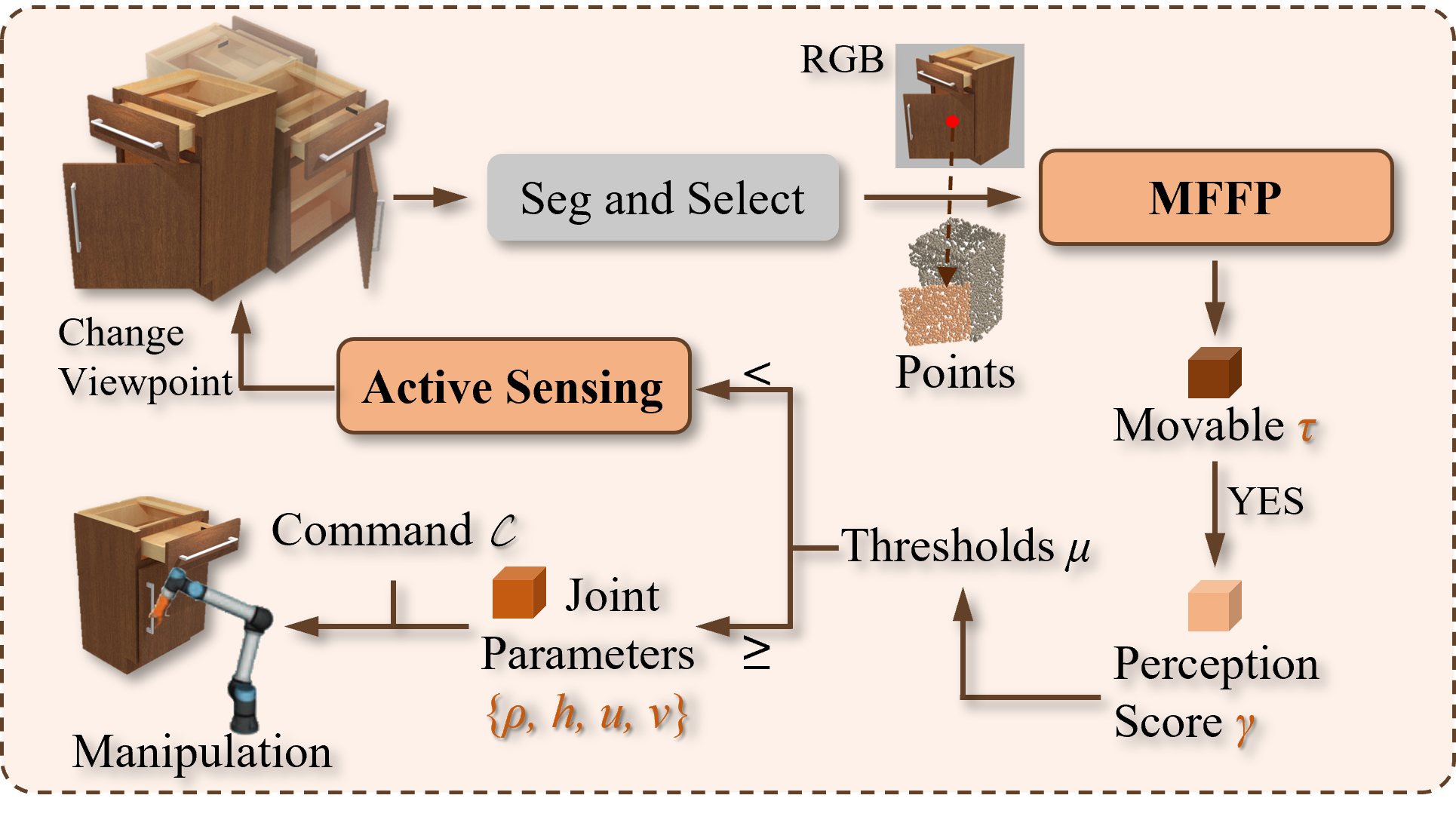
The core of the MARS system is a multi-modal sensing pipeline that fuses data from cameras, force/torque sensors, and joint position/velocity feedback to build a comprehensive model of an articulated object. First, the robot uses visual cues to roughly segment the object into its constituent parts. It then systematically manipulates the object, measuring the forces, torques, and joint motions at each step.
This data is used to reconstruct the 3D shape and joint structure of the object, as well as learn a predictive model of how its parts move in relation to one another. The system can then use this model to plan optimal sensing strategies to further refine its understanding of the object.
Experiments demonstrate MARS's ability to accurately characterize a variety of complex, articulated objects, including tools, appliances, and furniture. The active sensing approach allows the system to build high-fidelity models using fewer physical interactions compared to passive observation.
Critical Analysis
The MARS paper makes a compelling case for the value of integrating multimodal sensing and active manipulation to enable more sophisticated robot understanding and interaction with articulated objects. The experimental results demonstrate impressive performance, and the authors acknowledge several limitations and areas for future work.
One potential concern is the reliance on precise force/torque and joint sensing, which may not always be available on real-world robot platforms. The authors suggest exploring alternative sensing modalities, such as vision-based force estimation, to address this.
Additionally, the paper focuses on single-object scenarios, but many real-world tasks involve reasoning about collections of interacting objects. Extending MARS to handle such multi-object settings could be an important direction for future research.
Overall, the MARS system represents a significant advance in robotic manipulation capabilities, with promising applications in areas like assistive robotics, industrial automation, and household task assistance.
Conclusion
The MARS system demonstrates the power of integrating multimodal sensing and active manipulation to enable robots to build detailed models of complex, articulated objects. By fusing visual, force/torque, and proprioceptive data, the system can quickly and accurately characterize the 3D shape and joint structure of a wide range of objects.
This fundamental capability underpins many important robotic skills, such as dexterous grasping, tool use, and object assembly. As robots continue to play a growing role in our daily lives, systems like MARS will be crucial for enabling them to better understand and interact with the diverse range of objects found in unstructured human environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MARS: Multimodal Active Robotic Sensing for Articulated Characterization
Hongliang Zeng, Ping Zhang, Chengjiong Wu, Jiahua Wang, Tingyu Ye, Fang Li
Precise perception of articulated objects is vital for empowering service robots. Recent studies mainly focus on point cloud, a single-modal approach, often neglecting vital texture and lighting details and assuming ideal conditions like optimal viewpoints, unrepresentative of real-world scenarios. To address these limitations, we introduce MARS, a novel framework for articulated object characterization. It features a multi-modal fusion module utilizing multi-scale RGB features to enhance point cloud features, coupled with reinforcement learning-based active sensing for autonomous optimization of observation viewpoints. In experiments conducted with various articulated object instances from the PartNet-Mobility dataset, our method outperformed current state-of-the-art methods in joint parameter estimation accuracy. Additionally, through active sensing, MARS further reduces errors, demonstrating enhanced efficiency in handling suboptimal viewpoints. Furthermore, our method effectively generalizes to real-world articulated objects, enhancing robot interactions. Code is available at https://github.com/robhlzeng/MARS.
Read more7/2/2024

