Masked Video and Body-worn IMU Autoencoder for Egocentric Action Recognition

0
Sign in to get full access
Overview
- This paper proposes a novel framework for egocentric action recognition by combining information from masked video and body-worn inertial measurement units (IMUs).
- The key idea is to train an autoencoder model that can effectively fuse the complementary modalities of video and IMU data to improve the performance of action recognition.
- The proposed approach is evaluated on standard egocentric action recognition datasets and shows improvements over state-of-the-art methods.
Plain English Explanation
The paper describes a new way to recognize actions in first-person or "egocentric" videos, which are videos recorded from the perspective of the person doing the actions. Instead of just using the video information, the researchers combine the video with data from sensors called inertial measurement units (IMUs) that are worn on the body.
The researchers train a type of neural network called an autoencoder to learn how to combine the video and IMU data effectively. The autoencoder is trained to take in the video and IMU data, hide or "mask" part of the video information, and then try to reconstruct the full video. By learning this reconstruction task, the autoencoder discovers how to best use the IMU data to complement the video data and improve action recognition.
The key insight is that the IMU data, which measures the movement and orientation of the body, can provide additional useful information beyond just the video. By training the model to fuse these two modalities, the researchers are able to achieve better performance on standard benchmarks for recognizing actions in egocentric videos, compared to using just the video alone or other state-of-the-art methods.
Technical Explanation
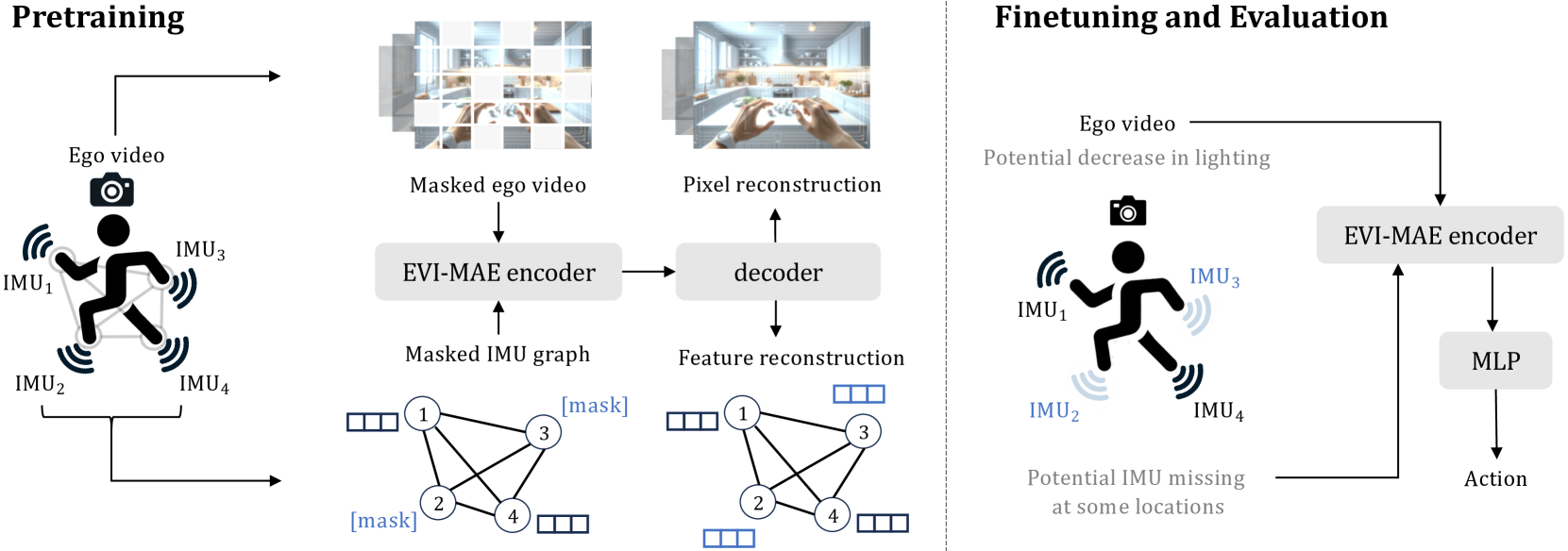
The paper proposes a Masked Video and Body-worn IMU Autoencoder (MVBIA) framework for egocentric action recognition. The core idea is to train an autoencoder model that can effectively fuse information from masked video and body-worn IMU sensors to improve action recognition performance.
