MathBridge: A Large-Scale Dataset for Translating Mathematical Expressions into Formula Images

0

Sign in to get full access
Overview
- MathBridge is a large-scale dataset for translating mathematical expressions into formula images
- It contains over 5 million examples of mathematical expressions and their corresponding formula images
- The dataset aims to support research in areas like mathematical expression recognition, text-to-image generation, and multimodal learning
Plain English Explanation
MathBridge is a new dataset that connects written mathematical expressions with their visual representations as formula images. This dataset is designed to help researchers develop AI systems that can understand and translate between these two different ways of representing math.
The key idea is that many AI applications could benefit from being able to work with both the textual and visual forms of mathematical information. For example, an AI system could take a written equation and generate a corresponding image of that equation, or vice versa. This could be useful for applications like math education, scientific document analysis, or data visualization.
To create the MathBridge dataset, the researchers collected over 5 million examples of mathematical expressions and their corresponding formula images from various online sources. This large-scale dataset provides a rich resource for training and evaluating AI models in this domain.
Technical Explanation
The MathBridge dataset was constructed by crawling and extracting mathematical expressions and their corresponding formula images from a variety of websites, including textbooks, scientific papers, and educational resources. The resulting dataset contains over 5 million examples, making it one of the largest resources of its kind.
Each example in the dataset consists of a textual mathematical expression and an associated formula image. The textual expressions are represented as LaTeX code, which is a widely used markup language for typesetting mathematics. The formula images are provided in both PNG and SVG formats, allowing for flexibility in how the data can be used.
The researchers designed the dataset to support a range of research tasks, including mathematical expression recognition, text-to-image generation, and multimodal learning. They also included metadata such as the source website and the type of mathematical content (e.g., algebra, calculus, etc.) to enable more targeted analysis and evaluation.
Critical Analysis
The MathBridge dataset represents a significant contribution to the field of mathematical AI. By providing a large-scale, high-quality dataset that connects textual and visual representations of mathematics, it opens up new avenues for research and development in this area.
One potential limitation mentioned in the paper is the potential for bias in the dataset, as the sources used to collect the data may not be representative of all mathematical domains or applications. The researchers acknowledge this and suggest that further curation and annotation of the dataset could help address this issue.
Additionally, while the dataset is large, it may not capture the full complexity and diversity of mathematical expressions encountered in real-world scenarios. Expanding the dataset or exploring techniques for augmenting the existing data could be areas for further research.
Conclusion
The MathBridge dataset is a valuable resource that can enable significant advancements in the field of mathematical AI. By providing a large-scale, high-quality dataset that connects textual and visual representations of mathematics, it opens up new possibilities for developing AI systems that can understand and manipulate mathematical information in more natural and intuitive ways. This has the potential to impact a wide range of applications, from education and scientific research to data visualization and automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MathBridge: A Large-Scale Dataset for Translating Mathematical Expressions into Formula Images
Kyudan Jung, Sieun Hyeon, Jeong Youn Kwon, Nam-Joon Kim, Hyun Gon Ryu, Hyuk-Jae Lee, Jaeyoung Do
Improving the readability of mathematical expressions in text-based document such as subtitle of mathematical video, is an significant task. To achieve this, mathematical expressions should be convert to compiled formulas. For instance, the spoken expression ``x equals minus b plus or minus the square root of b squared minus four a c, all over two a'' from automatic speech recognition is more readily comprehensible when displayed as a compiled formula $x = frac{-b pm sqrt{b^2 - 4ac}}{2a}$. To convert mathematical spoken sentences to compiled formulas, two processes are required: spoken sentences are converted into LaTeX formulas, and LaTeX formulas are converted into compiled formulas. The latter can be managed by using LaTeX engines. However, there is no way to do the former effectively. Even if we try to solve this using language models, there is no paired data between spoken sentences and LaTeX formulas to train it. In this paper, we introduce MathBridge, the first extensive dataset for translating mathematical spoken sentences into LaTeX formulas. MathBridge comprises approximately 23 million LaTeX formulas paired with the corresponding mathematical spoken sentences. Through comprehensive evaluations, including fine-tuning with proposed data, we discovered that MathBridge significantly enhances the capabilities of pretrained language models for converting to LaTeX formulas from mathematical spoken sentences. Specifically, for the T5-large model, the sacreBLEU score increased from 4.77 to 46.8, demonstrating substantial enhancement.
Read more8/19/2024
0
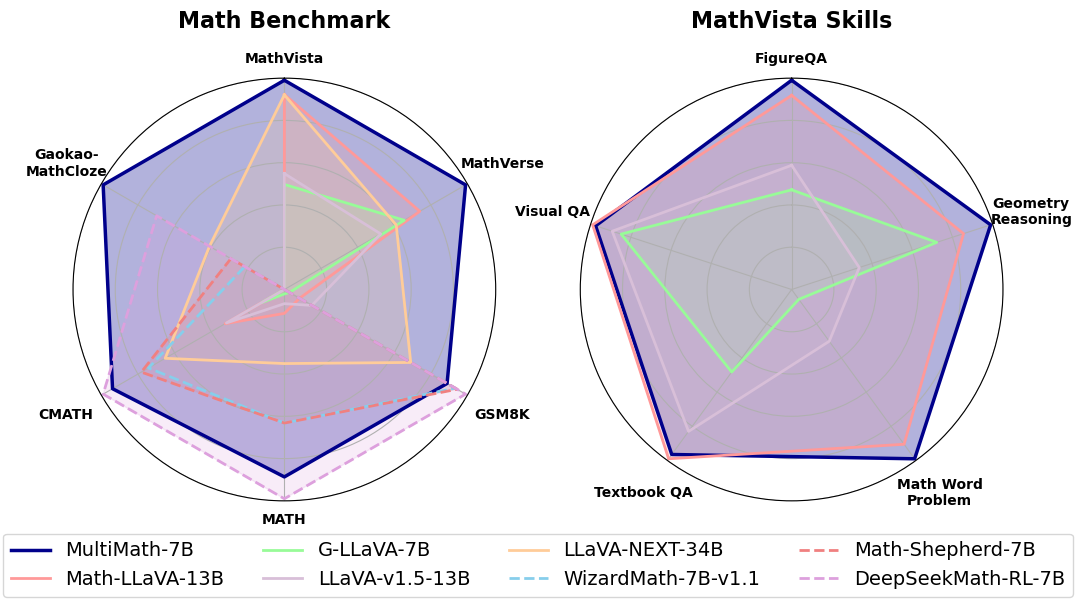
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {textcolor{blue}{url{https://github.com/pengshuai-rin/MultiMath}}}.
Read more9/4/2024

