CHAMP: A Competition-level Dataset for Fine-Grained Analyses of LLMs' Mathematical Reasoning Capabilities

0

Sign in to get full access
Overview
- This paper introduces CHAMP, a new dataset designed to evaluate the mathematical reasoning capabilities of large language models (LLMs) in a fine-grained and competition-level manner.
- The dataset consists of over 10,000 challenging math problems across various difficulty levels and topics, including algebra, calculus, geometry, and more.
- The authors argue that CHAMP provides a more comprehensive and rigorous assessment of LLMs' mathematical abilities compared to existing benchmarks.
Plain English Explanation
The researchers have created a new dataset called CHAMP to better understand the mathematical reasoning capabilities of large language models (LLMs). LLMs are artificial intelligence systems that can process and generate human-like text, and they have shown impressive abilities in various tasks. However, their performance on challenging mathematical problems has not been thoroughly evaluated.
CHAMP is designed to fill this gap by providing a large collection of over 10,000 math problems that cover a wide range of difficulty levels and topics, such as algebra, calculus, and geometry. These problems are meant to be challenging, similar to the type of problems one might encounter in math competitions. By testing LLMs on CHAMP, the researchers hope to gain a more detailed understanding of the models' strengths, weaknesses, and limitations when it comes to mathematical reasoning.
This is important because mathematical reasoning is a crucial skill for many scientific and technological advancements. If LLMs are to be used in applications that require advanced mathematical capabilities, it's essential to have a reliable way to assess their performance. CHAMP provides a comprehensive and rigorous benchmark that can help researchers and developers better evaluate and improve the mathematical reasoning abilities of LLMs.
Technical Explanation
The paper describes the development of the CHAMP (Competition-level Harness for Assessing Mathematical Prowess) dataset, which is designed to evaluate the mathematical reasoning capabilities of large language models (LLMs) in a fine-grained and challenging manner.
The dataset consists of over 10,000 math problems across a wide range of difficulty levels and topics, including algebra, calculus, geometry, and more. These problems were carefully curated and sourced from various online math competitions and olympiads, ensuring that they are at a competition-level of difficulty.
To assess the LLMs' performance, the researchers developed a set of evaluation metrics that go beyond simple accuracy scores. These metrics measure the models' ability to correctly solve the problems, as well as their reasoning process, which is assessed through detailed step-by-step solutions.
The authors evaluated several state-of-the-art LLMs on the CHAMP dataset and found that while the models demonstrated impressive capabilities, they also had significant limitations in certain mathematical domains and problem types. These findings suggest that existing benchmarks may not be sufficient for a comprehensive evaluation of LLMs' mathematical reasoning abilities.
The CHAMP dataset is publicly available and can be used by other researchers and developers to further investigate the mathematical reasoning capabilities of LLMs. The authors hope that CHAMP will serve as a valuable tool for advancing the field of mathematical AI and driving progress towards more capable and reliable systems.
Critical Analysis
The CHAMP dataset represents a significant advancement in the evaluation of LLMs' mathematical reasoning capabilities. By providing a large and diverse set of challenging math problems, the researchers have created a more comprehensive and rigorous benchmark compared to existing datasets.
However, it's important to note that the dataset is not without its limitations. The problems in CHAMP are primarily focused on traditional academic math topics, which may not fully capture the range of mathematical reasoning skills required in real-world applications. Additionally, the dataset may not account for the potential biases and limitations of the sources from which the problems were curated.
Furthermore, while the authors have developed a detailed set of evaluation metrics, the interpretation and generalization of these metrics to other domains or applications may be challenging. It's essential to consider the context and limitations of the CHAMP dataset when drawing conclusions about the mathematical reasoning capabilities of LLMs.
As the field of mathematical AI continues to evolve, it will be important for researchers to explore a wider range of mathematical reasoning tasks and applications, potentially incorporating more diverse and interdisciplinary problem sets. Additionally, further research is needed to understand the underlying cognitive processes and knowledge representations that enable effective mathematical reasoning in LLMs.
Conclusion
The CHAMP dataset represents a significant step forward in the evaluation of LLMs' mathematical reasoning capabilities. By providing a large and diverse set of challenging math problems, the researchers have created a more comprehensive and rigorous benchmark that can help advance the field of mathematical AI.
