Mast Kalandar at SemEval-2024 Task 8: On the Trail of Textual Origins: RoBERTa-BiLSTM Approach to Detect AI-Generated Text

0

Sign in to get full access
Overview
- Researchers from Mast Kalandar participated in SemEval-2024 Task 8, which focused on detecting AI-generated text.
- They proposed a RoBERTa-BiLSTM model, a hybrid approach combining a Transformer-based language model and a Bidirectional Long Short-Term Memory (BiLSTM) network.
- The goal was to leverage the strengths of both architectures to improve the detection of AI-generated content.
Plain English Explanation
The paper discusses the approach taken by the Mast Kalandar team to address the challenge of detecting AI-generated text in the SemEval-2024 Task 8. They developed a hybrid model that combined two powerful techniques: RoBERTa, a Transformer-based language model, and a Bidirectional Long Short-Term Memory (BiLSTM) network.
The key idea behind this approach was to leverage the strengths of both models. RoBERTa is known for its impressive performance in understanding and processing natural language, while BiLSTM networks excel at capturing the sequential and contextual information in text. By combining these two components, the researchers aimed to create a more effective system for identifying AI-generated content, which can often have subtle differences compared to human-written text.
Technical Explanation
The Mast Kalandar team's RoBERTa-BiLSTM approach involved using the RoBERTa model as the initial feature extractor, followed by a BiLSTM network to capture the sequential and contextual information in the text. This hybrid architecture allowed the model to benefit from the strengths of both components, potentially leading to improved performance in the AI-generated text detection task.
The researchers fine-tuned the pre-trained RoBERTa model on the task-specific dataset, which helped the model learn the relevant features for distinguishing AI-generated from human-written text. The BiLSTM network was then added to the architecture to further refine the understanding of the text's sequential and contextual properties.
The DeepPavlov and PetKaz teams also explored similar hybrid approaches, combining Transformer-based models with recurrent neural networks like LSTM or GRU, demonstrating the potential of these context-aware hybrid models for the task of detecting AI-generated text.
Critical Analysis
The paper provides a solid technical explanation of the Mast Kalandar team's approach and its potential benefits. However, the authors do not discuss any limitations or potential issues with their model. It would be valuable to understand any challenges they faced, such as the model's performance on specific types of AI-generated text or the computational overhead of the hybrid architecture.
Additionally, the paper does not explore the interpretability of the model's predictions, which could be an important consideration for real-world applications of AI-generated text detection. Understanding the specific linguistic or stylistic features that the model uses to make its decisions could provide valuable insights and help users trust the model's outputs.
Conclusion
The Mast Kalandar team's RoBERTa-BiLSTM approach represents a promising direction in the quest to detect AI-generated text. By combining the strengths of Transformer-based and recurrent neural network models, the researchers aimed to create a more comprehensive and effective system for this task.
