MathCAMPS: Fine-grained Synthesis of Mathematical Problems From Human Curricula

0
Sign in to get full access
Overview
- This paper introduces MathCAMPS, a system for fine-grained synthesis of mathematical problems from human curricula.
- The key idea is to leverage large language models and curriculum data to automatically generate diverse, high-quality math problems tailored to specific educational needs.
- The system is evaluated on its ability to generate problems that match the difficulty and content of human-created math problems from popular textbooks and curricula.
Plain English Explanation
The researchers developed a system called MathCAMPS that can automatically generate math problems tailored to specific educational needs. Rather than relying on humans to create these problems from scratch, MathCAMPS leverages large language models and existing curriculum data to produce a diverse set of high-quality math problems.
The core innovation is using language models, which are AI systems trained on vast amounts of text data, to understand the structure and content of math problems. By analyzing existing math problems from textbooks and curricula, MathCAMPS can learn the characteristics of good math problems and then generate new ones that match those patterns.
This allows the system to produce a wide variety of math problems that are closely aligned with the kind of content and difficulty level that teachers and students are used to. Instead of generic math problems, MathCAMPS can generate problems specific to the topics being covered in a particular classroom or educational program.
The researchers evaluated MathCAMPS by having it generate problems and then comparing them to human-created problems from popular math textbooks. They found that the system was able to produce problems that were very similar in terms of content and difficulty, demonstrating its ability to mimic the characteristics of high-quality math problems.
Overall, MathCAMPS represents an exciting application of large language models and AI to the challenge of math education. By automating the process of problem generation, it has the potential to save teachers time and provide students with a more personalized and engaging learning experience.
Technical Explanation
The key technical innovation of MathCAMPS is its use of large language models and curriculum data to generate fine-grained, high-quality mathematical problems. The system first analyzes a corpus of human-created math problems from textbooks and curricula, learning the linguistic and structural patterns that characterize good math problems.
It then uses this knowledge to guide the generation of new problems using a large language model. Specifically, the system employs prompting techniques to condition the language model on specific topics, difficulty levels, and other attributes, allowing it to produce problems tailored to the desired educational context.
The researchers evaluate MathCAMPS by having it generate math problems and then comparing them to human-created problems from popular math textbooks. They assess the similarity of the generated problems in terms of content, difficulty, and other key attributes. The results show that MathCAMPS is able to produce problems that are highly aligned with human-crafted ones, demonstrating its ability to capture the nuances of high-quality math problem design.
Critical Analysis
The key strength of MathCAMPS is its ability to automate the generation of math problems while maintaining the level of quality and specificity that human experts can provide. By leveraging large language models and curriculum data, the system is able to produce a diverse set of problems that closely match the characteristics of human-created ones.
However, the paper does acknowledge some potential limitations and areas for further research. For example, the evaluation is focused on textbook-style problems, and the system may struggle with more open-ended or creative math problems. Additionally, the paper does not address potential biases or inconsistencies that may arise in the generated problems.
Further research could explore ways to enhance the system's ability to handle a wider range of problem types, as well as investigate methods for ensuring the generated problems are consistently high-quality and free of biases. Integrating MathCAMPS with other educational technologies, such as adaptive learning platforms, could also be a fruitful area for future work.
Overall, MathCAMPS represents an exciting step forward in the application of large language models to the challenge of math education. By automating the problem generation process, it has the potential to save teachers time and provide students with a more personalized and engaging learning experience.
Conclusion
The MathCAMPS system demonstrates the potential of large language models and curriculum data to automate the fine-grained synthesis of high-quality mathematical problems. By leveraging these technologies, the system is able to generate diverse sets of problems that closely match the content and difficulty of human-created ones from popular textbooks and curricula.
This capability has significant implications for math education, as it could save teachers time, provide students with more personalized learning experiences, and potentially improve math outcomes. While the current evaluation is limited to textbook-style problems, further research could explore ways to expand the system's capabilities and integrate it with other educational technologies.