0
Multiagent Multitraversal Multimodal Self-Driving: Open MARS Dataset
Yiming Li, Zhiheng Li, Nuo Chen, Moonjun Gong, Zonglin Lyu, Zehong Wang, Peili Jiang, Chen Feng
Large-scale datasets have fueled recent advancements in AI-based autonomous vehicle research. However, these datasets are usually collected from a single vehicle's one-time pass of a certain location, lacking multiagent interactions or repeated traversals of the same place. Such information could lead to transformative enhancements in autonomous vehicles' perception, prediction, and planning capabilities. To bridge this gap, in collaboration with the self-driving company May Mobility, we present the MARS dataset which unifies scenarios that enable MultiAgent, multitraveRSal, and multimodal autonomous vehicle research. More specifically, MARS is collected with a fleet of autonomous vehicles driving within a certain geographical area. Each vehicle has its own route and different vehicles may appear at nearby locations. Each vehicle is equipped with a LiDAR and surround-view RGB cameras. We curate two subsets in MARS: one facilitates collaborative driving with multiple vehicles simultaneously present at the same location, and the other enables memory retrospection through asynchronous traversals of the same location by multiple vehicles. We conduct experiments in place recognition and neural reconstruction. More importantly, MARS introduces new research opportunities and challenges such as multitraversal 3D reconstruction, multiagent perception, and unsupervised object discovery. Our data and codes can be found at https://ai4ce.github.io/MARS/.
Read more6/14/2024

0
RoboMNIST: A Multimodal Dataset for Multi-Robot Activity Recognition Using WiFi Sensing, Video, and Audio
Kian Behzad, Rojin Zandi, Elaheh Motamedi, Hojjat Salehinejad, Milad Siami
We introduce a novel dataset for multi-robot activity recognition (MRAR) using two robotic arms integrating WiFi channel state information (CSI), video, and audio data. This multimodal dataset utilizes signals of opportunity, leveraging existing WiFi infrastructure to provide detailed indoor environmental sensing without additional sensor deployment. Data were collected using two Franka Emika robotic arms, complemented by three cameras, three WiFi sniffers to collect CSI, and three microphones capturing distinct yet complementary audio data streams. The combination of CSI, visual, and auditory data can enhance robustness and accuracy in MRAR. This comprehensive dataset enables a holistic understanding of robotic environments, facilitating advanced autonomous operations that mimic human-like perception and interaction. By repurposing ubiquitous WiFi signals for environmental sensing, this dataset offers significant potential aiming to advance robotic perception and autonomous systems. It provides a valuable resource for developing sophisticated decision-making and adaptive capabilities in dynamic environments.
Read more8/30/2024

0
New!NARF24: Estimating Articulated Object Structure for Implicit Rendering
Stanley Lewis, Tom Gao, Odest Chadwicke Jenkins
Articulated objects and their representations pose a difficult problem for robots. These objects require not only representations of geometry and texture, but also of the various connections and joint parameters that make up each articulation. We propose a method that learns a common Neural Radiance Field (NeRF) representation across a small number of collected scenes. This representation is combined with a parts-based image segmentation to produce an implicit space part localization, from which the connectivity and joint parameters of the articulated object can be estimated, thus enabling configuration-conditioned rendering.
Read more9/17/2024