The findings from this work, along with the similar hybrid approaches explored by other teams, suggest that context-aware models that can capture both semantic and sequential information may be crucial for tackling the challenge of distinguishing AI-generated content from human-written text. As the field of AI-generated text detection continues to evolve, further research and exploration of such hybrid architectures could lead to significant advancements in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mast Kalandar at SemEval-2024 Task 8: On the Trail of Textual Origins: RoBERTa-BiLSTM Approach to Detect AI-Generated Text
Jainit Sushil Bafna, Hardik Mittal, Suyash Sethia, Manish Shrivastava, Radhika Mamidi
Large Language Models (LLMs) have showcased impressive abilities in generating fluent responses to diverse user queries. However, concerns regarding the potential misuse of such texts in journalism, educational, and academic contexts have surfaced. SemEval 2024 introduces the task of Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection, aiming to develop automated systems for identifying machine-generated text and detecting potential misuse. In this paper, we i) propose a RoBERTa-BiLSTM based classifier designed to classify text into two categories: AI-generated or human ii) conduct a comparative study of our model with baseline approaches to evaluate its effectiveness. This paper contributes to the advancement of automatic text detection systems in addressing the challenges posed by machine-generated text misuse. Our architecture ranked 46th on the official leaderboard with an accuracy of 80.83 among 125.
Read more7/4/2024
0
DeepPavlov at SemEval-2024 Task 8: Leveraging Transfer Learning for Detecting Boundaries of Machine-Generated Texts
Anastasia Voznyuk, Vasily Konovalov
The Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection shared task in the SemEval-2024 competition aims to tackle the problem of misusing collaborative human-AI writing. Although there are a lot of existing detectors of AI content, they are often designed to give a binary answer and thus may not be suitable for more nuanced problem of finding the boundaries between human-written and machine-generated texts, while hybrid human-AI writing becomes more and more popular. In this paper, we address the boundary detection problem. Particularly, we present a pipeline for augmenting data for supervised fine-tuning of DeBERTaV3. We receive new best MAE score, according to the leaderboard of the competition, with this pipeline.
Read more5/20/2024
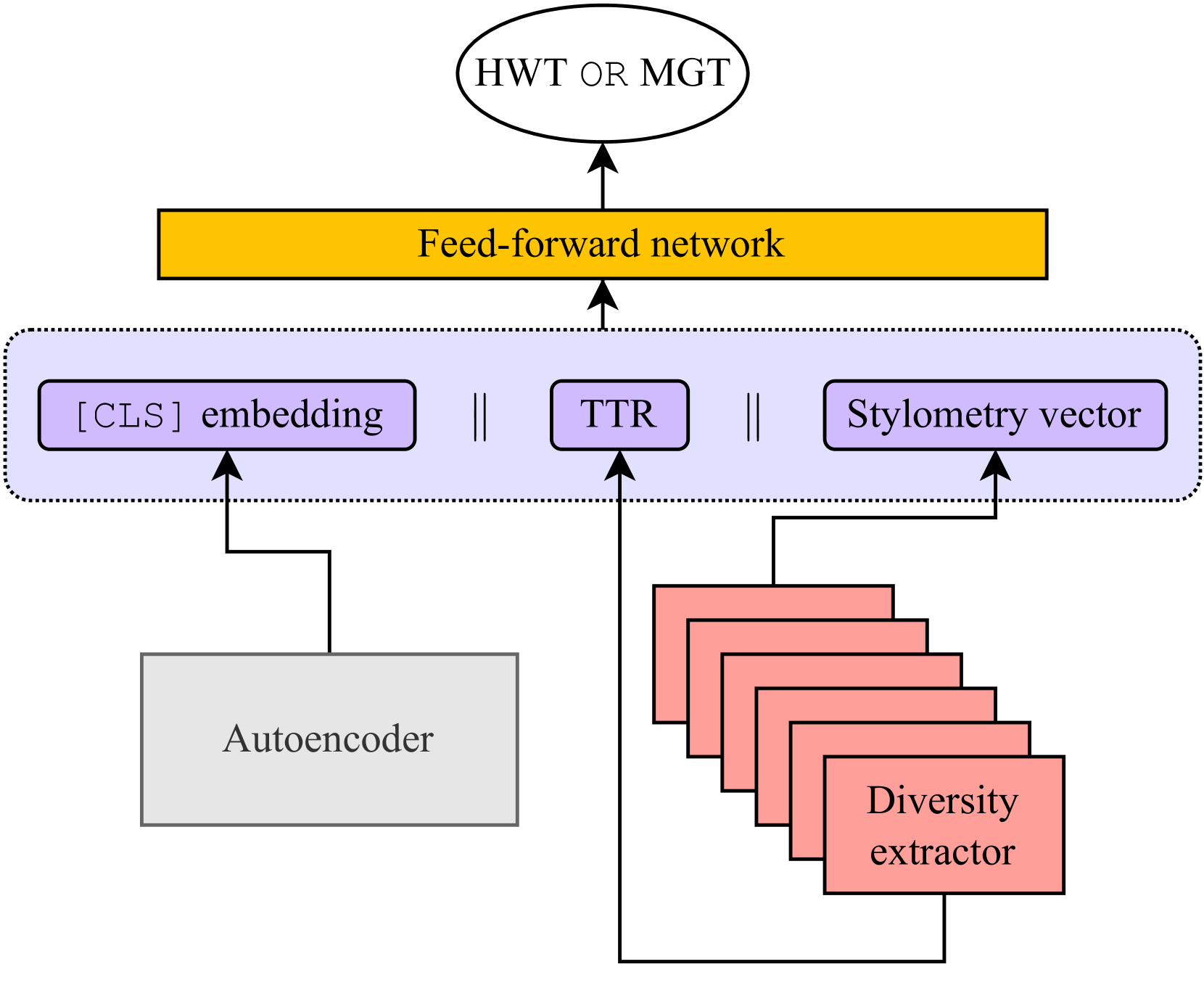
0
PetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
Kseniia Petukhova, Roman Kazakov, Ekaterina Kochmar
In this paper, we present our submission to the SemEval-2024 Task 8 Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection, focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
Read more4/9/2024

0
Transformer and Hybrid Deep Learning Based Models for Machine-Generated Text Detection
Teodor-George Marchitan, Claudiu Creanga, Liviu P. Dinu
This paper describes the approach of the UniBuc - NLP team in tackling the SemEval 2024 Task 8: Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. We explored transformer-based and hybrid deep learning architectures. For subtask B, our transformer-based model achieved a strong textbf{second-place} out of $77$ teams with an accuracy of textbf{86.95%}, demonstrating the architecture's suitability for this task. However, our models showed overfitting in subtask A which could potentially be fixed with less fine-tunning and increasing maximum sequence length. For subtask C (token-level classification), our hybrid model overfit during training, hindering its ability to detect transitions between human and machine-generated text.
Read more5/29/2024