The findings from the CHAMP dataset suggest that while LLMs have made impressive progress in mathematical reasoning, they still have significant limitations. This highlights the need for continued research and development to create more capable and reliable systems that can effectively tackle complex mathematical problems.
The CHAMP dataset is a valuable resource for researchers and developers working in the field of mathematical AI. By using this dataset, they can gain a deeper understanding of the strengths and weaknesses of LLMs, and develop more effective strategies for improving their mathematical reasoning abilities.
Overall, the CHAMP dataset is an important contribution to the field of AI and has the potential to drive significant progress in the development of more capable and reliable mathematical reasoning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CHAMP: A Competition-level Dataset for Fine-Grained Analyses of LLMs' Mathematical Reasoning Capabilities
Yujun Mao, Yoon Kim, Yilun Zhou
Recent large language models (LLMs) have shown indications of mathematical reasoning ability on challenging competition-level problems, especially with self-generated verbalizations of intermediate reasoning steps (i.e., chain-of-thought prompting). However, current evaluations mainly focus on the end-to-end final answer correctness, and it is unclear whether LLMs can make use of helpful side information such as problem-specific hints. In this paper, we propose a challenging benchmark dataset for enabling such analyses. The Concept and Hint-Annotated Math Problems (CHAMP) consists of high school math competition problems, annotated with concepts, or general math facts, and hints, or problem-specific tricks. These annotations allow us to explore the effects of additional information, such as relevant hints, misleading concepts, or related problems. This benchmark is difficult, with the best model only scoring 58.1% in standard settings. With concepts and hints, performance sometimes improves, indicating that some models can make use of such side information. Furthermore, we annotate model-generated solutions for their correctness. Using this corpus, we find that models often arrive at the correct final answer through wrong reasoning steps. In addition, we test whether models are able to verify these solutions, and find that most models struggle.
Read more6/11/2024
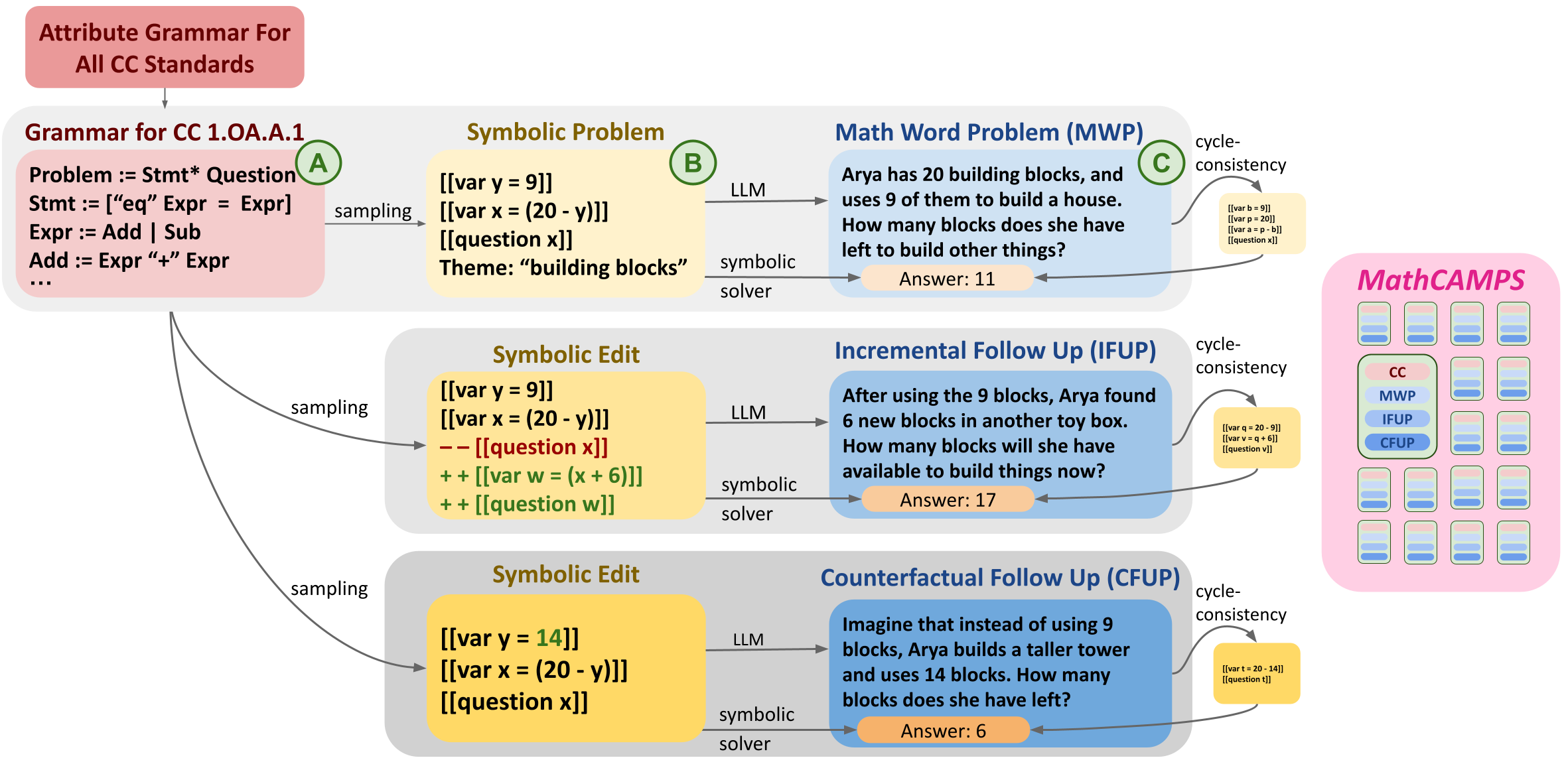
0
MathCAMPS: Fine-grained Synthesis of Mathematical Problems From Human Curricula
Shubhra Mishra, Gabriel Poesia, Belinda Mo, Noah D. Goodman
