MASSIVE Multilingual Abstract Meaning Representation: A Dataset and Baselines for Hallucination Detection

0
Sign in to get full access
Overview
- This paper introduces MASSIVE, a new multilingual dataset for Abstract Meaning Representation (AMR) that includes over 200k sentences across 14 languages.
- The researchers also provide baseline models for the task of "hallucination detection" - identifying when an AMR-to-text model generates text that is not supported by the input AMR.
- This is an important task as AMR-to-text models can sometimes generate fluent-sounding text that diverges from the intended meaning of the input AMR.
Plain English Explanation
The paper focuses on a type of natural language processing called Abstract Meaning Representation (AMR). AMR is a way of representing the underlying meaning of a sentence in a structured, machine-readable format. This can be useful for tasks like summarization, question answering, and text generation.
However, one challenge with AMR-to-text models (which generate text from AMR representations) is that they can sometimes "hallucinate" - generating plausible-sounding text that doesn't accurately reflect the meaning of the input AMR.
To help address this, the researchers created a new multilingual dataset called MASSIVE, which contains over 200,000 sentences across 14 different languages, all annotated with their corresponding AMR representations. They also provide baseline machine learning models for the task of "hallucination detection" - identifying when an AMR-to-text model has generated text that doesn't match the input meaning.
This is an important contribution, as it provides a valuable resource for training and evaluating AMR-to-text models to ensure they generate text that faithfully represents the original meaning. It could help improve the reliability and trustworthiness of these types of language generation models.
Technical Explanation
The paper introduces a new multilingual dataset for Abstract Meaning Representation (AMR) called MASSIVE. AMR is a semantic representation that captures the underlying meaning of a sentence in a structured, machine-readable format. This can be useful for downstream natural language processing tasks like summarization, question answering, and text generation.
One key challenge with AMR-to-text models (which generate text from AMR representations) is the issue of "hallucination" - where the model generates fluent-sounding text that diverges from the intended meaning of the input AMR. To address this, the researchers create the MASSIVE dataset, which contains over 200,000 sentences across 14 languages, all annotated with their corresponding AMR representations.
In addition to the dataset, the paper also provides baseline models for the task of hallucination detection - identifying when an AMR-to-text model has generated text that is not supported by the input AMR. This is an important capability, as it can help ensure the reliability and trustworthiness of these types of language generation models.
The researchers experiment with several different model architectures for this task, including incorporating structured AMR information and leveraging long-range context. Their results demonstrate the value of the MASSIVE dataset and the importance of hallucination detection for improving the performance of AMR-to-text models.
Critical Analysis
The paper makes a valuable contribution by introducing the MASSIVE dataset and providing baseline models for hallucination detection in AMR-to-text generation. However, the authors acknowledge some limitations of their work.
For example, the dataset primarily consists of short, well-formed sentences, which may not fully capture the complexity of real-world language use. Additionally, the hallucination detection task is framed as a binary classification problem, which may not be sufficient to fully characterize the nuances of when an AMR-to-text model has deviated from the intended meaning.
Further research could explore ways to expand the dataset to include more diverse, naturalistic language, as well as develop more sophisticated approaches to hallucination detection that can provide more granular insights into the types of errors models make and the underlying causes.
Additionally, while the baseline models demonstrate the feasibility of this task, the performance is still relatively low, suggesting there is substantial room for improvement. Exploring more advanced model architectures and training techniques could help push the state-of-the-art in hallucination detection.
Conclusion
Overall, this paper makes an important contribution to the field of natural language processing by introducing the MASSIVE dataset and baseline models for the task of hallucination detection in AMR-to-text generation. By providing a standardized dataset and benchmarks, the researchers have laid the groundwork for future work to improve the reliability and trustworthiness of these types of language generation models, which could have significant implications for real-world applications like summarization, question answering, and dialogue systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MASSIVE Multilingual Abstract Meaning Representation: A Dataset and Baselines for Hallucination Detection
Michael Regan, Shira Wein, George Baker, Emilio Monti
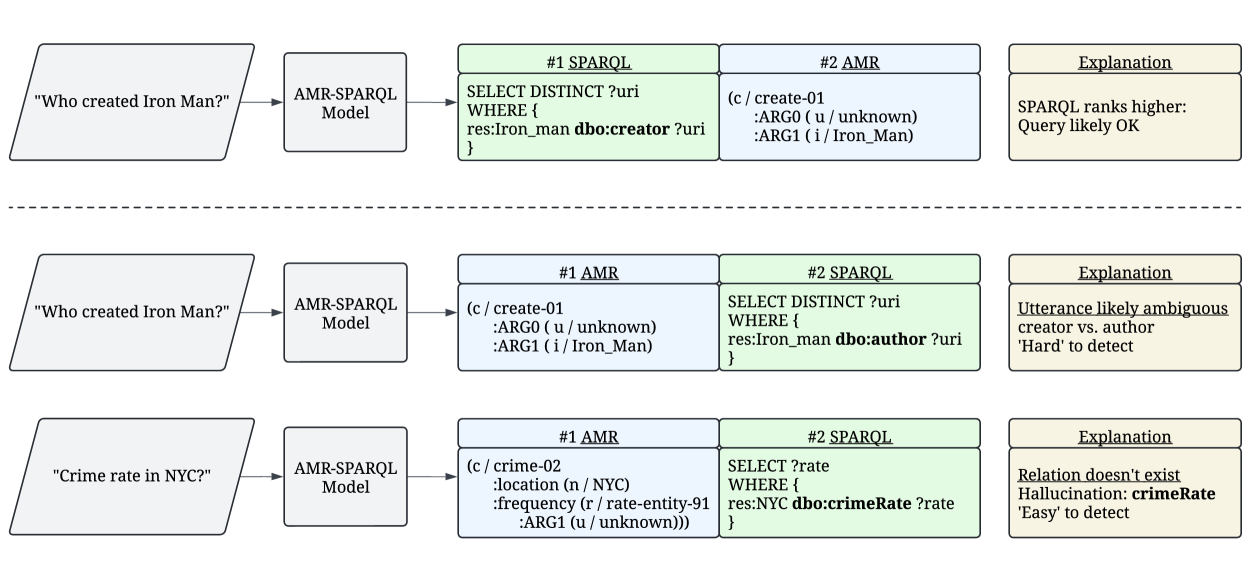
Abstract Meaning Representation (AMR) is a semantic formalism that captures the core meaning of an utterance. There has been substantial work developing AMR corpora in English and more recently across languages, though the limited size of existing datasets and the cost of collecting more annotations are prohibitive. With both engineering and scientific questions in mind, we introduce MASSIVE-AMR, a dataset with more than 84,000 text-to-graph annotations, currently the largest and most diverse of its kind: AMR graphs for 1,685 information-seeking utterances mapped to 50+ typologically diverse languages. We describe how we built our resource and its unique features before reporting on experiments using large language models for multilingual AMR and SPARQL parsing as well as applying AMRs for hallucination detection in the context of knowledge base question answering, with results shedding light on persistent issues using LLMs for structured parsing.