The autoencoder consists of an encoder that takes in the video and IMU data, and a decoder that tries to reconstruct the original video from the encoded representation. Importantly, the video input to the encoder is partially masked, forcing the model to learn how to leverage the IMU data to compensate for the missing video information.
During training, the autoencoder is optimized to minimize the reconstruction loss between the predicted and original video frames. This encourages the model to discover useful representations that capture the complementary information between the video and IMU modalities.
The authors evaluate their MVBIA framework on standard egocentric action recognition datasets like EGTEA Gaze+ and EPIC-KITCHENS. They demonstrate that the fused video-IMU representations learned by the autoencoder outperform state-of-the-art methods that use video or IMU data alone, as well as other multimodal fusion approaches such as Flow-Fusing and HoIMotion.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the proposed MVBIA framework, exploring different masking strategies and architectural choices. However, there are a few potential limitations and areas for future work:
-
Generalization to other datasets: The evaluation is limited to two egocentric action recognition datasets. It would be important to test the framework on a wider range of datasets to ensure the results generalize.
-
Real-world deployment: The paper does not address practical considerations for deploying such a system in real-world scenarios, such as the computational and power requirements of the IMU sensors.
-
Interpretability: As with many deep learning models, the internal representations learned by the autoencoder may be difficult to interpret. Providing more insight into what the model is learning could help researchers understand the key factors enabling the performance improvements.
-
Comparison to other multimodal fusion techniques: While the paper compares to some existing multimodal approaches, a more comprehensive evaluation against other state-of-the-art fusion methods would help contextualize the contributions of the MVBIA framework.
Overall, the paper presents a promising approach for leveraging complementary video and IMU data for improved egocentric action recognition. Further investigation into the generalization, deployment, and interpretability of the method could lead to even more impactful advancements in this area.
Conclusion
This paper introduces a novel Masked Video and Body-worn IMU Autoencoder (MVBIA) framework for egocentric action recognition. By training an autoencoder to effectively fuse video and IMU data, the model is able to outperform state-of-the-art methods that use these modalities separately or through other fusion techniques.
The key innovation is the use of a partially masked video input, which forces the autoencoder to learn representations that can leverage the complementary IMU data to compensate for the missing video information. This approach demonstrates the value of combining multiple sensing modalities for complex perception tasks like action recognition in first-person views.
While the current results are promising, further research is needed to explore the generalization, deployment, and interpretability of the MVBIA framework. Nonetheless, this work represents an important step forward in multimodal fusion for egocentric vision and could inspire similar techniques in other domains where complementary sensor data is available.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Masked Video and Body-worn IMU Autoencoder for Egocentric Action Recognition
Mingfang Zhang, Yifei Huang, Ruicong Liu, Yoichi Sato
Compared with visual signals, Inertial Measurement Units (IMUs) placed on human limbs can capture accurate motion signals while being robust to lighting variation and occlusion. While these characteristics are intuitively valuable to help egocentric action recognition, the potential of IMUs remains under-explored. In this work, we present a novel method for action recognition that integrates motion data from body-worn IMUs with egocentric video. Due to the scarcity of labeled multimodal data, we design an MAE-based self-supervised pretraining method, obtaining strong multi-modal representations via modeling the natural correlation between visual and motion signals. To model the complex relation of multiple IMU devices placed across the body, we exploit the collaborative dynamics in multiple IMU devices and propose to embed the relative motion features of human joints into a graph structure. Experiments show our method can achieve state-of-the-art performance on multiple public datasets. The effectiveness of our MAE-based pretraining and graph-based IMU modeling are further validated by experiments in more challenging scenarios, including partially missing IMU devices and video quality corruption, promoting more flexible usages in the real world.
