LP-OVOD: Open-Vocabulary Object Detection by Linear Probing

0
🔎
Sign in to get full access
Overview
- This paper addresses the challenge of open-vocabulary object detection (OVOD), where an object detector must identify both seen and unseen classes in test images without labeled examples of the unseen classes in training.
- The typical approach for OVOD is to use joint text-image embeddings from CLIP to assign box proposals to their closest text label.
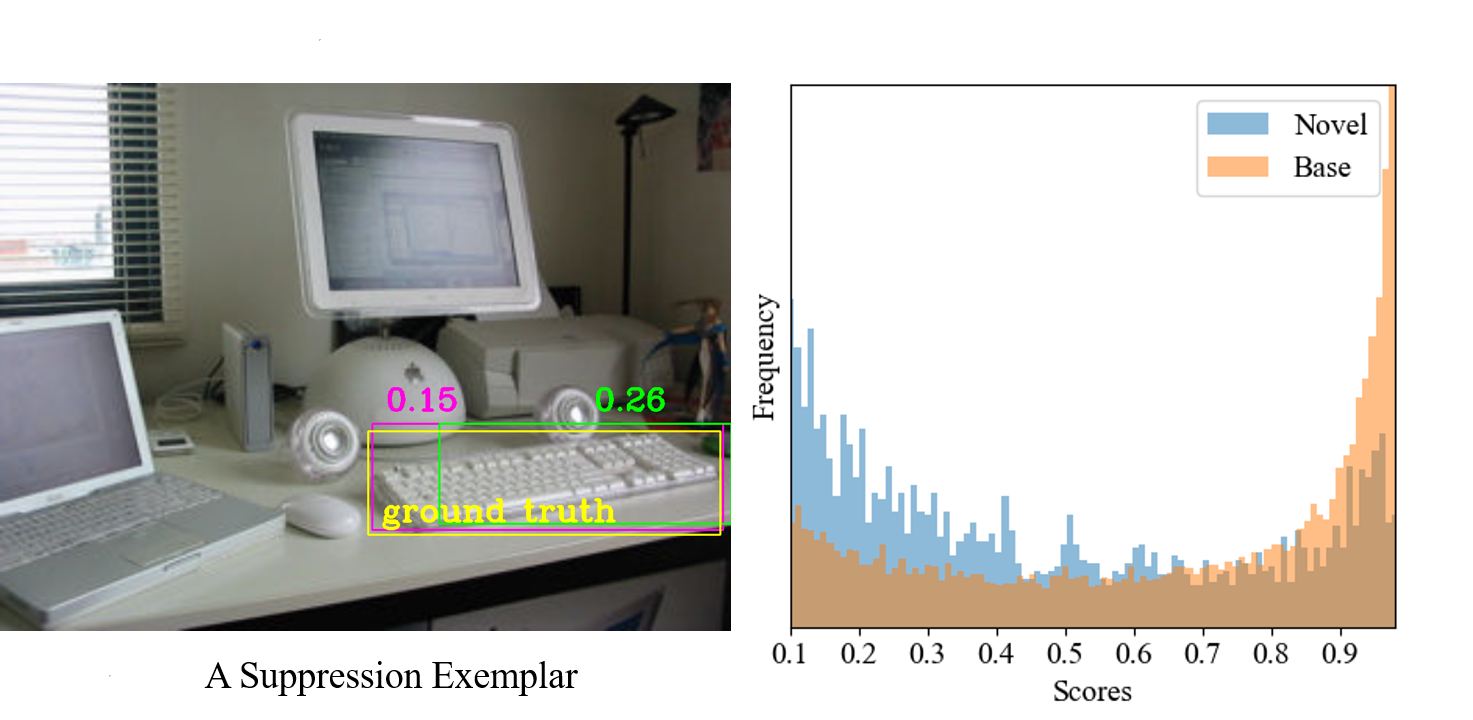
- However, this method has a critical issue: many low-quality boxes, such as over- and under-covered-object boxes, have the same similarity score as high-quality boxes since CLIP is not trained on exact object location information.
- To address this issue, the authors propose a novel method called LP-OVOD that discards low-quality boxes by training a sigmoid linear classifier on pseudo labels retrieved from the top relevant region proposals to the novel text.
Plain English Explanation
Object detectors are computer vision models that can identify and locate objects in images. Typically, these models are trained on a fixed set of object classes, and they can only recognize those classes during inference.
The challenge of open-vocabulary object detection (OVOD) is to create an object detector that can identify both the object classes it was trained on (seen classes) and new, previously unseen object classes (unseen classes) in test images, without having any labeled examples of the unseen classes during training.
A common approach for OVOD is to use a pre-trained CLIP model, which can match image regions to textual descriptions of objects. However, this method has a significant limitation: CLIP doesn't consider the exact location of the objects in the image, so it can't distinguish high-quality object proposals (where the box closely matches the actual object) from low-quality ones (where the box is too big, too small, or doesn't cover the object well).