Overall, the MathCAMPS paper represents an important contribution to the growing field of AI-powered educational tools, showcasing the power of large language models and curriculum data to enhance the way we approach the teaching and learning of mathematics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MathCAMPS: Fine-grained Synthesis of Mathematical Problems From Human Curricula
Shubhra Mishra, Gabriel Poesia, Belinda Mo, Noah D. Goodman
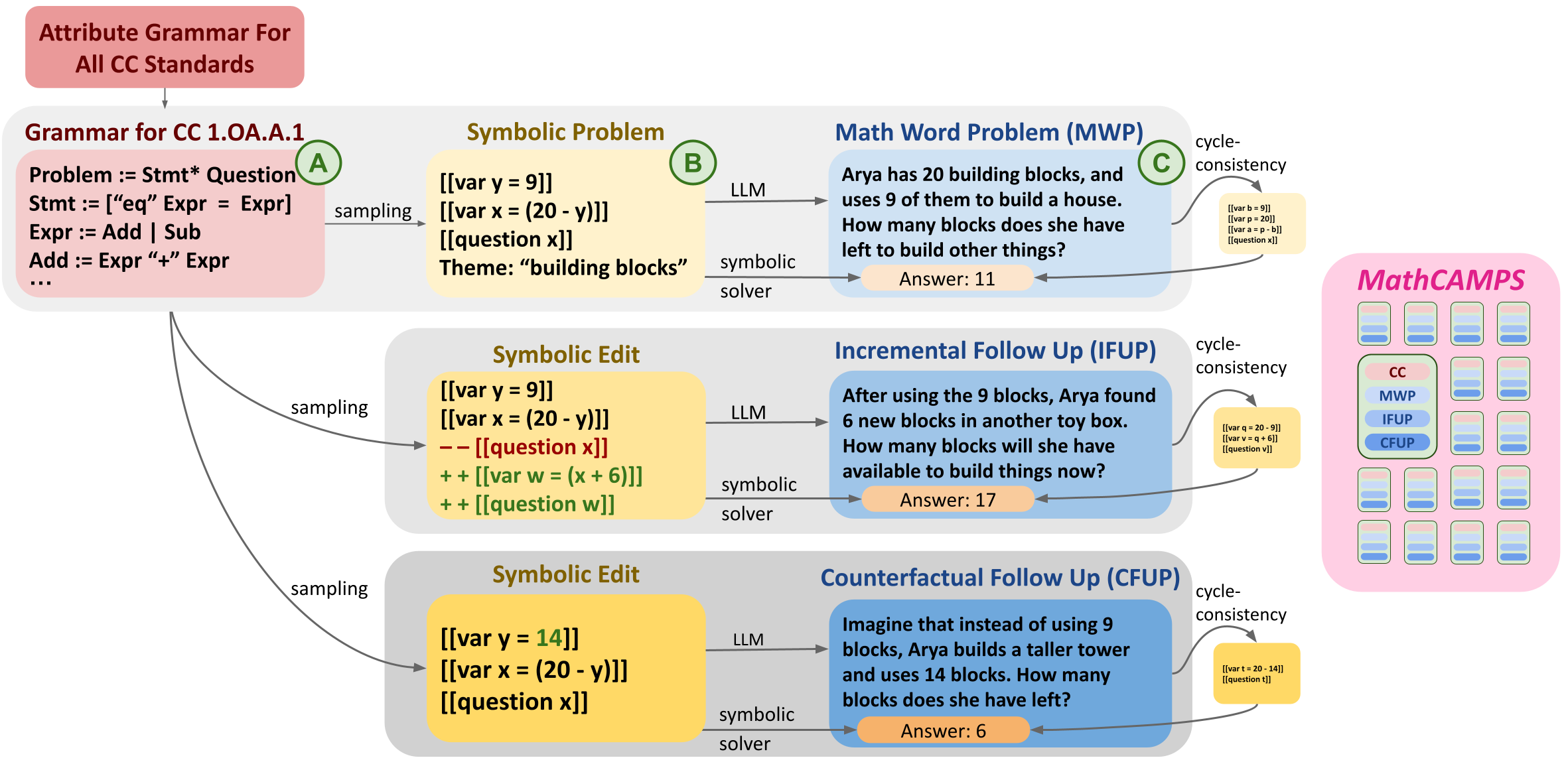
Mathematical problem solving is an important skill for Large Language Models (LLMs), both as an important capability and a proxy for a range of reasoning abilities. Existing benchmarks probe a diverse set of skills, but they yield aggregate accuracy metrics, obscuring specific abilities or weaknesses. Furthermore, they are difficult to extend with new problems, risking data contamination over time. To address these challenges, we propose MathCAMPS: a method to synthesize high-quality mathematical problems at scale, grounded on 44 fine-grained standards from the Mathematics Common Core (CC) Standard for K-8 grades. We encode each standard in a formal grammar, allowing us to sample diverse symbolic problems and their answers. We then use LLMs to realize the symbolic problems into word problems. We propose a cycle-consistency method for validating problem faithfulness. Finally, we derive follow-up questions from symbolic structures and convert them into follow-up word problems - a novel task of mathematical dialogue that probes for robustness in understanding. Experiments on 23 LLMs show surprising failures even in the strongest models (in particular when asked simple follow-up questions). Moreover, we evaluate training checkpoints of Pythia 12B on MathCAMPS, allowing us to analyze when particular mathematical skills develop during its training. Our framework enables the community to reproduce and extend our pipeline for a fraction of the typical cost of building new high-quality datasets.
