Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
2404.17302
0
0
🎯
Abstract
Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots. Existing learning-based solutions mainly focus on visual affordance learning or other pre-trained visual models to guide manipulation policies, which face challenges for novel instances in real-world scenarios. In this paper, we propose a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. To improve the stability of the policy on real robots, we design a Frame-consistent Uncertainty-aware Sampling (FUS) strategy to get a condensed and hierarchical 3D representation. In addition, a single versatile RL policy can be trained on multiple articulated object manipulation tasks simultaneously in simulation and shows great generalizability to novel categories and instances. Experimental results demonstrate the effectiveness of our framework in both simulation and real-world settings. Our code is available at https://github.com/THU-VCLab/Part-Guided-3D-RL-for-Sim2Real-Articulated-Object-Manipulation.
Create account to get full access
Overview
- Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots.
- Existing learning-based solutions focus on visual affordance learning or pre-trained visual models, which face challenges for novel instances in real-world scenarios.
- The paper proposes a novel part-guided 3D Reinforcement Learning (RL) framework to learn manipulation policies for articulated objects without demonstrations.
Plain English Explanation
The paper addresses the challenge of getting robots to manipulate and interact with objects they haven't seen before, particularly objects with movable parts like hinges or joints (called "articulated objects"). Existing AI systems for this task often rely on pre-trained visual models or learning about "affordances" (what actions can be performed on an object), but these can struggle with completely novel objects.
The key idea in this paper is to combine 2D object segmentation (identifying the different parts of an object) with 3D reinforcement learning (learning through trial-and-error how to manipulate the object). This part-guided 3D RL framework allows the system to learn manipulation policies without needing demonstration data.
To make the learned policies more stable and reliable when applied to real robots, the authors also develop a "Frame-consistent Uncertainty-aware Sampling" strategy. This helps the system build a more robust 3D understanding of the object being manipulated.
Importantly, the system can learn a single versatile policy that works across multiple different articulated object manipulation tasks, rather than needing to train a separate policy for each task. This generalizability is a key benefit.
Technical Explanation
The core of the proposed framework is a combination of 2D segmentation and 3D reinforcement learning. First, the system uses a 2D segmentation model to identify the different parts of the articulated object. This part-level information is then used to guide the 3D RL policy training.
Specifically, the system learns a policy that can manipulate the object by reasoning about its parts and their relationships in 3D space. This part-guided approach improves the efficiency and effectiveness of the RL training compared to standard 3D RL.
To make the learned policies more stable and suitable for real-world deployment, the authors develop a "Frame-consistent Uncertainty-aware Sampling" (FUS) strategy. This selects a condensed and hierarchical 3D representation of the object that is more robust to changes in viewpoint and noise.
The system is trained entirely in simulation, but is shown to generalize well to novel object categories and instances in real-world experiments. A key benefit is that a single versatile RL policy can be trained to handle multiple different articulated object manipulation tasks, rather than needing separate policies.
Critical Analysis
The paper presents a compelling approach to the challenging problem of manipulating unseen articulated objects. The combination of 2D segmentation and 3D RL is a novel and promising direction, and the FUS strategy helps address the stability issues that often plague RL-based robotic manipulation.
That said, the paper does not fully address the sample efficiency of the RL training, which is a common limitation of such approaches. The reliance on simulation-to-real-world transfer also means the system may struggle with the complexities of the true physical world, such as subtle object dynamics, sensor noise, and imperfect actuation.
Additionally, the paper does not explore the system's ability to handle significant changes in object structure or morphology. The generalization claims are limited to novel instances within the same broad object categories.
Further research could investigate ways to make the RL training more sample-efficient, perhaps by integrating uncertainty-aware active learning or leveraging agent-agnostic imitation learning. Exploring the system's robustness to more substantial changes in object structure would also be valuable.
Conclusion
This paper presents a novel part-guided 3D RL framework for manipulating unseen articulated objects. By combining 2D segmentation and 3D RL, the system can learn versatile manipulation policies without needing demonstration data. The proposed FUS strategy helps ensure the policies are stable and suitable for real-world deployment.