To address this issue, the researchers propose a new method called LP-OVOD. LP-OVOD trains a special classifier to identify high-quality object proposals by using "pseudo-labels" - information about which region proposals in the training images correspond to the novel object classes. This allows the model to learn to discard low-quality proposals and focus on the high-quality ones, leading to better performance on unseen object classes.
Technical Explanation
The core idea of the proposed LP-OVOD method is to train a sigmoid linear classifier to discard low-quality object proposals by using pseudo-labels derived from the top relevant region proposals to the novel text classes.
The overall LP-OVOD pipeline consists of the following steps:
-
Object Proposal Generation: The model first generates a set of object proposals (bounding boxes) in the input image using a standard object detection backbone (e.g., ResNet50).
-
Text-Image Similarity Scoring: For each object proposal, the model computes its similarity score to the text descriptions of all object classes (both seen and unseen) using a pre-trained CLIP model.
-
Pseudo-Label Generation: The model selects the top-k object proposals that have the highest similarity scores to the novel text classes and uses them to generate pseudo-labels. These pseudo-labels indicate whether each proposal is a high-quality (positive) or low-quality (negative) detection of a novel object.
-
Classifier Training: The model then trains a sigmoid linear classifier to predict whether a given object proposal is a high-quality detection of a novel object, using the pseudo-labels as the training signal.
-
Novel Object Detection: During inference, the model first generates object proposals and computes their text-image similarity scores. It then uses the trained sigmoid linear classifier to filter out low-quality proposals, keeping only the high-quality ones as the final object detections.
The key insight behind this approach is that by training the classifier to distinguish high-quality from low-quality proposals for novel classes, the model can effectively discard the many low-quality boxes that would otherwise be assigned to novel classes by the CLIP-based similarity scoring alone.
Experimental results on the COCO dataset show that LP-OVOD significantly outperforms the state-of-the-art CLIP-based OVOD methods, achieving an AP_novel of 40.5 using a ResNet50 backbone, without requiring any external datasets or knowledge of the novel classes during training.
Critical Analysis
The authors acknowledge several limitations of the LP-OVOD approach:
-
Dependence on Pseudo-Labels: The performance of LP-OVOD relies heavily on the quality of the pseudo-labels used to train the proposal classifier. If the pseudo-labels contain errors or biases, this could negatively impact the model's ability to accurately distinguish high-quality from low-quality proposals.
-
Computational Overhead: The additional step of training the proposal classifier adds computational overhead to the OVOD pipeline, which could make it less efficient than simpler CLIP-based approaches.
-
Generalization to Novel Classes: While LP-OVOD shows strong performance on the COCO dataset, it's unclear how well the approach would generalize to datasets with very different or more diverse novel object classes.
Additionally, the paper does not address some potential issues, such as:
- Sensitivity to Proposal Generation: The performance of LP-OVOD could be sensitive to the quality and diversity of the initial object proposals generated by the backbone model.
- Scalability to Large-Scale OVOD: The paper only evaluates LP-OVOD on a relatively small-scale OVOD task (COCO). Scaling the approach to large-scale OVOD datasets with hundreds or thousands of novel classes may present additional challenges.
Overall, the LP-OVOD method represents an interesting and promising approach to addressing the OVOD challenge, but further research may be needed to fully understand its limitations and potential for real-world applications.
Conclusion
This paper presents a novel approach called LP-OVOD for open-vocabulary object detection (OVOD), which aims to address a critical limitation of existing CLIP-based OVOD methods. By training a sigmoid linear classifier to discard low-quality object proposals, LP-OVOD is able to significantly improve performance on novel object classes compared to the state of the art.
The key innovation of LP-OVOD is its use of pseudo-labels to guide the training of the proposal classifier, allowing the model to learn to focus on high-quality detections of unseen objects. This approach demonstrates the potential for incorporating additional task-specific training signals to enhance the capabilities of pre-trained vision-language models like CLIP for complex computer vision tasks.
While LP-OVOD shows promising results, the authors acknowledge several limitations that warrant further investigation, such as the reliance on accurate pseudo-labels and the potential for scalability issues. Nonetheless, this work represents an important step forward in the field of open-class incremental object detection, and it could inspire future research on improving open-vocabulary object detection through the integration of specialized training components.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
LP-OVOD: Open-Vocabulary Object Detection by Linear Probing
Chau Pham, Truong Vu, Khoi Nguyen
This paper addresses the challenging problem of open-vocabulary object detection (OVOD) where an object detector must identify both seen and unseen classes in test images without labeled examples of the unseen classes in training. A typical approach for OVOD is to use joint text-image embeddings of CLIP to assign box proposals to their closest text label. However, this method has a critical issue: many low-quality boxes, such as over- and under-covered-object boxes, have the same similarity score as high-quality boxes since CLIP is not trained on exact object location information. To address this issue, we propose a novel method, LP-OVOD, that discards low-quality boxes by training a sigmoid linear classifier on pseudo labels retrieved from the top relevant region proposals to the novel text. Experimental results on COCO affirm the superior performance of our approach over the state of the art, achieving $textbf{40.5}$ in $text{AP}_{novel}$ using ResNet50 as the backbone and without external datasets or knowing novel classes during training. Our code will be available at https://github.com/VinAIResearch/LP-OVOD.
