Abstract Meaning Representation-Based Logic-Driven Data Augmentation for Logical Reasoning

0
📊
Sign in to get full access
Overview
- Combining large language models with logical reasoning can enhance their performance on various tasks.
- However, gathering reliable data from the web to build comprehensive training datasets for logical reasoning poses challenges.
- To address this, the authors introduce a novel logic-driven data augmentation approach called AMR-LDA.
Plain English Explanation
The paper discusses a method to improve the capabilities of large language models, which are powerful AI systems trained on vast amounts of text data. While these models excel at tasks like generating human-like text, they can struggle with problems that require logical reasoning.
The key idea behind the AMR-LDA approach is to transform the original text into a structured representation called an Abstract Meaning Representation (AMR) graph. This graph captures the logical structure of the sentence, essentially "distilling" the meaning into a more abstract form.
The researchers then perform operations on these AMR graphs to generate modified versions, which are then converted back into text. This creates new, logically-altered training data that can be used to enhance the language models' understanding of logical reasoning.
The method is designed to work with different types of language models, both generative (like GPT-3.5 and GPT-4) and discriminative (models used for tasks like reading comprehension and textual entailment).
The authors show that this approach leads to improved performance on a variety of downstream tasks that require logical reasoning, such as reading comprehension, textual entailment, and natural language inference. The method also achieves state-of-the-art results on the ReClor benchmark, which specifically tests logical reasoning abilities.
Technical Explanation
The AMR-LDA approach converts the original text into an Abstract Meaning Representation (AMR) graph, a structured semantic representation that encapsulates the logical structure of the sentence. The researchers then perform various operations on these AMR graphs to generate logically modified versions, which are subsequently converted back into text to create augmented data.
This logic-driven data augmentation method is designed to be architecture-agnostic, meaning it can be applied to enhance both generative large language models (like GPT-3.5 and GPT-4) through prompt augmentation, as well as discriminative large language models through contrastive learning.
The authors evaluate their proposed method on seven downstream tasks that require logical reasoning, including reading comprehension, textual entailment, and natural language inference. Empirical results demonstrate the effectiveness of their approach, with significant improvements in performance across these tasks. Additionally, the AMR-LDA method achieves state-of-the-art results on the ReClor benchmark.
Critical Analysis
The key strength of the AMR-LDA approach is its ability to leverage structured semantic representations to enhance language models' understanding of logical reasoning. By transforming the text into AMR graphs and performing targeted modifications, the researchers are able to generate augmented data that can help language models better generalize to tasks that require logical inference.
However, the paper does not address the potential limitations of the AMR representation itself. While AMR is a powerful tool for capturing the logical structure of language, it may not be able to fully capture all the nuances and complexities of human reasoning. Additionally, the process of converting text to AMR and back again could introduce potential errors or information loss, which could impact the quality of the augmented data.
Furthermore, the paper does not provide a detailed analysis of the computational and memory requirements of the AMR-LDA approach, which could be an important consideration for real-world deployment, especially in resource-constrained environments.
Despite these potential limitations, the AMR-LDA method represents a promising step towards enhancing the logical reasoning capabilities of large language models. As the field of AI continues to advance, further research in this area could lead to significant improvements in the robustness and reliability of these powerful systems.
Conclusion
The AMR-LDA method introduced in this paper represents a novel approach to improving the logical reasoning capabilities of large language models. By leveraging structured semantic representations and performing targeted data augmentation, the researchers have demonstrated significant performance improvements on a variety of downstream tasks that require logical inference.
This work highlights the potential benefits of combining large language models with more structured forms of knowledge representation and reasoning. As the field of AI continues to evolve, techniques like AMR-LDA could play an important role in enhancing the robustness and reliability of these powerful systems, paving the way for more sophisticated and trustworthy AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Abstract Meaning Representation-Based Logic-Driven Data Augmentation for Logical Reasoning
Qiming Bao, Alex Yuxuan Peng, Zhenyun Deng, Wanjun Zhong, Gael Gendron, Timothy Pistotti, Neset Tan, Nathan Young, Yang Chen, Yonghua Zhu, Paul Denny, Michael Witbrock, Jiamou Liu
Combining large language models with logical reasoning enhances their capacity to address problems in a robust and reliable manner. Nevertheless, the intricate nature of logical reasoning poses challenges when gathering reliable data from the web to build comprehensive training datasets, subsequently affecting performance on downstream tasks. To address this, we introduce a novel logic-driven data augmentation approach, AMR-LDA. AMR-LDA converts the original text into an Abstract Meaning Representation (AMR) graph, a structured semantic representation that encapsulates the logical structure of the sentence, upon which operations are performed to generate logically modified AMR graphs. The modified AMR graphs are subsequently converted back into text to create augmented data. Notably, our methodology is architecture-agnostic and enhances both generative large language models, such as GPT-3.5 and GPT-4, through prompt augmentation, and discriminative large language models through contrastive learning with logic-driven data augmentation. Empirical evidence underscores the efficacy of our proposed method with improvement in performance across seven downstream tasks, such as reading comprehension requiring logical reasoning, textual entailment, and natural language inference. Furthermore, our method leads on the ReClor leaderboardfootnote{url{https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347}}. The source code and data are publicly availablefootnote{href{https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning}{AMR-LDA GitHub Repository}}.