While the paper demonstrates promising results, there are still opportunities to improve the sample efficiency of the RL training and expand the system's ability to handle more substantial changes in object structure. Overall, this work represents an important step forward in the challenging domain of robotic manipulation of complex, previously unseen objects.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Cognitive Manipulation: Semi-supervised Visual Representation and Classroom-to-real Reinforcement Learning for Assembly in Semi-structured Environments
Chuang Wang, Lie Yang, Ze Lin, Yizhi Liao, Gang Chen, Longhan Xie
0
0
Assembling a slave object into a fixture-free master object represents a critical challenge in flexible manufacturing. Existing deep reinforcement learning-based methods, while benefiting from visual or operational priors, often struggle with small-batch precise assembly tasks due to their reliance on insufficient priors and high-costed model development. To address these limitations, this paper introduces a cognitive manipulation and learning approach that utilizes skill graphs to integrate learning-based object detection with fine manipulation models into a cohesive modular policy. This approach enables the detection of the master object from both global and local perspectives to accommodate positional uncertainties and variable backgrounds, and parametric residual policy to handle pose error and intricate contact dynamics effectively. Leveraging the skill graph, our method supports knowledge-informed learning of semi-supervised learning for object detection and classroom-to-real reinforcement learning for fine manipulation. Simulation experiments on a gear-assembly task have demonstrated that the skill-graph-enabled coarse-operation planning and visual attention are essential for efficient learning and robust manipulation, showing substantial improvements of 13$%$ in success rate and 15.4$%$ in number of completion steps over competing methods. Real-world experiments further validate that our system is highly effective for robotic assembly in semi-structured environments.
6/4/2024
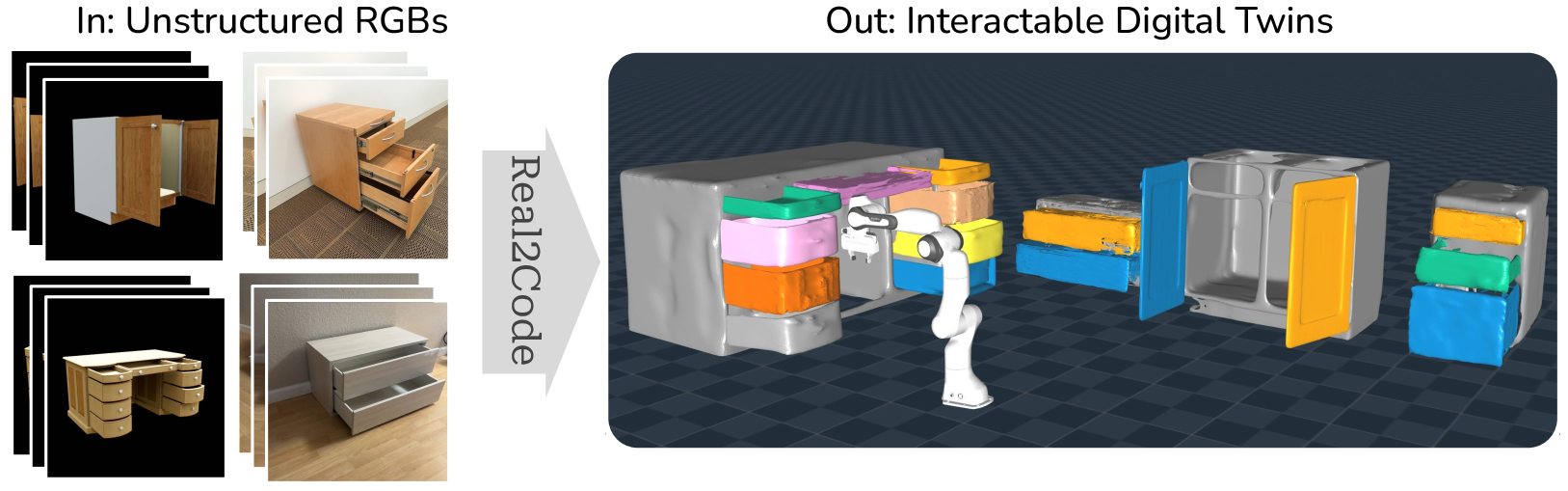
Real2Code: Reconstruct Articulated Objects via Code Generation
Zhao Mandi, Yijia Weng, Dominik Bauer, Shuran Song
0
0
We present Real2Code, a novel approach to reconstructing articulated objects via code generation. Given visual observations of an object, we first reconstruct its part geometry using an image segmentation model and a shape completion model. We then represent the object parts with oriented bounding boxes, which are input to a fine-tuned large language model (LLM) to predict joint articulation as code. By leveraging pre-trained vision and language models, our approach scales elegantly with the number of articulated parts, and generalizes from synthetic training data to real world objects in unstructured environments. Experimental results demonstrate that Real2Code significantly outperforms previous state-of-the-art in reconstruction accuracy, and is the first approach to extrapolate beyond objects' structural complexity in the training set, and reconstructs objects with up to 10 articulated parts. When incorporated with a stereo reconstruction model, Real2Code also generalizes to real world objects from a handful of multi-view RGB images, without the need for depth or camera information.
