MathOdyssey: Benchmarking Mathematical Problem-Solving Skills in Large Language Models Using Odyssey Math Data
2406.18321
0
0

Abstract
Large language models (LLMs) have significantly advanced natural language understanding and demonstrated strong problem-solving abilities. Despite these successes, most LLMs still struggle with solving mathematical problems due to the intricate reasoning required. This paper investigates the mathematical problem-solving capabilities of LLMs using the newly developed MathOdyssey dataset. The dataset includes diverse mathematical problems at high school and university levels, created by experts from notable institutions to rigorously test LLMs in advanced problem-solving scenarios and cover a wider range of subject areas. By providing the MathOdyssey dataset as a resource to the AI community, we aim to contribute to the understanding and improvement of AI capabilities in complex mathematical problem-solving. We conduct benchmarking on open-source models, such as Llama-3 and DBRX-Instruct, and closed-source models from the GPT series and Gemini models. Our results indicate that while LLMs perform well on routine and moderately difficult tasks, they face significant challenges with Olympiad-level problems and complex university-level questions. Our analysis shows a narrowing performance gap between open-source and closed-source models, yet substantial challenges remain, particularly with the most demanding problems. This study highlights the ongoing need for research to enhance the mathematical reasoning of LLMs. The dataset, results, and code are publicly available.
Create account to get full access
Overview
- This paper introduces "MathOdyssey," a new benchmark for evaluating the mathematical problem-solving skills of large language models (LLMs).
- The benchmark is based on the Odyssey Math data, a diverse collection of math problems covering a wide range of difficulty levels and topics.
- The authors use MathOdyssey to assess the abilities of several state-of-the-art LLMs, providing insights into their mathematical reasoning capabilities.
Plain English Explanation
The paper discusses a new tool called "MathOdyssey" that is used to test how well large language models (LLMs) can solve math problems. LLMs are AI systems that are trained on massive amounts of text data and can generate human-like responses. The researchers wanted to see how well these LLMs can handle math problems, which often require logical reasoning and step-by-step problem-solving.
The MathOdyssey benchmark is based on the Odyssey Math data, which is a collection of math problems covering a wide range of topics and difficulty levels. By using this diverse set of math problems, the researchers can get a more comprehensive understanding of the LLMs' mathematical abilities.
The paper presents the results of testing several state-of-the-art LLMs on the MathOdyssey benchmark. This provides insights into the strengths and limitations of these models when it comes to mathematical reasoning and problem-solving. The findings could help guide the development of more capable and well-rounded AI systems in the future.
Technical Explanation
The paper introduces a new benchmark called "MathOdyssey" for evaluating the mathematical problem-solving skills of large language models (LLMs). The benchmark is based on the Odyssey Math data, a diverse collection of math problems covering a wide range of difficulty levels and topics.
The authors use MathOdyssey to assess the abilities of several state-of-the-art LLMs, including GPT-3, GPT-J, and OPT. The LLMs are tasked with solving the math problems in the MathOdyssey benchmark, and their performance is analyzed to provide insights into their mathematical reasoning capabilities.
The results show that while the LLMs exhibit some ability to solve math problems, they still struggle with more advanced and complex mathematical reasoning tasks. The paper discusses the implications of these findings and suggests areas for further research and development to improve the mathematical problem-solving skills of LLMs.
Critical Analysis
The paper provides a valuable contribution to the ongoing research on the mathematical capabilities of large language models (LLMs). The MathOdyssey benchmark offers a comprehensive and challenging test for evaluating the models' mathematical problem-solving skills, going beyond the more limited assessments used in previous studies.
However, the paper also acknowledges some limitations of the research. For example, the authors note that the LLMs may perform better on the MathOdyssey benchmark if they were given more time or additional context information. Additionally, the paper suggests that further research is needed to explore the specific types of mathematical reasoning that the LLMs struggle with and why.
One potential concern raised by the Caught in the Quicksand paper is the risk of over-optimism regarding the current capabilities of LLMs. While the MathOdyssey benchmark provides a valuable tool for assessment, it's important to maintain a critical and objective perspective on the limitations of these models, particularly when it comes to advanced cognitive tasks like mathematical reasoning.
Overall, the MathOdyssey paper offers an important contribution to the field, but it also highlights the need for continued research and a nuanced understanding of the strengths and weaknesses of large language models in the domain of mathematical problem-solving.
Conclusion
The MathOdyssey paper introduces a new benchmark for evaluating the mathematical problem-solving skills of large language models (LLMs). By using the diverse and challenging Odyssey Math data, the researchers are able to gain deeper insights into the capabilities and limitations of state-of-the-art LLMs when it comes to mathematical reasoning.
The findings suggest that while LLMs exhibit some ability to solve math problems, they still struggle with more advanced and complex mathematical tasks. This underscores the need for continued research and development to improve the mathematical problem-solving skills of these models, which could have significant implications for the development of more capable and well-rounded AI systems in the future.
The paper's introduction of the MathOdyssey benchmark and its analysis of LLM performance on this task represent an important step forward in our understanding of the mathematical capabilities of large language models. As the field of AI continues to evolve, tools like MathOdyssey will play a crucial role in driving progress and ensuring that the development of these models is grounded in a realistic assessment of their abilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
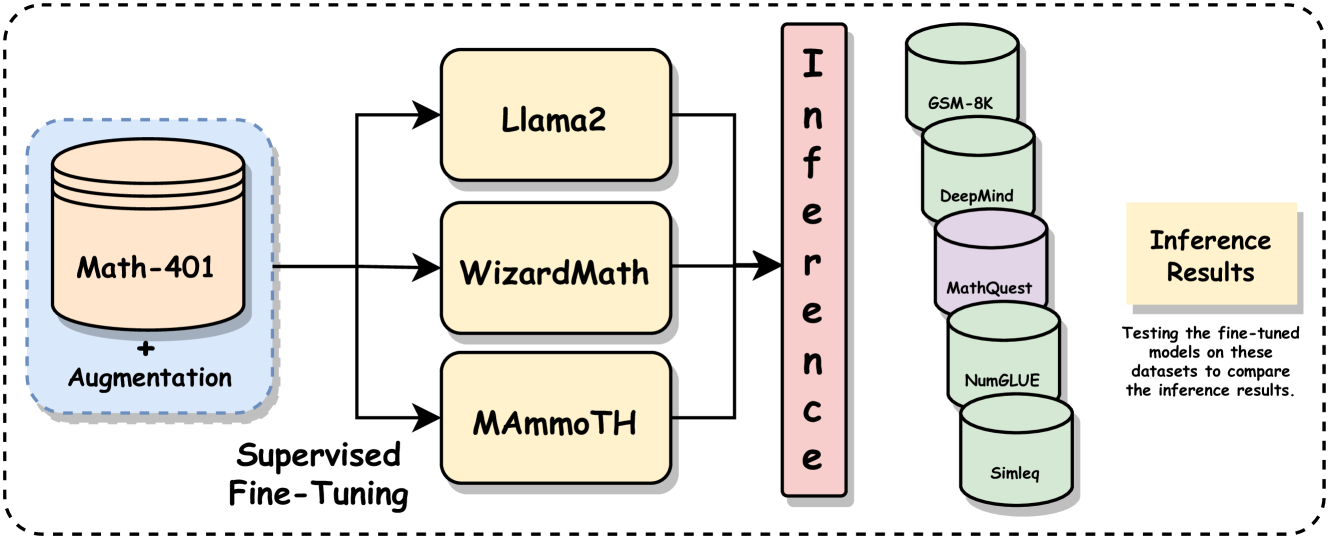
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024