Read more5/30/2024
📊
0
Abstract Meaning Representation-Based Logic-Driven Data Augmentation for Logical Reasoning
Qiming Bao, Alex Yuxuan Peng, Zhenyun Deng, Wanjun Zhong, Gael Gendron, Timothy Pistotti, Neset Tan, Nathan Young, Yang Chen, Yonghua Zhu, Paul Denny, Michael Witbrock, Jiamou Liu
Combining large language models with logical reasoning enhances their capacity to address problems in a robust and reliable manner. Nevertheless, the intricate nature of logical reasoning poses challenges when gathering reliable data from the web to build comprehensive training datasets, subsequently affecting performance on downstream tasks. To address this, we introduce a novel logic-driven data augmentation approach, AMR-LDA. AMR-LDA converts the original text into an Abstract Meaning Representation (AMR) graph, a structured semantic representation that encapsulates the logical structure of the sentence, upon which operations are performed to generate logically modified AMR graphs. The modified AMR graphs are subsequently converted back into text to create augmented data. Notably, our methodology is architecture-agnostic and enhances both generative large language models, such as GPT-3.5 and GPT-4, through prompt augmentation, and discriminative large language models through contrastive learning with logic-driven data augmentation. Empirical evidence underscores the efficacy of our proposed method with improvement in performance across seven downstream tasks, such as reading comprehension requiring logical reasoning, textual entailment, and natural language inference. Furthermore, our method leads on the ReClor leaderboardfootnote{url{https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347}}. The source code and data are publicly availablefootnote{href{https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning}{AMR-LDA GitHub Repository}}.
Read more6/6/2024
💬
0
Analyzing the Role of Semantic Representations in the Era of Large Language Models
Zhijing Jin, Yuen Chen, Fernando Gonzalez, Jiarui Liu, Jiayi Zhang, Julian Michael, Bernhard Scholkopf, Mona Diab
Traditionally, natural language processing (NLP) models often use a rich set of features created by linguistic expertise, such as semantic representations. However, in the era of large language models (LLMs), more and more tasks are turned into generic, end-to-end sequence generation problems. In this paper, we investigate the question: what is the role of semantic representations in the era of LLMs? Specifically, we investigate the effect of Abstract Meaning Representation (AMR) across five diverse NLP tasks. We propose an AMR-driven chain-of-thought prompting method, which we call AMRCoT, and find that it generally hurts performance more than it helps. To investigate what AMR may have to offer on these tasks, we conduct a series of analysis experiments. We find that it is difficult to predict which input examples AMR may help or hurt on, but errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to its prediction. We recommend focusing on these areas for future work in semantic representations for LLMs. Our code: https://github.com/causalNLP/amr_llm.
Read more5/3/2024
0
3AM: An Ambiguity-Aware Multi-Modal Machine Translation Dataset
Xinyu Ma, Xuebo Liu, Derek F. Wong, Jun Rao, Bei Li, Liang Ding, Lidia S. Chao, Dacheng Tao, Min Zhang
Multimodal machine translation (MMT) is a challenging task that seeks to improve translation quality by incorporating visual information. However, recent studies have indicated that the visual information provided by existing MMT datasets is insufficient, causing models to disregard it and overestimate their capabilities. This issue presents a significant obstacle to the development of MMT research. This paper presents a novel solution to this issue by introducing 3AM, an ambiguity-aware MMT dataset comprising 26,000 parallel sentence pairs in English and Chinese, each with corresponding images. Our dataset is specifically designed to include more ambiguity and a greater variety of both captions and images than other MMT datasets. We utilize a word sense disambiguation model to select ambiguous data from vision-and-language datasets, resulting in a more challenging dataset. We further benchmark several state-of-the-art MMT models on our proposed dataset. Experimental results show that MMT models trained on our dataset exhibit a greater ability to exploit visual information than those trained on other MMT datasets. Our work provides a valuable resource for researchers in the field of multimodal learning and encourages further exploration in this area. The data, code and scripts are freely available at https://github.com/MaxyLee/3AM.
Read more4/30/2024