Research on Personalized Compression Algorithm for Pre-trained Models Based on Homomorphic Entropy Increase

0
Sign in to get full access
Overview
- Presents a personalized compression algorithm for pre-trained language models based on homomorphic entropy increase
- Aims to compress models while preserving their performance on downstream tasks
- Focuses on Vision Transformer (ViT) and large language models (LLMs) as case studies
Plain English Explanation
The research paper introduces a new method for compressing pre-trained machine learning models, such as Vision Transformer (ViT) and large language models (LLMs), in a way that preserves their performance on various tasks.
The key idea is to use an approach called "homomorphic entropy increase" to personalize the compression for each individual model. This means the compression is tailored to the specific patterns and structure of the model, rather than using a one-size-fits-all approach.
By compressing the models in this personalized way, the researchers are able to reduce the file size and memory usage of the models without significantly impacting their accuracy on downstream tasks like language understanding or image recognition. This could make it easier to deploy these powerful AI models on devices with limited resources, such as smartphones or embedded systems.
Technical Explanation
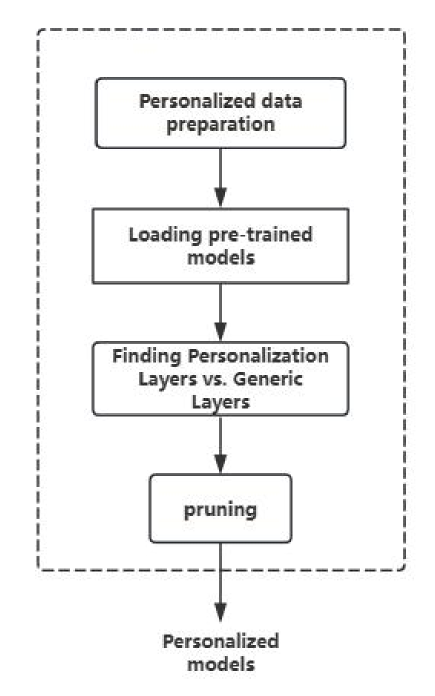
The researchers propose a personalized compression algorithm that leverages the concept of homomorphic entropy increase. The algorithm works by identifying the most important parameters in a pre-trained model and selectively compressing them in a way that preserves the overall model performance.
The process involves several key steps:
- Model Analysis: The algorithm analyzes the pre-trained model to understand its structure and identify the most critical parameters.
- Personalized Compression: A compression scheme is applied to each parameter based on its importance, using the homomorphic entropy increase principle to preserve the essential information.
- Fine-tuning: The compressed model is fine-tuned on the original training data to further optimize its performance.
The researchers evaluated their approach on both Vision Transformer (ViT) and large language models (LLMs), demonstrating significant compression ratios while maintaining high accuracy on downstream tasks.
Critical Analysis
The paper presents a novel and promising approach to model compression, but it also acknowledges some limitations and areas for further research:
- The compression algorithm is tailored to the specific model architecture, so it may not generalize as well to other types of models.
- The fine-tuning process can be computationally expensive, which may limit the practicality of the approach in some real-world scenarios.
- The paper does not explore the tradeoffs between compression ratio and performance in depth, which could be an important consideration for certain applications.
Additionally, the researchers could have investigated the impact of their compression method on the model's interpretability, robustness, or other important characteristics beyond just accuracy on downstream tasks.
Conclusion
This research introduces a personalized compression algorithm for pre-trained models that leverages homomorphic entropy increase to preserve model performance. By tailoring the compression to the specific structure of each model, the approach achieves significant file size and memory reductions without sacrificing accuracy on a variety of tasks.
While the method has some limitations, it represents an important step forward in the field of model compression and could pave the way for more efficient deployment of powerful AI models, especially in resource-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Research on Personalized Compression Algorithm for Pre-trained Models Based on Homomorphic Entropy Increase
Yicong Li, Xing Guo, Haohua Du
In this article, we explore the challenges and evolution of two key technologies in the current field of AI: Vision Transformer model and Large Language Model (LLM). Vision Transformer captures global information by splitting images into small pieces and leveraging Transformer's multi-head attention mechanism, but its high reference count and compute overhead limit deployment on mobile devices. At the same time, the rapid development of LLM has revolutionized natural language processing, but it also faces huge deployment challenges. To address these issues, we investigate model pruning techniques, with a particular focus on how to reduce redundant parameters without losing accuracy to accommodate personalized data and resource-constrained environments. In this paper, a new layered pruning strategy is proposed to distinguish the personalized layer from the common layer by compressed sensing and random sampling, thus significantly reducing the model parameters. Our experimental results show that the introduced step buffering mechanism further improves the accuracy of the model after pruning, providing new directions and possibilities for the deployment of efficient and personalized AI models on mobile devices in the future.
Read more8/19/2024

0
Comprehensive Study on Performance Evaluation and Optimization of Model Compression: Bridging Traditional Deep Learning and Large Language Models
Aayush Saxena, Arit Kumar Bishwas, Ayush Ashok Mishra, Ryan Armstrong
Deep learning models have achieved tremendous success in most of the industries in recent years. The evolution of these models has also led to an increase in the model size and energy requirement, making it difficult to deploy in production on low compute devices. An increase in the number of connected devices around the world warrants compressed models that can be easily deployed at the local devices with low compute capacity and power accessibility. A wide range of solutions have been proposed by different researchers to reduce the size and complexity of such models, prominent among them are, Weight Quantization, Parameter Pruning, Network Pruning, low-rank representation, weights sharing, neural architecture search, knowledge distillation etc. In this research work, we investigate the performance impacts on various trained deep learning models, compressed using quantization and pruning techniques. We implemented both, quantization and pruning, compression techniques on popular deep learning models used in the image classification, object detection, language models and generative models-based problem statements. We also explored performance of various large language models (LLMs) after quantization and low rank adaptation. We used the standard evaluation metrics (model's size, accuracy, and inference time) for all the related problem statements and concluded this paper by discussing the challenges and future work.
Read more7/24/2024
4
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
Read more4/9/2024
📈
0
A Survey on Model Compression for Large Language Models
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang
Large Language Models (LLMs) have transformed natural language processing tasks successfully. Yet, their large size and high computational needs pose challenges for practical use, especially in resource-limited settings. Model compression has emerged as a key research area to address these challenges. This paper presents a survey of model compression techniques for LLMs. We cover methods like quantization, pruning, and knowledge distillation, highlighting recent advancements. We also discuss benchmarking strategies and evaluation metrics crucial for assessing compressed LLMs. This survey offers valuable insights for researchers and practitioners, aiming to enhance efficiency and real-world applicability of LLMs while laying a foundation for future advancements.
Read more7/31/2024