Read more6/6/2024
💬
0
Analyzing the Role of Semantic Representations in the Era of Large Language Models
Zhijing Jin, Yuen Chen, Fernando Gonzalez, Jiarui Liu, Jiayi Zhang, Julian Michael, Bernhard Scholkopf, Mona Diab
Traditionally, natural language processing (NLP) models often use a rich set of features created by linguistic expertise, such as semantic representations. However, in the era of large language models (LLMs), more and more tasks are turned into generic, end-to-end sequence generation problems. In this paper, we investigate the question: what is the role of semantic representations in the era of LLMs? Specifically, we investigate the effect of Abstract Meaning Representation (AMR) across five diverse NLP tasks. We propose an AMR-driven chain-of-thought prompting method, which we call AMRCoT, and find that it generally hurts performance more than it helps. To investigate what AMR may have to offer on these tasks, we conduct a series of analysis experiments. We find that it is difficult to predict which input examples AMR may help or hurt on, but errors tend to arise with multi-word expressions, named entities, and in the final inference step where the LLM must connect its reasoning over the AMR to its prediction. We recommend focusing on these areas for future work in semantic representations for LLMs. Our code: https://github.com/causalNLP/amr_llm.
Read more5/3/2024
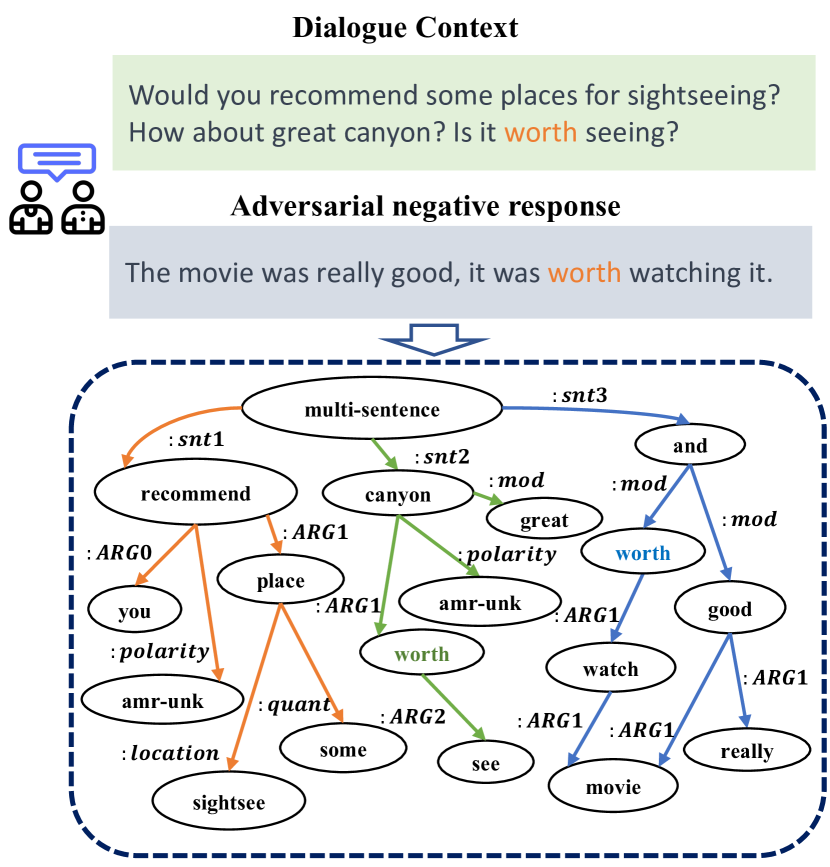
0
Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation
Bohao Yang, Kun Zhao, Chen Tang, Dong Liu, Liang Zhan, Chenghua Lin
Automatic open-domain dialogue evaluation has attracted increasing attention. Trainable evaluation metrics, typically trained with true positive and randomly selected negative responses, tend to assign higher scores to responses that share greater content similarity with a given context. However, adversarial negative responses, despite possessing high content similarity with the contexts, are semantically different. Consequently, existing evaluation metrics are not robust enough to evaluate such responses, resulting in low correlations with human judgments. While recent studies have demonstrated the effectiveness of Large Language Models (LLMs) for open-domain dialogue evaluation, they still face challenges in effectively handling adversarial negative examples. In this paper, we propose an effective framework for open-domain dialogue evaluation, which combines domain-specific language models (SLMs) enhanced with Abstract Meaning Representation (AMR) knowledge with LLMs. The SLMs can explicitly incorporate AMR graph information of the dialogue through a gating mechanism for enhanced dialogue semantic representation learning. Both the evaluation result from the SLMs and the AMR graph information are incorporated into the LLM's prompt for enhanced evaluation performance. Experimental results on open-domain dialogue evaluation tasks demonstrate the superiority of our method compared to a wide range of state-of-the-art baselines, especially in discriminating adversarial negative responses. Our code and data are publicly available at https://github.com/Bernard-Yang/SIMAMR.
