Mask-Encoded Sparsification: Mitigating Biased Gradients in Communication-Efficient Split Learning

0

Sign in to get full access
Overview
- Mask-Encoded Sparsification is a method to mitigate biased gradients in communication-efficient split learning
- Split learning is a technique where a machine learning model is split between a client and a server to reduce communication costs
- Biased gradients can occur in split learning and lead to suboptimal model performance
- Mask-Encoded Sparsification addresses this issue by selectively transmitting important gradient information
Plain English Explanation
In machine learning, there is often a trade-off between the accuracy of a model and the amount of data and computation required to train it. Split learning is a technique that tries to address this by dividing the model between a client device and a server. This can reduce the amount of data and computation needed on the client side, which is important for applications like mobile devices or embedded systems.
However, split learning can lead to biased gradients, which means the updates to the model may not be as effective as they could be. This is because the client and server are each only seeing a portion of the full model and gradients.
The Mask-Encoded Sparsification technique aims to address this by selectively transmitting the most important gradient information between the client and server. It does this by creating a "mask" that identifies the most significant gradient values, and only transmitting those. This helps to mitigate the biased gradients and improve the overall performance of the split learning model.
Technical Explanation
The key idea behind Mask-Encoded Sparsification is to identify and transmit only the most important gradient information between the client and server in a split learning setup. This is done by creating a binary "mask" that indicates which gradient values are most significant.
The process works as follows:
- The client computes the gradients for its portion of the model.
- The client applies a threshold to the gradients to identify the most important values.
- The client creates a binary mask indicating which gradient values are above the threshold.
- The client transmits the mask and the selected gradient values to the server.
- The server uses the mask to reconstruct the full gradient vector and update its portion of the model.
This selective transmission of gradient information helps to mitigate the issue of biased gradients that can arise in split learning, leading to improved model performance.
The authors evaluate Mask-Encoded Sparsification on several benchmark datasets and tasks, and show that it can achieve comparable accuracy to full model training while significantly reducing the communication costs between the client and server.
Critical Analysis
The Mask-Encoded Sparsification approach seems promising for addressing the challenge of biased gradients in split learning. By selectively transmitting only the most important gradient information, it can help maintain model performance while reducing communication costs.
However, the paper does not explore the potential limitations or drawbacks of this approach in depth. For example, it's unclear how the threshold for selecting important gradients is determined, and whether this could be sensitive to the specific problem or dataset. There may also be cases where the most important gradients are distributed more evenly, making it harder to achieve significant sparsification.
Additionally, the paper focuses primarily on the technical aspects of the approach and does not delve into potential real-world implications or challenges that may arise in deploying such a system. Further research could explore these areas in more depth.
Overall, Mask-Encoded Sparsification appears to be a promising direction for improving the efficiency of split learning, but more work may be needed to fully understand its limitations and potential broader impacts.
Conclusion
Mask-Encoded Sparsification is a technique that aims to mitigate the issue of biased gradients in communication-efficient split learning. By selectively transmitting only the most important gradient information between the client and server, it can maintain model performance while reducing the communication costs.
The approach shows promising results in the authors' experiments, but there may be limitations or potential challenges that warrant further exploration. Nonetheless, Mask-Encoded Sparsification represents an interesting advancement in the field of split learning and could have important implications for the development of efficient and effective machine learning systems, especially in resource-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mask-Encoded Sparsification: Mitigating Biased Gradients in Communication-Efficient Split Learning
Wenxuan Zhou, Zhihao Qu, Shen-Huan Lyu, Miao Cai, Baoliu Ye
This paper introduces a novel framework designed to achieve a high compression ratio in Split Learning (SL) scenarios where resource-constrained devices are involved in large-scale model training. Our investigations demonstrate that compressing feature maps within SL leads to biased gradients that can negatively impact the convergence rates and diminish the generalization capabilities of the resulting models. Our theoretical analysis provides insights into how compression errors critically hinder SL performance, which previous methodologies underestimate. To address these challenges, we employ a narrow bit-width encoded mask to compensate for the sparsification error without increasing the order of time complexity. Supported by rigorous theoretical analysis, our framework significantly reduces compression errors and accelerates the convergence. Extensive experiments also verify that our method outperforms existing solutions regarding training efficiency and communication complexity.