0
MathNet: A Data-Centric Approach for Printed Mathematical Expression Recognition
Felix M. Schmitt-Koopmann, Elaine M. Huang, Hans-Peter Hutter, Thilo Stadelmann, Alireza Darvishy
Printed mathematical expression recognition (MER) models are usually trained and tested using LaTeX-generated mathematical expressions (MEs) as input and the LaTeX source code as ground truth. As the same ME can be generated by various different LaTeX source codes, this leads to unwanted variations in the ground truth data that bias test performance results and hinder efficient learning. In addition, the use of only one font to generate the MEs heavily limits the generalization of the reported results to realistic scenarios. We propose a data-centric approach to overcome this problem, and present convincing experimental results: Our main contribution is an enhanced LaTeX normalization to map any LaTeX ME to a canonical form. Based on this process, we developed an improved version of the benchmark dataset im2latex-100k, featuring 30 fonts instead of one. Second, we introduce the real-world dataset realFormula, with MEs extracted from papers. Third, we developed a MER model, MathNet, based on a convolutional vision transformer, with superior results on all four test sets (im2latex-100k, im2latexv2, realFormula, and InftyMDB-1), outperforming the previous state of the art by up to 88.3%.
Read more4/23/2024

0
Lean Workbook: A large-scale Lean problem set formalized from natural language math problems
Huaiyuan Ying, Zijian Wu, Yihan Geng, Jiayu Wang, Dahua Lin, Kai Chen
Large language models have demonstrated impressive capabilities across various natural language processing tasks, especially in solving mathematical problems. However, large language models are not good at math theorem proving using formal languages like Lean. A significant challenge in this area is the scarcity of training data available in these formal languages. To address this issue, we propose a novel pipeline that iteratively generates and filters synthetic data to translate natural language mathematical problems into Lean 4 statements, and vice versa. Our results indicate that the synthetic data pipeline can provide useful training data and improve the performance of LLMs in translating and understanding complex mathematical problems and proofs. Our final dataset contains about 57K formal-informal question pairs along with searched proof from the math contest forum and 21 new IMO questions. We open-source our code at https://github.com/InternLM/InternLM-Math and our data at https://huggingface.co/datasets/InternLM/Lean-Workbook.
Read more6/10/2024