6/14/2024
🔄
Sim-To-Real Transfer for Visual Reinforcement Learning of Deformable Object Manipulation for Robot-Assisted Surgery
Paul Maria Scheikl, Eleonora Tagliabue, Bal'azs Gyenes, Martin Wagner, Diego Dall'Alba, Paolo Fiorini, Franziska Mathis-Ullrich
0
0
Automation holds the potential to assist surgeons in robotic interventions, shifting their mental work load from visuomotor control to high level decision making. Reinforcement learning has shown promising results in learning complex visuomotor policies, especially in simulation environments where many samples can be collected at low cost. A core challenge is learning policies in simulation that can be deployed in the real world, thereby overcoming the sim-to-real gap. In this work, we bridge the visual sim-to-real gap with an image-based reinforcement learning pipeline based on pixel-level domain adaptation and demonstrate its effectiveness on an image-based task in deformable object manipulation. We choose a tissue retraction task because of its importance in clinical reality of precise cancer surgery. After training in simulation on domain-translated images, our policy requires no retraining to perform tissue retraction with a 50% success rate on the real robotic system using raw RGB images. Furthermore, our sim-to-real transfer method makes no assumptions on the task itself and requires no paired images. This work introduces the first successful application of visual sim-to-real transfer for robotic manipulation of deformable objects in the surgical field, which represents a notable step towards the clinical translation of cognitive surgical robotics.
6/11/2024

New!Language-Guided Object-Centric Diffusion Policy for Collision-Aware Robotic Manipulation
Hang Li, Qian Feng, Zhi Zheng, Jianxiang Feng, Alois Knoll
0
0
Learning from demonstrations faces challenges in generalizing beyond the training data and is fragile even to slight visual variations. To tackle this problem, we introduce Lan-o3dp, a language guided object centric diffusion policy that takes 3d representation of task relevant objects as conditional input and can be guided by cost function for safety constraints at inference time. Lan-o3dp enables strong generalization in various aspects, such as background changes, visual ambiguity and can avoid novel obstacles that are unseen during the demonstration process. Specifically, We first train a diffusion policy conditioned on point clouds of target objects and then harness a large language model to decompose the user instruction into task related units consisting of target objects and obstacles, which can be used as visual observation for the policy network or converted to a cost function, guiding the generation of trajectory towards collision free region at test time. Our proposed method shows training efficiency and higher success rates compared with the baselines in simulation experiments. In real world experiments, our method exhibits strong generalization performance towards unseen instances, cluttered scenes, scenes of multiple similar objects and demonstrates training free capability of obstacle avoidance.
7/2/2024