Read more7/2/2024
0
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
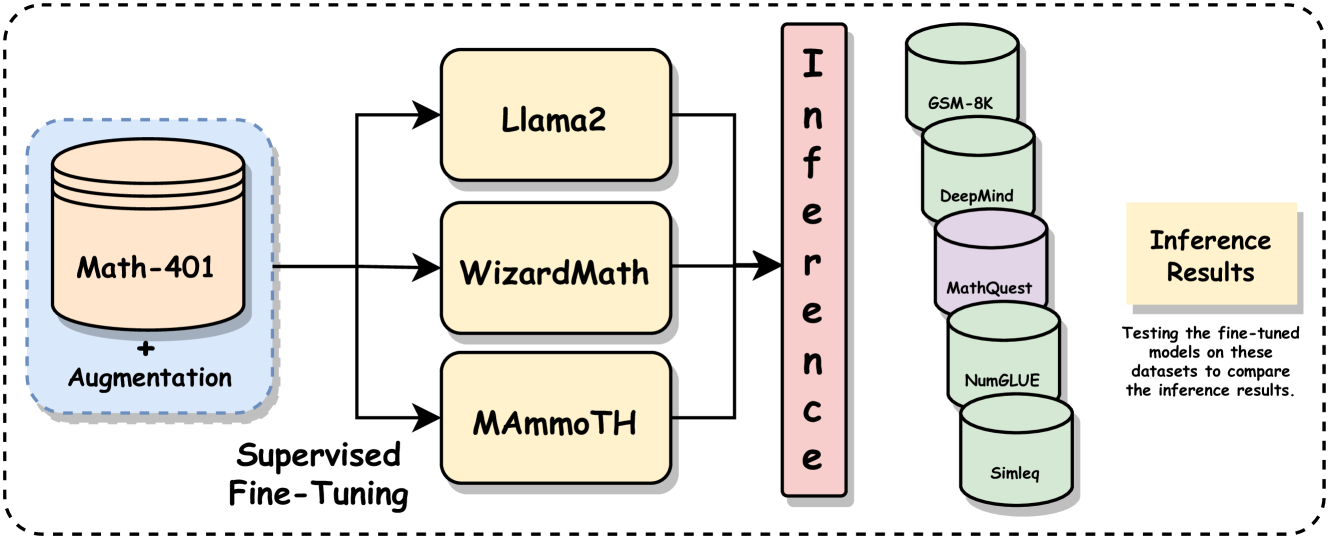
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
Read more4/23/2024

0
CHAMP: A Competition-level Dataset for Fine-Grained Analyses of LLMs' Mathematical Reasoning Capabilities
Yujun Mao, Yoon Kim, Yilun Zhou
Recent large language models (LLMs) have shown indications of mathematical reasoning ability on challenging competition-level problems, especially with self-generated verbalizations of intermediate reasoning steps (i.e., chain-of-thought prompting). However, current evaluations mainly focus on the end-to-end final answer correctness, and it is unclear whether LLMs can make use of helpful side information such as problem-specific hints. In this paper, we propose a challenging benchmark dataset for enabling such analyses. The Concept and Hint-Annotated Math Problems (CHAMP) consists of high school math competition problems, annotated with concepts, or general math facts, and hints, or problem-specific tricks. These annotations allow us to explore the effects of additional information, such as relevant hints, misleading concepts, or related problems. This benchmark is difficult, with the best model only scoring 58.1% in standard settings. With concepts and hints, performance sometimes improves, indicating that some models can make use of such side information. Furthermore, we annotate model-generated solutions for their correctness. Using this corpus, we find that models often arrive at the correct final answer through wrong reasoning steps. In addition, we test whether models are able to verify these solutions, and find that most models struggle.
Read more6/11/2024
🛸
0
AI-Assisted Generation of Difficult Math Questions
Vedant Shah, Dingli Yu, Kaifeng Lyu, Simon Park, Nan Rosemary Ke, Michael Mozer, Yoshua Bengio, Sanjeev Arora, Anirudh Goyal
Current LLM training positions mathematical reasoning as a core capability. With publicly available sources fully tapped, there is unmet demand for diverse and challenging math questions. Relying solely on human experts is both time-consuming and costly, while LLM-generated questions often lack the requisite diversity and difficulty. We present a design framework that combines the strengths of LLMs with a human-in-the-loop approach to generate a diverse array of challenging math questions. We leverage LLM metacognition skills [Didolkar et al., 2024] of a strong LLM to extract core skills from existing math datasets. These skills serve as the basis for generating novel and difficult questions by prompting the LLM with random pairs of core skills. The use of two different skills within each question makes finding such questions an out of distribution task for both LLMs and humans. Our pipeline employs LLMs to iteratively generate and refine questions and solutions through multiturn prompting. Human annotators then verify and further refine the questions, with their efficiency enhanced via further LLM interactions. Applying this pipeline on skills extracted from the MATH dataset [Hendrycks et al., 2021] resulted in MATH$^2$ - a dataset of higher-quality math questions, as evidenced by: (a) Lower performance of all models on MATH$^2$ than on MATH (b) Higher performance on MATH when using MATH$^2$ questions as in-context examples. Although focused on mathematics, our methodology seems applicable to other domains requiring structured reasoning, and potentially as a component of scalable oversight. Also of interest is a striking relationship observed between models' performance on the new dataset: the success rate on MATH$^2$ is the square on MATH, suggesting that successfully solving the question in MATH$^2$ requires a nontrivial combination of two distinct math skills.
Read more9/4/2024