Read more8/19/2024
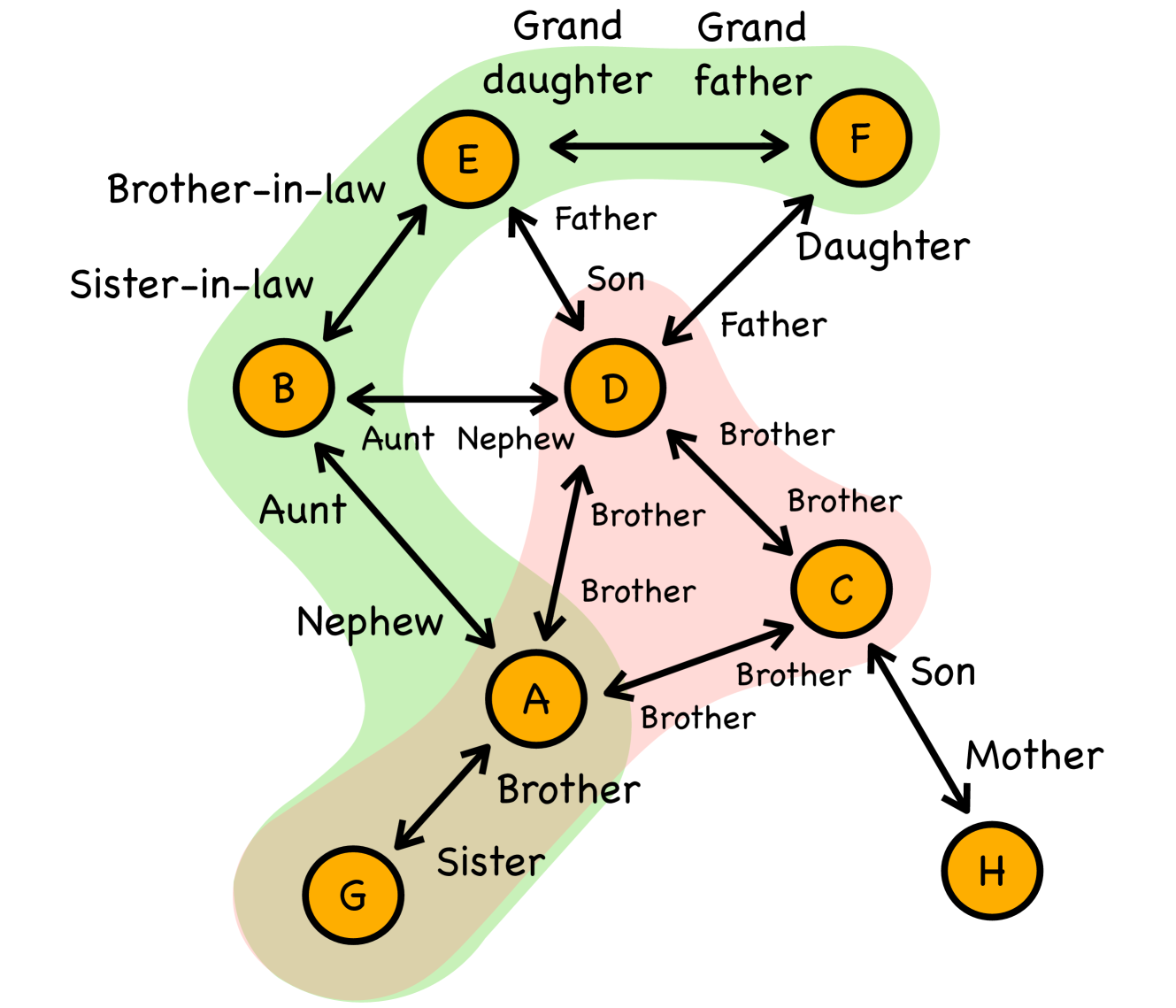
0
Enhancing Logical Reasoning in Large Language Models through Graph-based Synthetic Data
Jiaming Zhou, Abbas Ghaddar, Ge Zhang, Liheng Ma, Yaochen Hu, Soumyasundar Pal, Mark Coates, Bin Wang, Yingxue Zhang, Jianye Hao
Despite recent advances in training and prompting strategies for Large Language Models (LLMs), these models continue to face challenges with complex logical reasoning tasks that involve long reasoning chains. In this work, we explore the potential and limitations of using graph-based synthetic reasoning data as training signals to enhance LLMs' reasoning capabilities. Our extensive experiments, conducted on two established natural language reasoning tasks -- inductive reasoning and spatial reasoning -- demonstrate that supervised fine-tuning (SFT) with synthetic graph-based reasoning data effectively enhances LLMs' reasoning performance without compromising their effectiveness on other standard evaluation benchmarks.
Read more9/20/2024