MarvelOVD: Marrying Object Recognition and Vision-Language Models for Robust Open-Vocabulary Object Detection

0

Sign in to get full access
Overview
- Presents a new model called MarvelOVD that combines object recognition and vision-language models for robust open-vocabulary object detection
- Utilizes pseudo-labeling and collaborative inference to enable effective open-vocabulary object detection
- Outperforms state-of-the-art open-vocabulary object detection methods on benchmarks
Plain English Explanation
MarvelOVD: Marrying Object Recognition and Vision-Language Models for Robust Open-Vocabulary Object Detection is a research paper that introduces a new model for detecting objects in images using an "open vocabulary" - meaning the model can recognize a wide range of objects, not just a fixed set.
The key idea is to marry two types of AI models:
- Object recognition models that are good at detecting specific objects
- Vision-language models that can understand the meaning of words and link them to visual concepts
By combining these two approaches, the MarvelOVD model can detect a much broader range of objects than previous methods. It does this through techniques like pseudo-labeling and collaborative inference, which allow the model to learn and recognize new objects effectively.
The researchers show that MarvelOVD outperforms other state-of-the-art open-vocabulary object detection methods on benchmark datasets. This suggests it could be a powerful tool for real-world applications that require detecting a wide variety of objects, like self-driving cars, robotics, and image search.
Technical Explanation
The paper first reviews prior work on open-vocabulary object detection, which aims to enable object detection models to recognize a large, open-ended set of objects rather than a fixed vocabulary.
The key innovations in MarvelOVD are:
-
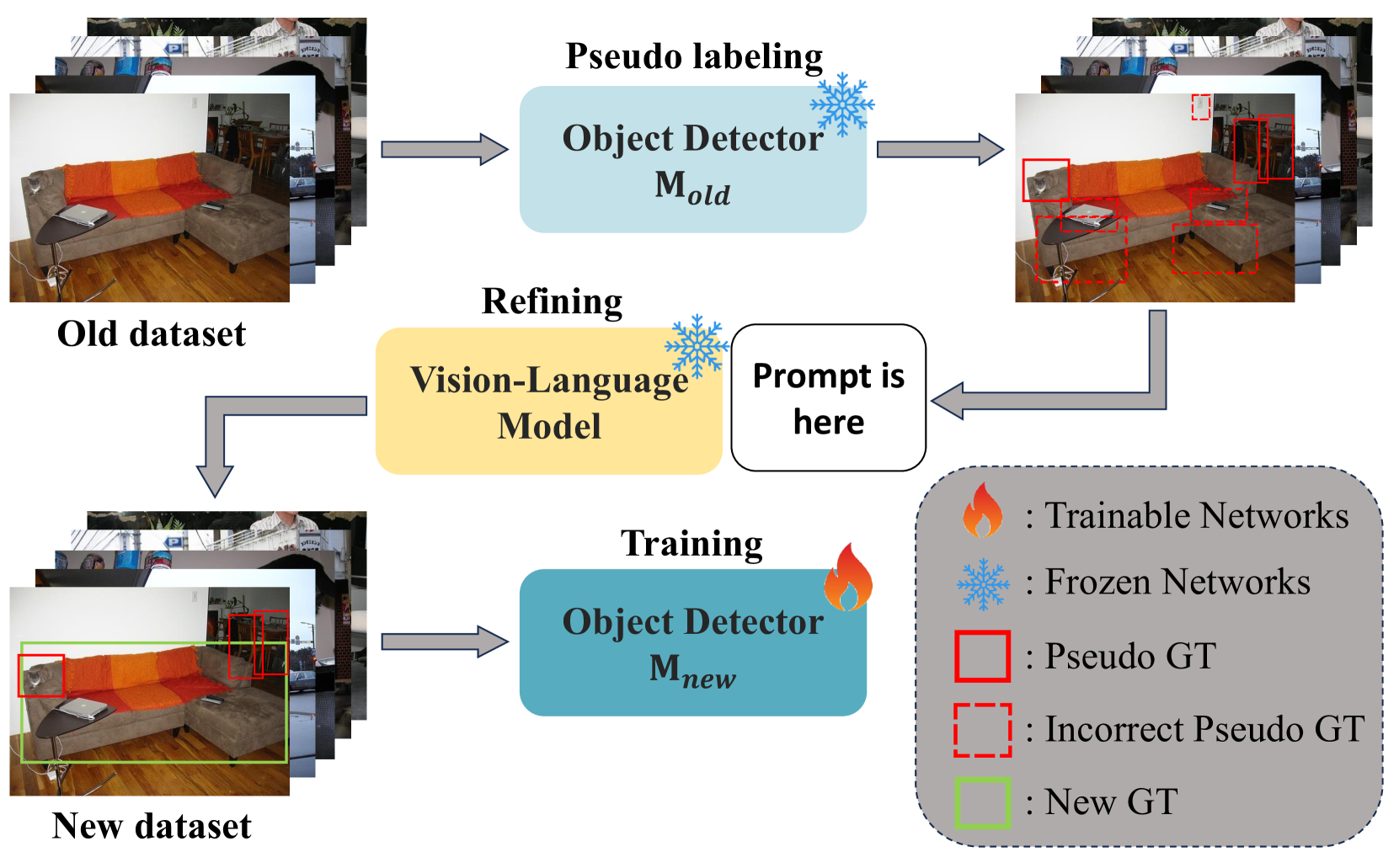
Pseudo-Labeling: The model uses a vision-language model to generate pseudo-labels for objects that are not seen during training. This allows the object detection model to learn to recognize a much broader range of objects.