Read more7/10/2024

0
Enhancing Inertial Hand based HAR through Joint Representation of Language, Pose and Synthetic IMUs
Vitor Fortes Rey, Lala Shakti Swarup Ray, Xia Qingxin, Kaishun Wu, Paul Lukowicz
Due to the scarcity of labeled sensor data in HAR, prior research has turned to video data to synthesize Inertial Measurement Units (IMU) data, capitalizing on its rich activity annotations. However, generating IMU data from videos presents challenges for HAR in real-world settings, attributed to the poor quality of synthetic IMU data and its limited efficacy in subtle, fine-grained motions. In this paper, we propose Multi$^3$Net, our novel multi-modal, multitask, and contrastive-based framework approach to address the issue of limited data. Our pretraining procedure uses videos from online repositories, aiming to learn joint representations of text, pose, and IMU simultaneously. By employing video data and contrastive learning, our method seeks to enhance wearable HAR performance, especially in recognizing subtle activities.Our experimental findings validate the effectiveness of our approach in improving HAR performance with IMU data. We demonstrate that models trained with synthetic IMU data generated from videos using our method surpass existing approaches in recognizing fine-grained activities.
Read more7/30/2024
🎲
0
IMUSE: IMU-based Facial Expression Capture
Youjia Wang, Yiwen Wu, Hengan Zhou, Hongyang Lin, Xingyue Peng, Yingwenqi Jiang, Yingsheng Zhu, Guanpeng Long, Yatu Zhang, Jingya Wang, Lan Xu, Jingyi Yu
For facial motion capture and analysis, the dominated solutions are generally based on visual cues, which cannot protect privacy and are vulnerable to occlusions. Inertial measurement units (IMUs) serve as potential rescues yet are mainly adopted for full-body motion capture. In this paper, we propose IMUSE to fill the gap, a novel path for facial expression capture using purely IMU signals, significantly distant from previous visual solutions.The key design in our IMUSE is a trilogy. We first design micro-IMUs to suit facial capture, companion with an anatomy-driven IMU placement scheme. Then, we contribute a novel IMU-ARKit dataset, which provides rich paired IMU/visual signals for diverse facial expressions and performances. Such unique multi-modality brings huge potential for future directions like IMU-based facial behavior analysis. Moreover, utilizing IMU-ARKit, we introduce a strong baseline approach to accurately predict facial blendshape parameters from purely IMU signals. The IMUSE framework empowers us to perform accurate facial capture in scenarios where visual methods falter and simultaneously safeguard user privacy. We conduct extensive experiments about both the IMU configuration and technical components to validate the effectiveness of our IMUSE approach. Notably, IMUSE enables various potential and novel applications, i.e., facial capture against occlusions or in a moving performance. We will release our dataset and implementations to enrich more possibilities of facial capture and analysis in our community.
Read more6/13/2024

0
EMHI: A Multimodal Egocentric Human Motion Dataset with HMD and Body-Worn IMUs
Zhen Fan, Peng Dai, Zhuo Su, Xu Gao, Zheng Lv, Jiarui Zhang, Tianyuan Du, Guidong Wang, Yang Zhang
Egocentric human pose estimation (HPE) using wearable sensors is essential for VR/AR applications. Most methods rely solely on either egocentric-view images or sparse Inertial Measurement Unit (IMU) signals, leading to inaccuracies due to self-occlusion in images or the sparseness and drift of inertial sensors. Most importantly, the lack of real-world datasets containing both modalities is a major obstacle to progress in this field. To overcome the barrier, we propose EMHI, a multimodal textbf{E}gocentric human textbf{M}otion dataset with textbf{H}ead-Mounted Display (HMD) and body-worn textbf{I}MUs, with all data collected under the real VR product suite. Specifically, EMHI provides synchronized stereo images from downward-sloping cameras on the headset and IMU data from body-worn sensors, along with pose annotations in SMPL format. This dataset consists of 885 sequences captured by 58 subjects performing 39 actions, totaling about 28.5 hours of recording. We evaluate the annotations by comparing them with optical marker-based SMPL fitting results. To substantiate the reliability of our dataset, we introduce MEPoser, a new baseline method for multimodal egocentric HPE, which employs a multimodal fusion encoder, temporal feature encoder, and MLP-based regression heads. The experiments on EMHI show that MEPoser outperforms existing single-modal methods and demonstrates the value of our dataset in solving the problem of egocentric HPE. We believe the release of EMHI and the method could advance the research of egocentric HPE and expedite the practical implementation of this technology in VR/AR products.
Read more9/2/2024