Read more9/19/2024
💬
0
Mask in the Mirror: Implicit Sparsification
Tom Jacobs, Rebekka Burkholz
Sparsifying deep neural networks to reduce their inference cost is an NP-hard problem and difficult to optimize due to its mixed discrete and continuous nature. Yet, as we prove, continuous sparsification has already an implicit bias towards sparsity that would not require common projections of relaxed mask variables. While implicit rather than explicit regularization induces benefits, it usually does not provide enough flexibility in practice, as only a specific target sparsity is obtainable. To exploit its potential for continuous sparsification, we propose a way to control the strength of the implicit bias. Based on the mirror flow framework, we derive resulting convergence and optimality guarantees in the context of underdetermined linear regression and demonstrate the utility of our insights in more general neural network sparsification experiments, achieving significant performance gains, particularly in the high-sparsity regime. Our theoretical contribution might be of independent interest, as we highlight a way to enter the rich regime and show that implicit bias is controllable by a time-dependent Bregman potential.
Read more8/20/2024
🗣️
1
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?
Yaodong Yu, Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Hao Bai, Yuexiang Zhai, Benjamin D. Haeffele, Yi Ma
In this paper, we contend that a natural objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a low-dimensional Gaussian mixture supported on incoherent subspaces. The goodness of such a representation can be evaluated by a principled measure, called sparse rate reduction, that simultaneously maximizes the intrinsic information gain and extrinsic sparsity of the learned representation. From this perspective, popular deep network architectures, including transformers, can be viewed as realizing iterative schemes to optimize this measure. Particularly, we derive a transformer block from alternating optimization on parts of this objective: the multi-head self-attention operator compresses the representation by implementing an approximate gradient descent step on the coding rate of the features, and the subsequent multi-layer perceptron sparsifies the features. This leads to a family of white-box transformer-like deep network architectures, named CRATE, which are mathematically fully interpretable. We show, by way of a novel connection between denoising and compression, that the inverse to the aforementioned compressive encoding can be realized by the same class of CRATE architectures. Thus, the so-derived white-box architectures are universal to both encoders and decoders. Experiments show that these networks, despite their simplicity, indeed learn to compress and sparsify representations of large-scale real-world image and text datasets, and achieve performance very close to highly engineered transformer-based models: ViT, MAE, DINO, BERT, and GPT2. We believe the proposed computational framework demonstrates great potential in bridging the gap between theory and practice of deep learning, from a unified perspective of data compression. Code is available at: https://ma-lab-berkeley.github.io/CRATE .
Read more9/9/2024
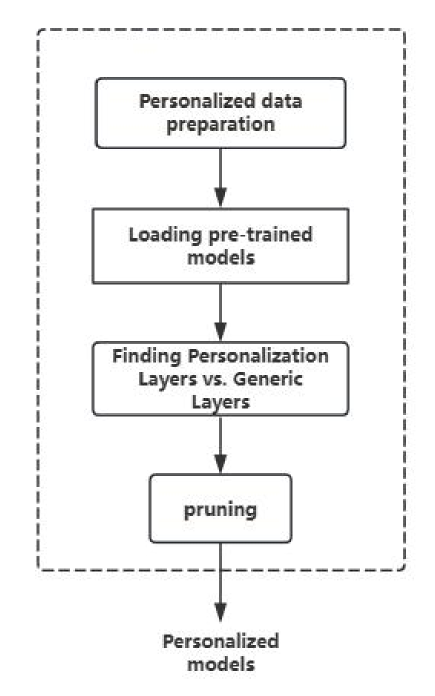
0
Research on Personalized Compression Algorithm for Pre-trained Models Based on Homomorphic Entropy Increase
Yicong Li, Xing Guo, Haohua Du
In this article, we explore the challenges and evolution of two key technologies in the current field of AI: Vision Transformer model and Large Language Model (LLM). Vision Transformer captures global information by splitting images into small pieces and leveraging Transformer's multi-head attention mechanism, but its high reference count and compute overhead limit deployment on mobile devices. At the same time, the rapid development of LLM has revolutionized natural language processing, but it also faces huge deployment challenges. To address these issues, we investigate model pruning techniques, with a particular focus on how to reduce redundant parameters without losing accuracy to accommodate personalized data and resource-constrained environments. In this paper, a new layered pruning strategy is proposed to distinguish the personalized layer from the common layer by compressed sensing and random sampling, thus significantly reducing the model parameters. Our experimental results show that the introduced step buffering mechanism further improves the accuracy of the model after pruning, providing new directions and possibilities for the deployment of efficient and personalized AI models on mobile devices in the future.
Read more8/19/2024