-
Collaborative Inference: During inference, the object detection and vision-language models work together, with the vision-language model providing guidance to the object detector to improve its performance on open-vocabulary objects.
The paper presents extensive experiments evaluating MarvelOVD on benchmark datasets. The results show that it outperforms previous state-of-the-art open-vocabulary object detection methods by a significant margin.
Critical Analysis
The paper provides a thorough technical explanation of the MarvelOVD model and demonstrates its strong performance. However, it does not discuss any notable limitations or caveats of the approach.
For example, the paper does not address how well the model would generalize to truly novel objects that are very different from the training data. The collaborative inference process may struggle if the vision-language model makes mistakes in its guidance.
Additionally, the computational cost and runtime of the joint object detection and vision-language model inference is not analyzed. This could be an important practical consideration for real-world deployment.
Overall, the research appears technically sound, but further analysis of the model's limitations and robustness would strengthen the critical evaluation.
Conclusion
This paper presents a novel approach called MarvelOVD that combines object recognition and vision-language models to enable robust open-vocabulary object detection. The key innovations of pseudo-labeling and collaborative inference allow the model to recognize a much broader range of objects than previous methods.
The experimental results demonstrate the effectiveness of the MarvelOVD approach, which outperforms state-of-the-art open-vocabulary object detection techniques. This suggests the model could be a valuable tool for real-world applications that require detecting a wide variety of objects, such as self-driving cars, robotic systems, and image search.
While the paper provides a strong technical foundation, further analysis of the model's limitations and robustness would strengthen the critical evaluation. Overall, the research represents an important advance in the field of open-vocabulary object detection with promising practical implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MarvelOVD: Marrying Object Recognition and Vision-Language Models for Robust Open-Vocabulary Object Detection
Kuo Wang, Lechao Cheng, Weikai Chen, Pingping Zhang, Liang Lin, Fan Zhou, Guanbin Li
Learning from pseudo-labels that generated with VLMs~(Vision Language Models) has been shown as a promising solution to assist open vocabulary detection (OVD) in recent studies. However, due to the domain gap between VLM and vision-detection tasks, pseudo-labels produced by the VLMs are prone to be noisy, while the training design of the detector further amplifies the bias. In this work, we investigate the root cause of VLMs' biased prediction under the OVD context. Our observations lead to a simple yet effective paradigm, coded MarvelOVD, that generates significantly better training targets and optimizes the learning procedure in an online manner by marrying the capability of the detector with the vision-language model. Our key insight is that the detector itself can act as a strong auxiliary guidance to accommodate VLM's inability of understanding both the ``background'' and the context of a proposal within the image. Based on it, we greatly purify the noisy pseudo-labels via Online Mining and propose Adaptive Reweighting to effectively suppress the biased training boxes that are not well aligned with the target object. In addition, we also identify a neglected ``base-novel-conflict'' problem and introduce stratified label assignments to prevent it. Extensive experiments on COCO and LVIS datasets demonstrate that our method outperforms the other state-of-the-arts by significant margins. Codes are available at https://github.com/wkfdb/MarvelOVD
Read more8/1/2024
0
VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model
Junsu Kim, Yunhoe Ku, Jihyeon Kim, Junuk Cha, Seungryul Baek
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
Read more5/10/2024
0
The Solution for CVPR2024 Foundational Few-Shot Object Detection Challenge
Hongpeng Pan, Shifeng Yi, Shouwei Yang, Lei Qi, Bing Hu, Yi Xu, Yang Yang
This report introduces an enhanced method for the Foundational Few-Shot Object Detection (FSOD) task, leveraging the vision-language model (VLM) for object detection. However, on specific datasets, VLM may encounter the problem where the detected targets are misaligned with the target concepts of interest. This misalignment hinders the zero-shot performance of VLM and the application of fine-tuning methods based on pseudo-labels. To address this issue, we propose the VLM+ framework, which integrates the multimodal large language model (MM-LLM). Specifically, we use MM-LLM to generate a series of referential expressions for each category. Based on the VLM predictions and the given annotations, we select the best referential expression for each category by matching the maximum IoU. Subsequently, we use these referential expressions to generate pseudo-labels for all images in the training set and then combine them with the original labeled data to fine-tune the VLM. Additionally, we employ iterative pseudo-label generation and optimization to further enhance the performance of the VLM. Our approach achieve 32.56 mAP in the final test.
Read more6/19/2024
🔎
0
LP-OVOD: Open-Vocabulary Object Detection by Linear Probing
Chau Pham, Truong Vu, Khoi Nguyen
This paper addresses the challenging problem of open-vocabulary object detection (OVOD) where an object detector must identify both seen and unseen classes in test images without labeled examples of the unseen classes in training. A typical approach for OVOD is to use joint text-image embeddings of CLIP to assign box proposals to their closest text label. However, this method has a critical issue: many low-quality boxes, such as over- and under-covered-object boxes, have the same similarity score as high-quality boxes since CLIP is not trained on exact object location information. To address this issue, we propose a novel method, LP-OVOD, that discards low-quality boxes by training a sigmoid linear classifier on pseudo labels retrieved from the top relevant region proposals to the novel text. Experimental results on COCO affirm the superior performance of our approach over the state of the art, achieving $textbf{40.5}$ in $text{AP}_{novel}$ using ResNet50 as the backbone and without external datasets or knowing novel classes during training. Our code will be available at https://github.com/VinAIResearch/LP-OVOD.
Read more6/4/2024