Mathematical problem solving is an important skill for Large Language Models (LLMs), both as an important capability and a proxy for a range of reasoning abilities. Existing benchmarks probe a diverse set of skills, but they yield aggregate accuracy metrics, obscuring specific abilities or weaknesses. Furthermore, they are difficult to extend with new problems, risking data contamination over time. To address these challenges, we propose MathCAMPS: a method to synthesize high-quality mathematical problems at scale, grounded on 44 fine-grained standards from the Mathematics Common Core (CC) Standard for K-8 grades. We encode each standard in a formal grammar, allowing us to sample diverse symbolic problems and their answers. We then use LLMs to realize the symbolic problems into word problems. We propose a cycle-consistency method for validating problem faithfulness. Finally, we derive follow-up questions from symbolic structures and convert them into follow-up word problems - a novel task of mathematical dialogue that probes for robustness in understanding. Experiments on 23 LLMs show surprising failures even in the strongest models (in particular when asked simple follow-up questions). Moreover, we evaluate training checkpoints of Pythia 12B on MathCAMPS, allowing us to analyze when particular mathematical skills develop during its training. Our framework enables the community to reproduce and extend our pipeline for a fraction of the typical cost of building new high-quality datasets.
Read more7/2/2024

0
Benchmarking Large Language Models for Math Reasoning Tasks
Kathrin Se{ss}ler, Yao Rong, Emek Gozluklu, Enkelejda Kasneci
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.
Read more8/21/2024
📉
0
Competition-Level Problems are Effective LLM Evaluators
Yiming Huang, Zhenghao Lin, Xiao Liu, Yeyun Gong, Shuai Lu, Fangyu Lei, Yaobo Liang, Yelong Shen, Chen Lin, Nan Duan, Weizhu Chen
Large language models (LLMs) have demonstrated impressive reasoning capabilities, yet there is ongoing debate about these abilities and the potential data contamination problem recently. This paper aims to evaluate the reasoning capacities of LLMs, specifically in solving recent competition-level programming problems in Codeforces, which are expert-crafted and unique, requiring deep understanding and robust reasoning skills. We first provide a comprehensive evaluation of GPT-4's peiceived zero-shot performance on this task, considering various aspects such as problems' release time, difficulties, and types of errors encountered. Surprisingly, the peiceived performance of GPT-4 has experienced a cliff like decline in problems after September 2021 consistently across all the difficulties and types of problems, which shows the potential data contamination, as well as the challenges for any existing LLM to solve unseen complex reasoning problems. We further explore various approaches such as fine-tuning, Chain-of-Thought prompting and problem description simplification, unfortunately none of them is able to consistently mitigate the challenges. Through our work, we emphasis the importance of this excellent data source for assessing the genuine reasoning capabilities of LLMs, and foster the development of LLMs with stronger reasoning abilities and better generalization in the future.
Read more6/5/2024