Exploring Mathematical Extrapolation of Large Language Models with Synthetic Data
Haolong Li, Yu Ma, Yinqi Zhang, Chen Ye, Jie Chen
0
0
Large Language Models (LLMs) have shown excellent performance in language understanding, text generation, code synthesis, and many other tasks, while they still struggle in complex multi-step reasoning problems, such as mathematical reasoning. In this paper, through a newly proposed arithmetical puzzle problem, we show that the model can perform well on multi-step reasoning tasks via fine-tuning on high-quality synthetic data. Experimental results with the open-llama-3B model on three different test datasets show that not only the model can reach a zero-shot pass@1 at 0.44 on the in-domain dataset, it also demonstrates certain generalization capabilities on the out-of-domain datasets. Specifically, this paper has designed two out-of-domain datasets in the form of extending the numerical range and the composing components of the arithmetical puzzle problem separately. The fine-tuned models have shown encouraging performance on these two far more difficult tasks with the zero-shot pass@1 at 0.33 and 0.35, respectively.
6/5/2024

OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, Maosong Sun
0
0
Recent advancements have seen Large Language Models (LLMs) and Large Multimodal Models (LMMs) surpassing general human capabilities in various tasks, approaching the proficiency level of human experts across multiple domains. With traditional benchmarks becoming less challenging for these models, new rigorous challenges are essential to gauge their advanced abilities. In this work, we present OlympiadBench, an Olympiad-level bilingual multimodal scientific benchmark, featuring 8,476 problems from Olympiad-level mathematics and physics competitions, including the Chinese college entrance exam. Each problem is detailed with expert-level annotations for step-by-step reasoning. Evaluating top-tier models on OlympiadBench, we implement a comprehensive assessment methodology to accurately evaluate model responses. Notably, the best-performing model, GPT-4V, attains an average score of 17.97% on OlympiadBench, with a mere 10.74% in physics, highlighting the benchmark rigor and the intricacy of physical reasoning. Our analysis orienting GPT-4V points out prevalent issues with hallucinations, knowledge omissions, and logical fallacies. We hope that our challenging benchmark can serve as a valuable resource for helping future AGI research endeavors. The data and evaluation code are available at url{https://github.com/OpenBMB/OlympiadBench}
6/7/2024

Large Language Models for Mathematical Reasoning: Progresses and Challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin
0
0
Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
4/8/2024