Read more6/4/2024
0
Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation
Yanhao Zheng, Kai Liu
Open-vocabulary object detection (OVOD) aims at localizing and recognizing visual objects from novel classes unseen at the training time. Whereas, empirical studies reveal that advanced detectors generally assign lower scores to those novel instances, which are inadvertently suppressed during inference by commonly adopted greedy strategies like Non-Maximum Suppression (NMS), leading to sub-optimal detection performance for novel classes. This paper systematically investigates this problem with the commonly-adopted two-stage OVOD paradigm. Specifically, in the region-proposal stage, proposals that contain novel instances showcase lower objectness scores, since they are treated as background proposals during the training phase. Meanwhile, in the object-classification stage, novel objects share lower region-text similarities (i.e., classification scores) due to the biased visual-language alignment by seen training samples. To alleviate this problem, this paper introduces two advanced measures to adjust confidence scores and conserve erroneously dismissed objects: (1) a class-agnostic localization quality estimate via overlap degree of region/object proposals, and (2) a text-guided visual similarity estimate with proxy prototypes for novel classes. Integrated with adjusting techniques specifically designed for the region-proposal and object-classification stages, this paper derives the aggregated confidence estimate for the open-vocabulary object detection paradigm (AggDet). Our AggDet is a generic and training-free post-processing scheme, which consistently bolsters open-vocabulary detectors across model scales and architecture designs. For instance, AggDet receives 3.3% and 1.5% gains on OV-COCO and OV-LVIS benchmarks respectively, without any training cost.
Read more4/15/2024
🔎
0
Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Yan Li, Weiwei Guo, Xue Yang, Ning Liao, Dunyun He, Jiaqi Zhou, Wenxian Yu
An increasingly massive number of remote-sensing images spurs the development of extensible object detectors that can detect objects beyond training categories without costly collecting new labeled data. In this paper, we aim to develop open-vocabulary object detection (OVD) technique in aerial images that scales up object vocabulary size beyond training data. The performance of OVD greatly relies on the quality of class-agnostic region proposals and pseudo-labels for novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework following the student-teacher self-learning mechanism employs the RemoteCLIP model as an extra omniscient teacher with rich knowledge. By doing so, our approach boosts not only novel object proposals but also classification. Furthermore, we devise a dynamic label queue strategy to maintain high-quality pseudo labels during batch training. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 46.5% mAP on VisDroneZSD novel categories, which outperforms the state-of-the-art open-vocabulary detectors by 21.0% mAP. To our best knowledge, this is the first work to apply and develop the open-vocabulary object detection technique for aerial images. The code is available at https://github.com/lizzy8587/CastDet.
Read more8/13/2024

0
MarvelOVD: Marrying Object Recognition and Vision-Language Models for Robust Open-Vocabulary Object Detection
Kuo Wang, Lechao Cheng, Weikai Chen, Pingping Zhang, Liang Lin, Fan Zhou, Guanbin Li
Learning from pseudo-labels that generated with VLMs~(Vision Language Models) has been shown as a promising solution to assist open vocabulary detection (OVD) in recent studies. However, due to the domain gap between VLM and vision-detection tasks, pseudo-labels produced by the VLMs are prone to be noisy, while the training design of the detector further amplifies the bias. In this work, we investigate the root cause of VLMs' biased prediction under the OVD context. Our observations lead to a simple yet effective paradigm, coded MarvelOVD, that generates significantly better training targets and optimizes the learning procedure in an online manner by marrying the capability of the detector with the vision-language model. Our key insight is that the detector itself can act as a strong auxiliary guidance to accommodate VLM's inability of understanding both the ``background'' and the context of a proposal within the image. Based on it, we greatly purify the noisy pseudo-labels via Online Mining and propose Adaptive Reweighting to effectively suppress the biased training boxes that are not well aligned with the target object. In addition, we also identify a neglected ``base-novel-conflict'' problem and introduce stratified label assignments to prevent it. Extensive experiments on COCO and LVIS datasets demonstrate that our method outperforms the other state-of-the-arts by significant margins. Codes are available at https://github.com/wkfdb/MarvelOVD
Read more8/1/2024